One-Line Summary
A novel stacked LSTM architecture that passes both hidden states and cell states between layers via soft gating, enabling richer inter-layer information flow for improved sentence modeling across NLI, paraphrase detection, sentiment classification, and machine translation.
Background & Motivation
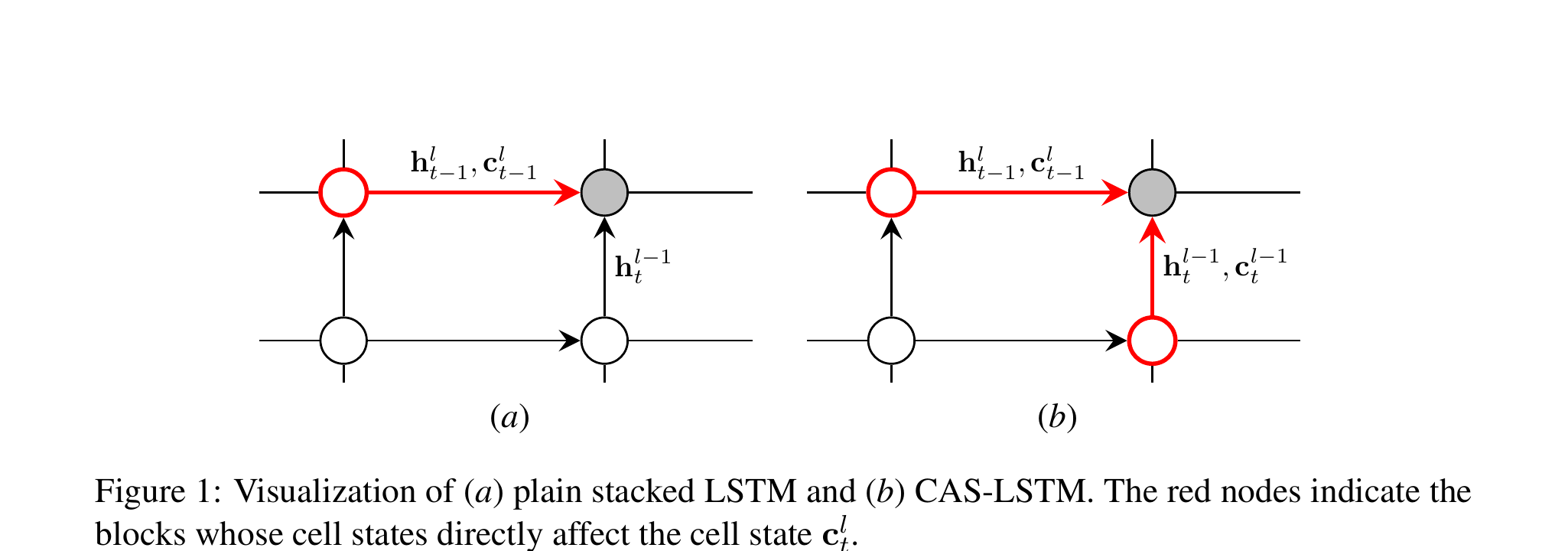
Long Short-Term Memory (LSTM) networks are the workhorses of sequence modeling, and stacking multiple LSTM layers has become a standard technique for building more powerful models. In a conventional stacked LSTM, each layer takes the hidden state sequence of the layer below as its input and produces a new hidden state sequence. This vertical composition allows the network to learn increasingly abstract representations at higher layers.
However, there is an asymmetry in how information flows in these architectures. Within a single layer, two types of state are maintained: the hidden state h (used as the layer's output) and the cell state c (the internal memory responsible for capturing long-range dependencies). When stacking layers, only the hidden state is passed upward — the cell state is kept entirely private to each layer. This means the rich, unfiltered memory accumulated in a lower layer's cell state is invisible to all layers above it, creating an information bottleneck at every layer boundary.
Key Insight: In standard stacked LSTMs, upper layers can only see the output-gated hidden states from lower layers, not their raw cell states. Since the output gate selectively filters what information is exposed, potentially useful long-term memory signals stored in lower-layer cell states are lost during vertical propagation. The Cell-aware Stacked LSTM (CAS-LSTM) addresses this by explicitly incorporating lower-layer cell states into upper-layer computations through a learned soft gating mechanism.
Prior approaches to improving multi-layer RNNs focused on residual connections or highway connections between layers, but these operate only on hidden states. The authors argue that cell states carry complementary information that is fundamentally different from hidden states, and that leveraging this information across layers can yield strictly better representations with minimal additional cost.
Proposed Method: Cell-aware Stacked LSTM (CAS-LSTM)
The core idea is to modify the standard stacked LSTM so that each layer receives both the hidden state and the cell state from the layer below, fusing the two sources of information via a soft gating mechanism before computing its own gates. The method introduces two key components:
Experimental Results
CAS-LSTM is evaluated on four major NLP tasks, comparing against standard stacked LSTMs and other competitive baselines. All experiments use the same hyperparameters and training procedures, differing only in the LSTM architecture.
Natural Language Inference (SNLI)
| Model | Test Accuracy (%) |
|---|---|
| 300D Stacked LSTM | 86.0 |
| 300D Gumbel TreeLSTM | 86.0 |
| 300D SPINN-PI | 86.6 |
| 300D CAS-LSTM (Ours) | 86.8 |
| 600D Stacked LSTM | 86.6 |
| 600D Residual Stacked LSTM | 86.4 |
| 600D CAS-LSTM (Ours) | 87.1 |
Paraphrase Detection (Quora Question Pairs)
| Model | Test Accuracy (%) |
|---|---|
| Stacked LSTM | 86.5 |
| BiMPM | 88.2 |
| CAS-LSTM (Ours) | 87.2 |
Sentiment Classification (SST)
| Model | Fine-grained (%) | Binary (%) |
|---|---|---|
| Stacked LSTM | 50.3 | 87.8 |
| Tree-LSTM | 51.0 | 88.0 |
| CAS-LSTM (Ours) | 51.5 | 88.8 |
Machine Translation (WMT English-German)
| Model | BLEU |
|---|---|
| Standard LSTM Encoder | 24.6 |
| CAS-LSTM Encoder (Ours) | 25.2 |
- Consistent improvements across all tasks: CAS-LSTM outperforms standard stacked LSTMs on every benchmark evaluated, demonstrating that inter-layer cell state communication provides a universal benefit regardless of the downstream task.
- Competitive with structured models: On SNLI, CAS-LSTM (a sequential model) achieves results competitive with or better than tree-structured models like Gumbel TreeLSTM and SPINN, which require explicit syntactic structure.
- Benefits scale with depth: The performance gap between CAS-LSTM and standard stacked LSTMs widens as the number of layers increases, confirming that cell-aware connections are particularly valuable for deeper architectures where the information bottleneck is more severe.
- Qualitative analysis: Gate activation analysis reveals that the soft gating mechanism learns to selectively pass different amounts of cell-state information depending on the input, validating that the model leverages the additional information channel in a meaningful, non-trivial way.
Why It Matters
This work identifies and addresses a fundamental but often overlooked asymmetry in multi-layer LSTM design: hidden states flow freely between layers, but cell states — which carry crucial long-term memory — are siloed within each layer. By introducing a simple soft gating mechanism to share cell states across layers, CAS-LSTM achieves consistent improvements across diverse NLP tasks with minimal additional parameters.
The significance extends beyond the specific architecture. The paper demonstrates that careful attention to information flow in deep recurrent networks can yield meaningful gains without resorting to fundamentally different architectures (such as Transformers or tree-structured models). The drop-in nature of CAS-LSTM makes it immediately practical: any system using stacked LSTMs can benefit from this modification with no changes to the training pipeline. The approach also provides insights into what information is lost at layer boundaries in deep RNNs, contributing to our understanding of how to design better recurrent architectures.