One-Line Summary
A unified framework for idiomaticity detection that leverages four features computed at different levels of contextualization -- both inter-sentence and inner-sentence context -- to determine whether a multi-word expression (MWE) such as a two-noun compound is used idiomatically or literally, achieving strong cross-lingual generalization across English, Portuguese, and Galician.
Background & Motivation
Multi-word expressions (MWEs) are groups of linguistic components containing two or more words with outstanding collocation. They enrich the expressiveness of a language by allowing diverse interpretations depending on context. For instance, the expression wet blanket can be interpreted either compositionally ("a piece of cloth soaked in liquid") or idiomatically ("a person who spoils the mood"). Detecting whether an MWE is used idiomatically is a challenging NLP problem because the same expression can have different meanings depending on context, and most current NLP models are chiefly focused on capturing compositionality.
SemEval-2022 Task 2 focuses on classifying two-noun compounds into idiomatic and non-idiomatic usage under two configurations: a zero-shot setting where the model is evaluated on MWEs never seen during training, and a one-shot setting where the model is exposed to one idiomatic and one non-idiomatic example per MWE during training.
Key Challenge: Prior work (Tayyar Madabushi et al., 2021) showed that simply concatenating three sentences (previous, target, next) in order is generally unhelpful for idiomaticity detection. This naive approach approximately triples the input sequence length (~3x), making it harder for the encoder to distinguish the target sentence from its surrounding context, which can actually degrade performance. A more sophisticated approach to exploiting context is needed -- one that emphasizes the target sentence while still leveraging surrounding information.
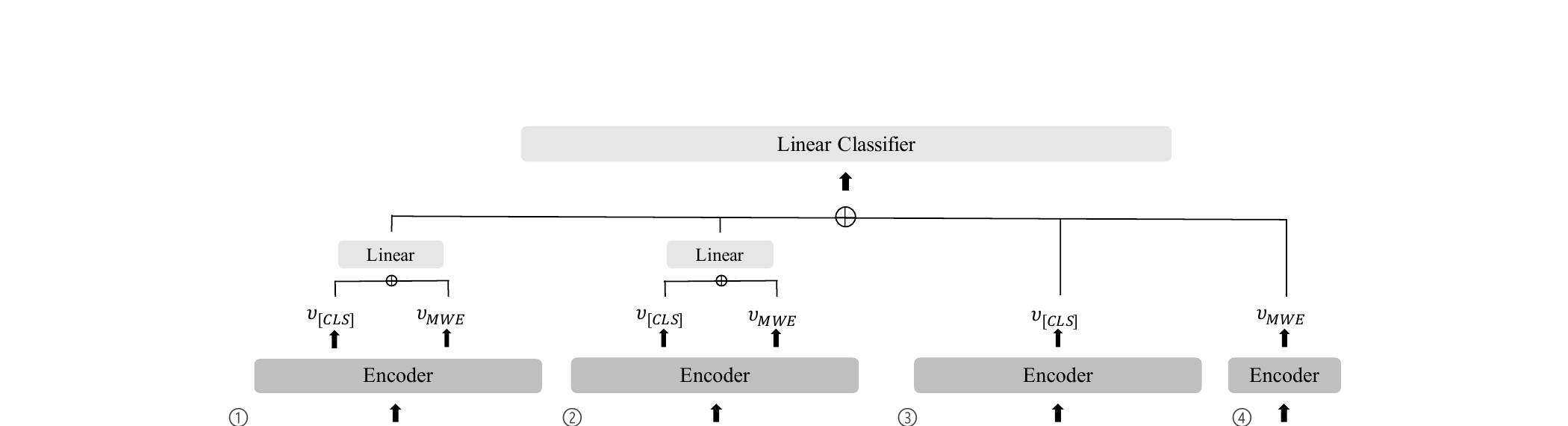
Proposed Method: Multi-Level Contextualization Framework
The framework computes four features from a Transformer encoder (XLM-RoBERTa base), each capturing different aspects of contextualization. Each feature is derived from a [CLS] embedding (v[CLS]) and an MWE embedding (vMWE, the average of subword representations constituting the target MWE) extracted from the encoder's last layer. The four features are concatenated and passed through a linear classifier for the final idiomatic/non-idiomatic prediction:
Design Insight: The MWE tokens from the target sentence (preserving inflectional form) are copied rather than using the original dictionary form. This preserves morphological consistency between the contextualized and isolated representations, which is important for fair comparison.
Experimental Results
Evaluated on SemEval-2022 Task 2 Subtask A (idiomaticity detection for two-noun compounds) across three languages: English, Portuguese, and Galician. Galician is not included in the training data, making it a true cross-lingual transfer test. The model uses XLM-R (base) with max sequence length 300, AdamW optimizer (lr=3e-5), batch size 16, trained for 10 epochs. Five instances per model are run with different random seeds, and the best checkpoint by dev macro F1 is selected.
| Model / Setting | English | Portuguese | Galician | Overall |
|---|---|---|---|---|
| Baseline (BERT) - Zero-shot | 70.70 | 68.03 | 50.65 | 65.40 |
| Baseline (XLM-R) - Zero-shot | 72.29 | 65.68 | 46.16 | 63.21 |
| Ours (submitted) - Zero-shot | 76.42 | 72.82 | 62.92 | 72.27 |
| Baseline (BERT) - One-shot | 88.62 | 86.37 | 81.62 | 86.46 |
| Baseline (XLM-R) - One-shot | 88.45 | 85.03 | 84.02 | 86.56 |
| Ours (submitted) - One-shot | 91.59 | 84.57 | 82.87 | 87.50 |
| Ours (post-eval) - One-shot | 92.29 | 88.05 | 87.10 | 89.96 |
The ablation study compared six variations: (A) no context, (B) naive three-sentence concatenation, (C) removing segment embeddings, (D) not repeating MWE at sequence tail, (E) recovering (unmasking) MWE in the context-exclusive feature, and (F) removing the MWE-exclusive feature:
- Strong Zero-shot Performance: Outperforms the XLM-R baseline by over 16 percentage points on Galician (an unseen language: 62.92 vs. 46.16), demonstrating strong cross-lingual generalization through the multi-level feature design
- Effective Context Splitting: Separating surrounding context into two chunks (previous+target, target+next) is consistently advantageous over both no-context (A) and naive three-sentence concatenation (B) across all experimental settings, confirming the hypothesis that emphasizing the target sentence while limiting input length is beneficial
- Stable Performance: The proposed approach shows much smaller score deviation across random seeds than baselines, suggesting that when a data instance lacks sufficient information in its target sentence, surrounding context can reliably complement the gap
- MWE-Exclusive Feature Matters Most in Zero-shot: Removing the MWE-exclusive representation (variation F) hurts zero-shot performance the most, likely because static representations for unseen MWEs become noisy, making the context-free semantic anchor critical
- Validation Set Issue in One-shot: The post-evaluation result (89.96 vs. 87.50) reveals that the validation set in the evaluation phase did not properly match the training set, causing suboptimal model selection. Simply choosing a model trained until epoch 9 (instead of the best by validation) yielded better test performance, highlighting the importance of proper validation set construction in shared tasks
Why It Matters
Understanding idiomatic language is essential for NLP systems to properly process figurative expressions, which are pervasive in everyday communication. This work makes several important contributions:
- Bridging Metaphor and Idiom Detection: By adapting metaphor identification theories (MIP and SPV) to the idiomaticity detection task, the paper demonstrates a productive cross-pollination between two related areas of figurative language processing
- Principled Context Exploitation: Rather than naively concatenating context, the carefully designed split-context strategy shows that how context is presented to the encoder matters as much as whether context is used at all
- Cross-lingual Robustness: The large improvement on Galician (a language absent from training) suggests that the multi-level features capture language-agnostic signals of idiomaticity, making the approach practical for low-resource languages
- Practical Insights for Shared Tasks: The detailed discussion of validation set issues and MWE form choices provides valuable guidance for future participants in similar shared tasks