One-Line Summary
A chart-based constituency parse extraction (CPE) framework that induces non-trivial parse trees from multilingual pre-trained language models across 9 typologically diverse languages in a fully language-agnostic manner, identifying universal attention heads that are consistently sensitive to syntactic structure regardless of input language.
Background & Motivation
Recent work has shown that pre-trained language models (PLMs) like BERT encode rich syntactic information in their internal representations. One line of research focuses on constituency parse extraction (CPE) -- recovering hierarchical phrase structure from PLM representations without any supervised syntactic training. The core intuition is that words belonging to the same syntactic constituent should share similar internal representations, while constituent boundaries should exhibit representational discontinuities. However, prior CPE methods have been evaluated almost exclusively on English using the Penn Treebank, and rely on a greedy top-down algorithm that is inherently limited in its ability to assess whole-phrase plausibility.
Key Gaps in Prior Work:
- English-centric evaluation: Existing CPE methods (e.g., the syntactic distance approach of Hewitt & Manning, 2019; Kim et al., 2020) have been validated only on the Penn Treebank, leaving it unknown whether the syntactic structures they extract generalize across typologically different languages with varying word orders, morphological richness, and phrase structures.
- Top-down limitations: Prior approaches rely on syntactic distances between adjacent words and use a greedy top-down procedure, which only considers boundary information at each split step. This means the algorithm cannot evaluate whether all words within a candidate phrase actually cohere as a constituent -- it simply picks the largest boundary distance and recurses.
- Untapped multilingual PLMs: Models like mBERT (104 languages) and XLM-RoBERTa (100 languages) are trained on massive multilingual corpora, but their cross-lingual syntactic representations have not been systematically probed for constituency structure. These models offer a unique opportunity to test whether syntactic knowledge transfers across languages.
- Unknown universality: It remains an open question whether syntactic structure encoded in multilingual PLMs is language-specific (learned separately for each language) or reflects universal grammatical patterns shared across languages -- a question with deep implications for linguistic theory and practical cross-lingual NLP.
This paper addresses all four gaps by proposing a chart-based CPE framework that considers all words within a candidate phrase (not just boundaries), applying it to 9 languages across two multilingual PLMs to investigate the universality of encoded syntactic structure.
Proposed Method: Chart-Based Constituency Parse Extraction
The method formulates CPE as finding the minimum-cost parse tree, where costs are derived from syntactic distances computed from PLM representations. Unlike the greedy top-down approach that makes locally optimal splits, the chart-based method uses dynamic programming to consider all possible span decompositions simultaneously, yielding a globally optimal binary tree.

Experimental Results
The method is evaluated on 9 typologically diverse languages spanning different language families (Indo-European, Uralic, Language Isolate, Afro-Asiatic) and word orders (SVO, SOV, VSO, free). Treebanks include the Penn Treebank (English) and SPMRL shared task treebanks (Basque, French, German, Hebrew, Hungarian, Korean, Polish, Swedish). Multilingual models tested are mBERT and XLM-RoBERTa (XLM-R). Three CPE variants are compared: TD (top-down baseline), CP (chart-based with Pair Score), and CC (chart-based with Characteristic Score).
Monolingual English Results (Sentence-level F1)
| Model | TD | CP | CC |
|---|---|---|---|
| BERT-base | 37.0 | 38.5 | 39.0 |
| RoBERTa-base | 35.6 | 37.8 | 38.1 |
| XLNet-base | 40.1 | 42.3 | 41.8 |
| XLNet-large | 40.1 | 43.4 | 46.4 |
Comparison with Unsupervised Parsing Baselines (F1)
| Language | PRPN | ON-LSTM | C-PCFG | CPE-PLM (Ours) |
|---|---|---|---|---|
| English | -- | -- | -- | 46.4 |
| French | -- | -- | 40.5 | 42.4 |
| German | -- | -- | 37.3 | 39.6 |
| Korean | -- | -- | 27.7 | 47.3 |
| Swedish | -- | -- | 23.7 | 38.4 |
CPE-PLM results use the best monolingual PLM for each language with Top-K ensemble. The method substantially outperforms Compound PCFG (C-PCFG), especially on Korean (+19.6 F1) and Swedish (+14.7 F1), without requiring any language-specific parser training.
Multilingual Results with XLM-R (Sentence-level F1)
| Language | TD | CP | CC |
|---|---|---|---|
| English | 45.5 | 46.7 | 47.0 |
| Basque | 43.7 | 43.8 | 45.1 |
| French | 45.8 | 44.2 | 45.5 |
| German | 41.4 | 42.2 | 41.6 |
| Hebrew | 45.0 | 43.2 | 45.3 |
| Hungarian | 42.4 | 44.0 | 43.4 |
| Korean | 55.9 | 55.7 | 54.3 |
| Polish | 43.1 | 43.7 | 44.6 |
| Swedish | 39.5 | 40.6 | 41.5 |
- Chart-based methods outperform top-down: The proposed CP and CC methods improve over the TD baseline in most languages, with the ensemble boosting English XLNet-large from 40.1 to 46.4 F1 (a 6-point gain over prior work).
- Strong multilingual performance: XLM-R produces meaningful constituency trees across all 9 languages, with Korean achieving the highest F1 (55.9), substantially outperforming the C-PCFG unsupervised baseline (27.7 on Korean).
- XLM-R matches or exceeds monolingual PLMs: Remarkably, XLM-R achieves 47.7 F1 on English -- exceeding the monolingual BERT-base result (39.0) -- suggesting that multilingual pre-training does not dilute syntactic representations and may even enrich them through cross-lingual structural transfer.
Cross-Lingual Transfer & Universal Attention Heads
A key question is whether the optimal attention heads for CPE are language-specific or universal. To test this, the authors perform cross-lingual transfer experiments: selecting the top-K heads using only the English PTB validation set, then applying those same heads to all other languages.
Cross-Lingual Transfer Results:
- Using English-selected heads on other languages typically causes only 0-2 F1 point drops compared to language-specific head selection.
- In some cases, transfer actually improves performance: Basque improves from 45.1 to 46.2 F1, suggesting that English validation data can identify syntactically informative heads that generalize better than language-specific selection with smaller validation sets.
- Languages with smaller validation sets (Hebrew, Polish, Swedish) benefit most from cross-lingual transfer, as English provides a more reliable signal for head selection.
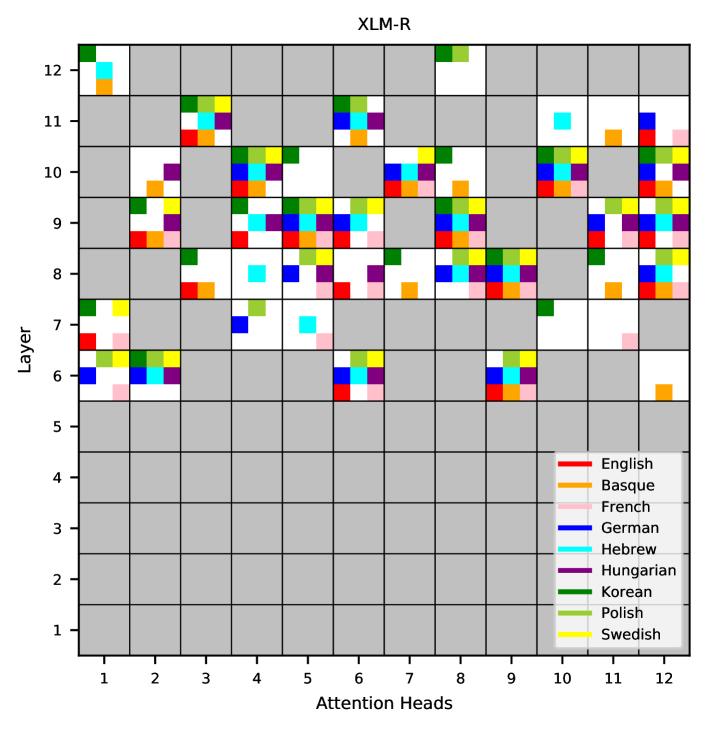
Visualizing the top-20 attention heads for each language in XLM-R reveals striking overlap: most heads that are syntactically sensitive for one language are also sensitive for others. These universal attention heads cluster in layers 6-12 (middle-to-upper layers), consistent with prior findings that lower layers encode surface-level features while upper layers encode more abstract, structural information.
Phrase-Type Analysis
Breaking down performance by phrase type reveals an interesting asymmetry:
- Noun phrases (NPs) recovered well: CPE-PLM achieves over 50% recall for NP identification across all 9 languages, substantially outperforming random baselines. NPs tend to be shorter, more locally bounded constituents that are easier to identify from attention patterns.
- Verb phrases (VPs) are harder: VP recovery rates are notably lower. VPs are generally longer and more structurally complex, often spanning much of the sentence. The authors note that "CPE-PLM seems relatively weak in recognizing VPs," suggesting that attention-based representations more easily capture local phrase coherence than global sentential structure.
- No correlation with pre-training data volume: Due to XLM-R's balanced sampling strategy across languages, there is no clear relationship between the amount of pre-training data for a language and its CPE performance. This indicates that the quality and diversity of multilingual pre-training matters more than raw data volume for any single language.
Why It Matters
This work makes three contributions that advance our understanding of syntactic knowledge in multilingual PLMs:
- First systematic multilingual CPE evaluation: By extending constituency parse extraction from English to 9 typologically diverse languages spanning multiple language families and word orders, the paper establishes that PLMs encode hierarchical syntactic structure as a cross-lingual phenomenon, not just an English artifact. This has implications for linguistic theory -- it suggests that transformer models converge on shared structural representations even when trained on typologically distinct languages.
- Chart-based framework overcomes top-down limitations: The proposed chart-based method considers all words within a phrase (not just boundaries), consistently improving parse quality through global optimization. The Top-K ensemble strategy provides further orthogonal gains by leveraging distributed syntactic information across attention heads, together achieving a 6-point F1 improvement over prior work on English.
- Discovery of universal attention heads: The finding that certain attention heads are consistently sensitive to syntax across all 9 languages provides evidence for language-universal structural representations in multilingual PLMs. This explains why cross-lingual transfer of CPE configurations works with minimal performance loss, and connects to theoretical debates about universal grammar -- suggesting that statistical language models independently discover shared structural patterns across languages.
For low-resource languages that lack large treebanks, this approach offers a viable path to approximate syntactic analysis using only a multilingual PLM -- no language-specific parser training is needed. The dramatic improvements over C-PCFG on languages like Korean (+19.6 F1) and Swedish (+14.7 F1) are particularly promising for practical applications. The insights about universal attention heads also inform the broader study of how transformers represent grammar, and suggest that probing multilingual models for structural properties can reveal deep cross-lingual regularities.