One-Line Summary
A CNN-based word representation model that uses Korean syllables as the basic embedding unit, producing morphologically meaningful word vectors that are robust to out-of-vocabulary words and capture the agglutinative structure of Korean.
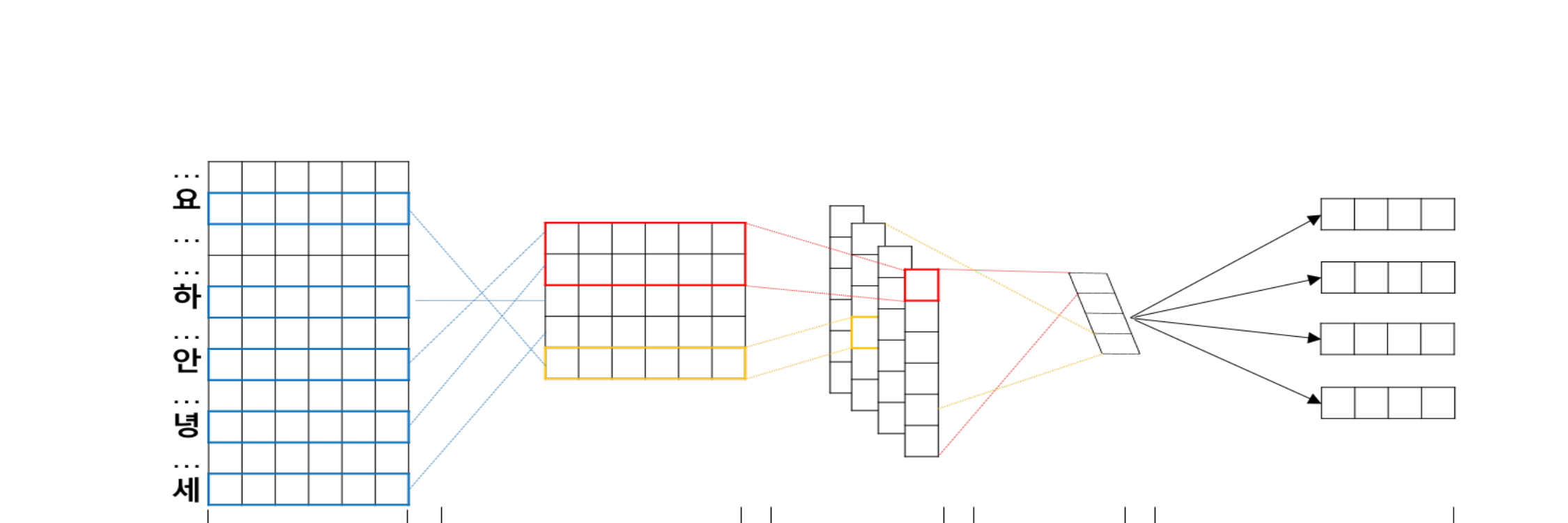
Background & Motivation
Word embeddings have become a foundational component in NLP tasks such as named entity recognition, machine translation, and sentiment analysis. Standard models like Word2Vec (Skip-gram, CBOW) and GloVe treat each word as an atomic unit, mapping it to a single vector. This works reasonably well for languages with limited morphological variation, but becomes problematic for morphologically rich and agglutinative languages like Korean.
The Korean Vocabulary Explosion Problem: In Korean, a single root morpheme can combine with approximately 60 different bound morphemes (postpositions, verb endings, honorifics, etc.), each producing a distinct surface form. For example, the noun "학교" (school) can appear as "학교가", "학교를", "학교에서", "학교에서의" and dozens more. Traditional word-level embeddings treat each of these as a completely separate vocabulary entry, leading to massive vocabularies, sparse training data per word, and frequent out-of-vocabulary (OOV) failures.
Prior subword approaches offer partial solutions but have significant drawbacks for Korean:
- Character-level (Jamo) models: Korean characters (ㄱ, ㅏ, ㄴ, etc.) are too fine-grained -- individual Jamo carry little semantic meaning on their own, making composition difficult and losing useful information.
- Morpheme-level models: Require a morphological analyzer as a preprocessing step, which introduces segmentation errors that propagate into the embeddings. Korean morphological analysis remains an imperfect and resource-intensive task.
- Syllable-level models (this work): Korean syllables occupy the sweet spot -- they naturally carry semantic meaning (e.g., "대학" = "大學", where "대" means "big/great" and "학" means "study/learning"), require no preprocessing tools, and words sharing syllables frequently share semantic content.
The key insight is that Korean Hangul syllable blocks are linguistically meaningful units that exist between the too-fine character level and the too-coarse word level. Moreover, the total number of distinct syllables in practical use is only around 1,000 -- orders of magnitude smaller than the word vocabulary -- making syllable-level representation both semantically rich and computationally efficient.
Proposed Method: Syllable-CNN
The model constructs word representations by composing trained syllable vectors through a convolutional neural network. The architecture draws on insights from character-level CNN models (such as CharCNN by Kim et al., 2016) but adapts the approach to Korean's syllabic writing system:
Key Architectural Advantage: Because the word representation is computed from syllable vectors rather than stored as a fixed lookup, the model can generate embeddings for any word composed of known syllables -- including words never seen during training. This compositional property directly addresses the OOV problem that plagues word-level models in Korean.
Experimental Results
The model was evaluated on a Korean News corpus spanning 2012-2014, containing approximately 2.7 million tokens, an 11,000-word vocabulary, and only ~1,000 unique syllables. The word vector dimension was set to 320 (80 filters × 4 widths). The baseline is the standard Skip-gram model trained on the same corpus.
Word Similarity Evaluation
| Model | Pearson Correlation (WS353-Sim) |
|---|---|
| Skip-gram (baseline) | 0.583 |
| Syllable-CNN (proposed) | 0.634 |
On the Korean-translated WordSim-353 Similarity subset, Syllable-CNN achieves a +0.051 improvement in Pearson correlation over the Skip-gram baseline. This improvement is attributed to the model's ability to exploit shared syllables between semantically related words -- for example, "경제" (economy) and "경영" (management) share the syllable "경" (managing/governing), which the CNN captures through its compositional process.
OOV Robustness: Handling Unseen Words
A critical advantage of the syllable-based approach is its ability to produce meaningful embeddings for out-of-vocabulary words. The paper demonstrates this with neologisms and compound words absent from training data:
| OOV Query Word | Nearest Neighbors (Syllable-CNN) |
|---|---|
| 구글신 ("God Google") | 구글 (Google), and semantically related terms |
| 갤노트 ("Galaxy Note", abbreviated) | 갤럭시 (Galaxy), 노트 (Note), and related tech terms |
Because these OOV words share syllables with known words (e.g., "구글신" contains "구글" = Google), the CNN composes their syllable vectors into representations that are close to the expected semantic neighborhood. The standard Skip-gram model simply cannot produce vectors for these words at all.
Morphological Structure Analysis
- Parallel Cluster Formation: PCA visualization of word vectors reveals that Syllable-CNN forms discriminative parallel clusters between base nouns and their postposition-attached forms (e.g., "한국" vs. "한국이", "한국을", "한국에"). The consistent directional offset between base and inflected forms demonstrates that the model learns a systematic morphological transformation, not just memorized associations.
- Baseline Failure: The standard Skip-gram model fails to capture this morphological structure -- base words and their inflected forms are scattered without clear geometric relationships, confirming that word-level models treat each surface form independently.
- Parameter Efficiency: The syllable vocabulary (~1K entries) is over 10x smaller than the word vocabulary (~11K entries), meaning the model requires far fewer parameters to achieve equivalent or better coverage. This is especially advantageous for low-resource settings where training data is limited.
- No Preprocessing Required: Unlike morpheme-based models that depend on a morphological analyzer (introducing pipeline errors), the syllable-based approach works directly on raw text with simple syllable tokenization -- a deterministic, error-free process for Korean.
Why It Matters
This work pioneered the use of syllables as the fundamental unit for Korean word representation, offering a linguistically motivated alternative to both character-level and morpheme-level approaches. Its contributions extend in several directions:
- Practical Korean NLP foundation: By avoiding the need for morphological analyzers while naturally capturing Korean's agglutinative properties, the approach provides a robust, low-overhead building block for downstream Korean NLP tasks including NER, parsing, and machine translation.
- OOV problem mitigation: The compositional nature of the model means any word composed of known syllables can receive a meaningful embedding -- essential for handling the constant stream of neologisms, abbreviations, and compound words in Korean web text and social media.
- Subword representation insight: The paper demonstrates that the optimal subword granularity is language-dependent. While character-level approaches work well for alphabetic languages, Korean's unique syllable-block writing system (Hangul) offers a more semantically informative intermediate representation. This insight has influenced subsequent work on Korean language models.
- Efficient and scalable: With only ~1,000 syllable embeddings to learn versus 11,000+ word embeddings, the model is significantly more parameter-efficient, making it suitable for deployment in resource-constrained environments.