One-Line Summary
A method that enables large language models to generate their own in-context demonstrations conditioned on test inputs, eliminating dependence on external training data while significantly outperforming zero-shot learning and rivaling few-shot learning with gold samples across text classification tasks.
Background & Motivation
In-context learning (ICL) allows pre-trained language models to solve tasks by conditioning on a few input-label demonstration pairs without any parameter updates. This paradigm has proven remarkably effective, but it has a critical limitation: performance is highly sensitive to the quality, choice, and ordering of demonstrations, which are typically selected from external labeled datasets. Prior work has shown that different random selections of demonstrations can lead to accuracy swings of over 30 percentage points on the same task.
Moreover, the standard ICL setup assumes access to a labeled training set from which demonstrations are drawn. This assumption limits the applicability of ICL in realistic low-resource scenarios where such labeled data may not exist. Existing approaches to mitigate demonstration sensitivity—such as careful retrieval or selection strategies—still require a pool of labeled examples to select from.
Key Insight: Large auto-regressive language models already encode vast world knowledge and can generate fluent, coherent text. Can we leverage this generative capability to produce demonstrations on the fly, conditioned on the test input itself? This would simultaneously (1) eliminate the dependency on external training data and (2) create demonstrations that are semantically aligned with each test instance, potentially reducing variance.
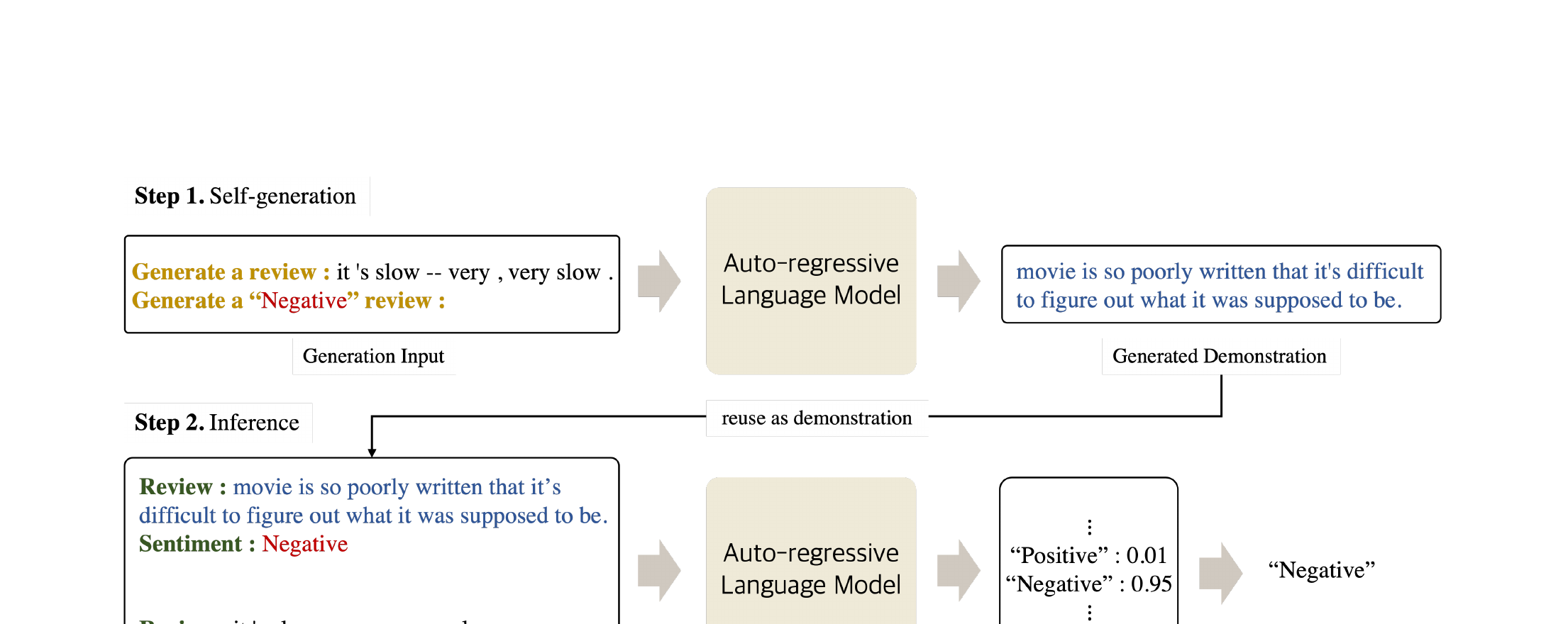
Proposed Method: SG-ICL
Self-Generated In-Context Learning (SG-ICL) leverages the auto-regressive generation capability of pre-trained language models to create their own demonstrations. The key idea is to condition the generation on both the test input and each candidate class label, producing demonstrations that are semantically correlated with the specific test instance. The method operates in two stages:
"[test input] is [label]. Similarly, [generated text]". By conditioning on both the input and the label, the model generates text that is topically relevant to the test instance while being associated with the given class. This is repeated for all classes, producing k × |C| total demonstrations (where |C| is the number of classes).A critical design choice is input-conditioned generation vs. class-only generation. When generating demonstrations conditioned only on the class label (without the test input), the resulting samples are generic examples of each class. By additionally conditioning on the test input, SG-ICL produces demonstrations with significantly higher semantic similarity to the test instance, which prior work has shown is a key factor for ICL success.
Experimental Results
Experiments are conducted on four text classification benchmarks using GPT-J (6B parameters) as the backbone model, with k = 4 self-generated samples per class (8 total for binary tasks, 20 for SST-5).
| Method | SST-2 | SST-5 | RTE | CB |
|---|---|---|---|---|
| Zero-shot | 67.4 | 30.8 | 50.2 | 32.1 |
| Gold ICL (k=1) | 77.9 | 33.3 | 52.8 | 41.1 |
| Gold ICL (k=4) | 87.7 | 38.2 | 53.3 | 46.4 |
| SG-ICL (k=4, ours) | 85.6 | 35.9 | 54.9 | 48.2 |
- Consistent Improvement over Zero-shot: SG-ICL significantly outperforms zero-shot learning across all four tasks—by up to +18.2pp on SST-2 and +16.1pp on CB—despite having no access to any training data
- Competitive with Gold ICL: SG-ICL matches or exceeds gold-sample ICL with 4 demonstrations on RTE and CB, and comes close on SST-2 and SST-5, demonstrating that self-generated samples are surprisingly effective substitutes
- Low Variance: SG-ICL achieves notably lower variance than gold ICL across random seeds. While gold ICL with random selection exhibits high standard deviation (e.g., ±8.1 on SST-2), SG-ICL is far more stable since every test instance receives deterministic, input-conditioned demonstrations
- Worth ~0.6 Gold Samples: Regression analysis reveals that each self-generated demonstration is worth approximately 0.6 gold training samples in terms of performance contribution. With 8 self-generated samples, SG-ICL outperforms few-shot learning using up to 5 gold samples
- Input Conditioning is Critical: Ablation comparing input-conditioned vs. class-only generation shows that conditioning on the test input is essential. Class-only generation produces demonstrations with lower semantic similarity to the test instance and yields substantially weaker performance, confirming that input-demonstration correlation is key to ICL effectiveness
- Semantic Similarity Analysis: Measuring cosine similarity between test inputs and generated demonstrations, input-conditioned generation achieves significantly higher similarity scores than class-only generation, validating the design motivation of SG-ICL
Why It Matters
SG-ICL opens a new paradigm where language models can bootstrap their own demonstrations without any external data. This has several significant implications:
- Data-Free ICL: Enables in-context learning in scenarios where labeled data is entirely unavailable, extending the applicability of ICL to truly zero-resource settings
- Stability: Provides a far more stable alternative to the notoriously variance-prone random demonstration selection in standard ICL, since demonstrations are deterministically generated for each test input
- Instance Adaptivity: Unlike standard ICL where the same demonstrations are used for all test inputs, SG-ICL creates instance-specific demonstrations, opening a new dimension of adaptive prompting
- Foundation for Future Work: This work laid the groundwork for subsequent research on self-generated demonstrations, influencing methods like Z-ICL, self-adaptive ICL, and other approaches that leverage model-generated content for in-context learning