One-Line Summary
Through two novel metrics -- Label-Correctness Sensitivity and Ground-truth Label Effect Ratio (GLER) -- this paper demonstrates that correct input-label mappings in demonstrations have a far greater impact on in-context learning than previously reported, with the effect modulated by prompt verbosity and model scale, overturning the influential claim by Min et al. (2022) that "ground-truth labels barely matter."
Background & Motivation
In-context learning (ICL) enables large language models to perform tasks by conditioning on a few input-label demonstrations, without any parameter updates. A surprising and influential finding by Min et al. (2022, "Rethinking the Role of Demonstrations") claimed that the correctness of labels in demonstrations barely matters -- models performed nearly as well even with randomly assigned labels. This counterintuitive result raised fundamental questions about what ICL actually learns from demonstrations and quickly became one of the most widely cited findings in the ICL literature.
The Core Puzzle This Paper Addresses:
- Counterintuitive prior finding: Min et al. (2022) reported that replacing ground-truth labels with random labels in ICL demonstrations had minimal effect on downstream performance, suggesting that demonstrations primarily serve as a formatting template rather than a source of input-label mappings.
- Limited experimental scope: The prior conclusion was drawn from a narrow set of models (mainly GPT-3 Davinci 175B), a small number of tasks, and specific verbose prompt templates -- raising questions about generalizability across broader settings.
- Lack of quantitative tools: No formal metrics existed to precisely measure and decompose the impact of label correctness on ICL performance, making rigorous comparison across different experimental settings difficult.
- Practical stakes: If labels truly do not matter, it would fundamentally change how practitioners construct demonstration sets for real-world ICL applications -- potentially allowing the use of cheap, noisy labels without performance cost.
- Decomposition gap: ICL performance gains come from multiple factors -- input distribution, label space, demonstration format, and input-label mappings -- but no prior work cleanly isolated and quantified the contribution of each component.
Intrigued by this counterintuitive observation, the authors conduct an extensive re-examination using the GPT-3 family (Ada 350M, Babbage 1.3B, Curie 6.7B, Davinci 175B) and diverse classification benchmarks (SST-2, SST-5, MR, CR, AGNews, TREC, DBPedia, RTE, CB, and others). They introduce new quantitative metrics and reveal that ground-truth labels do matter significantly -- and that the prior conclusion was an artifact of specific, limited experimental configurations.
Proposed Method: Quantifying the Impact of Ground-Truth Labels
The paper introduces two novel metrics and conducts a systematic multi-factor analysis to quantify how much ground-truth labels contribute to ICL performance. The key insight is to decompose the overall ICL gain into distinct components -- format, label space, input distribution, and ground-truth label mapping -- and measure the relative contribution of each.
Experimental Results
The authors evaluate across the GPT-3 family (Ada 350M, Babbage 1.3B, Curie 6.7B, Davinci 175B) and a comprehensive set of text classification benchmarks covering sentiment analysis, topic classification, question classification, and natural language inference. The two proposed metrics reveal clear patterns that were obscured in prior work.
Models and Benchmarks
| Model | Parameters | Tasks Evaluated |
|---|---|---|
| GPT-3 Ada | 350M | SST-2, SST-5, MR, CR, AGNews, TREC, DBPedia, RTE, CB, and others (12+ tasks spanning binary to 14-class classification) |
| GPT-3 Babbage | 1.3B | |
| GPT-3 Curie | 6.7B | |
| GPT-3 Davinci | 175B |
Key Findings: Label-Correctness Sensitivity
| Factor | Low Sensitivity (labels seem unimportant) | High Sensitivity (labels clearly matter) |
|---|---|---|
| Prompt Verbosity | Verbose templates with detailed task descriptions | Minimal templates with no task instructions |
| Model Scale | Smaller models (Ada 350M, Babbage 1.3B) | Larger models (Curie 6.7B, Davinci 175B) |
| Task Complexity | Simple binary classification (e.g., SST-2, MR) | Fine-grained multi-class classification (e.g., AGNews, TREC, DBPedia) |
| Number of Demonstrations | Very few demonstrations (4-shot) | More demonstrations (16-32 shot) |
Ground-truth Label Effect Ratio (GLER) Analysis
| Experimental Configuration | GLER Trend | Interpretation |
|---|---|---|
| Minimal prompt + Davinci 175B | High GLER | Ground-truth labels contribute substantially to ICL performance; the model actively learns from correct mappings |
| Verbose prompt + Ada 350M | Low GLER | Other factors (formatting, task description in template) dominate; labels add little beyond what the template provides |
| Multi-class tasks (AGNews, TREC) | Higher GLER than binary tasks | More label options increase reliance on correct mappings since the label space cannot be inferred from format alone |
| Increasing demonstration count | GLER tends to increase | More examples amplify the learning signal from correct labels, compounding the benefit of accurate demonstrations |
| Min et al. (2022) setup | Low GLER | The specific combination of verbose prompts used by Min et al. artificially suppressed the ground-truth label effect |
Performance Decomposition: What Drives ICL Gains?
| Component | Minimal Prompt | Verbose Prompt |
|---|---|---|
| Format effect | Small contribution | Moderate contribution |
| Label space effect | Moderate contribution | Large contribution (template encodes label semantics) |
| Input distribution effect | Moderate contribution | Moderate contribution |
| Ground-truth label effect | Large contribution (dominant factor) | Small contribution (masked by template) |
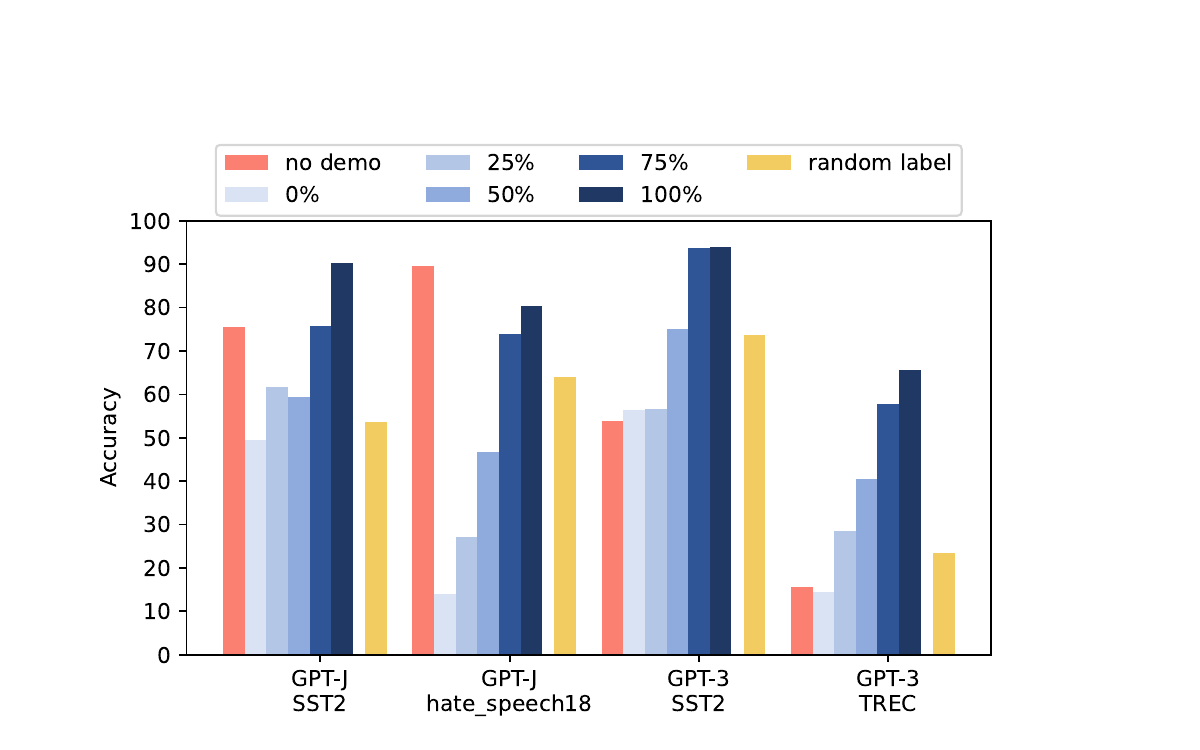
- Ground-truth labels do matter -- significantly: Across a broad range of configurations, correct input-label mappings yield substantial performance gains over random labels. On multi-class tasks with minimal prompts, the performance gap between correct and random labels can exceed 10-20 absolute points.
- Prompt verbosity is a key confound: Verbose prompt templates that include task descriptions effectively encode label information in the template itself, reducing the model's reliance on demonstration labels. This explains why Min et al. (2022), who used verbose templates, found labels to be unimportant -- the template was already "telling" the model what each label means.
- Larger models leverage labels more effectively: As model scale increases from Ada (350M) to Davinci (175B), models become significantly more sensitive to label correctness, extracting stronger learning signals from correct input-label mappings. Smaller models lack the capacity to fully utilize the information in correct demonstrations.
- Task granularity amplifies the effect: For fine-grained classification tasks with many classes (e.g., TREC with 6 classes, AGNews with 4 classes, DBPedia with 14 classes), the gap between correct and random labels widens considerably, as the label space becomes harder to infer from format alone.
- Performance degrades proportionally with noise: Systematically increasing the fraction of incorrect labels (0% to 100% random) leads to roughly proportional performance degradation, confirming that each correct demonstration provides a meaningful and additive learning signal.
- Prior conclusions were configuration-specific: The finding that "labels don't matter" holds only under a specific combination of verbose prompts and smaller models -- it does not generalize to the broader ICL landscape. When the experimental scope is broadened, the importance of ground-truth labels becomes unmistakable.
- GLER reveals hidden structure: The decomposition via GLER shows that in the settings studied by Min et al. (2022), the ground-truth label effect was genuinely small -- but not because labels are inherently unimportant; rather, because the verbose prompt template was already providing equivalent information through its task description.
Why It Matters
This work makes four important contributions to the understanding and practice of in-context learning:
- Corrects an influential misconception: The claim that ground-truth labels are unimportant for ICL had become widely accepted and cited across the NLP community. This paper provides rigorous evidence that correct demonstrations do teach models meaningful input-label mappings, restoring a key intuition about how ICL works and prompting the community to re-evaluate its assumptions.
- Introduces principled evaluation metrics: Label-Correctness Sensitivity and GLER provide the first formal, quantitative tools for measuring and decomposing the impact of demonstration quality on ICL. These metrics enable standardized comparison across future studies and have been adopted by subsequent work on ICL analysis.
- Offers actionable guidance for practitioners: The identification of prompt verbosity and model scale as key controlling factors gives practitioners clear design guidelines: when using larger models with minimal prompts, prioritizing label accuracy in demonstrations is especially critical for strong ICL performance. Conversely, when label noise is unavoidable, using more verbose templates can help compensate.
- Advances mechanistic understanding of ICL: The decomposition of ICL performance into format, label space, input distribution, and ground-truth label components provides a principled framework for understanding what models learn from demonstrations, contributing to the broader effort to demystify the mechanisms underlying in-context learning in large language models.