One-Line Summary
An empirical study of two representative adaptive multi-agent systems (AFlow, AgentDropout) across six domains shows that learned topologies (i) fail to transfer out-of-distribution (topological overfitting) and (ii) often retain reasonable accuracy while the underlying collaboration has already collapsed (illusory coordination)—with role-related and connection-related breakdowns accounting for ~59% of failures under domain shift.
Background & Motivation
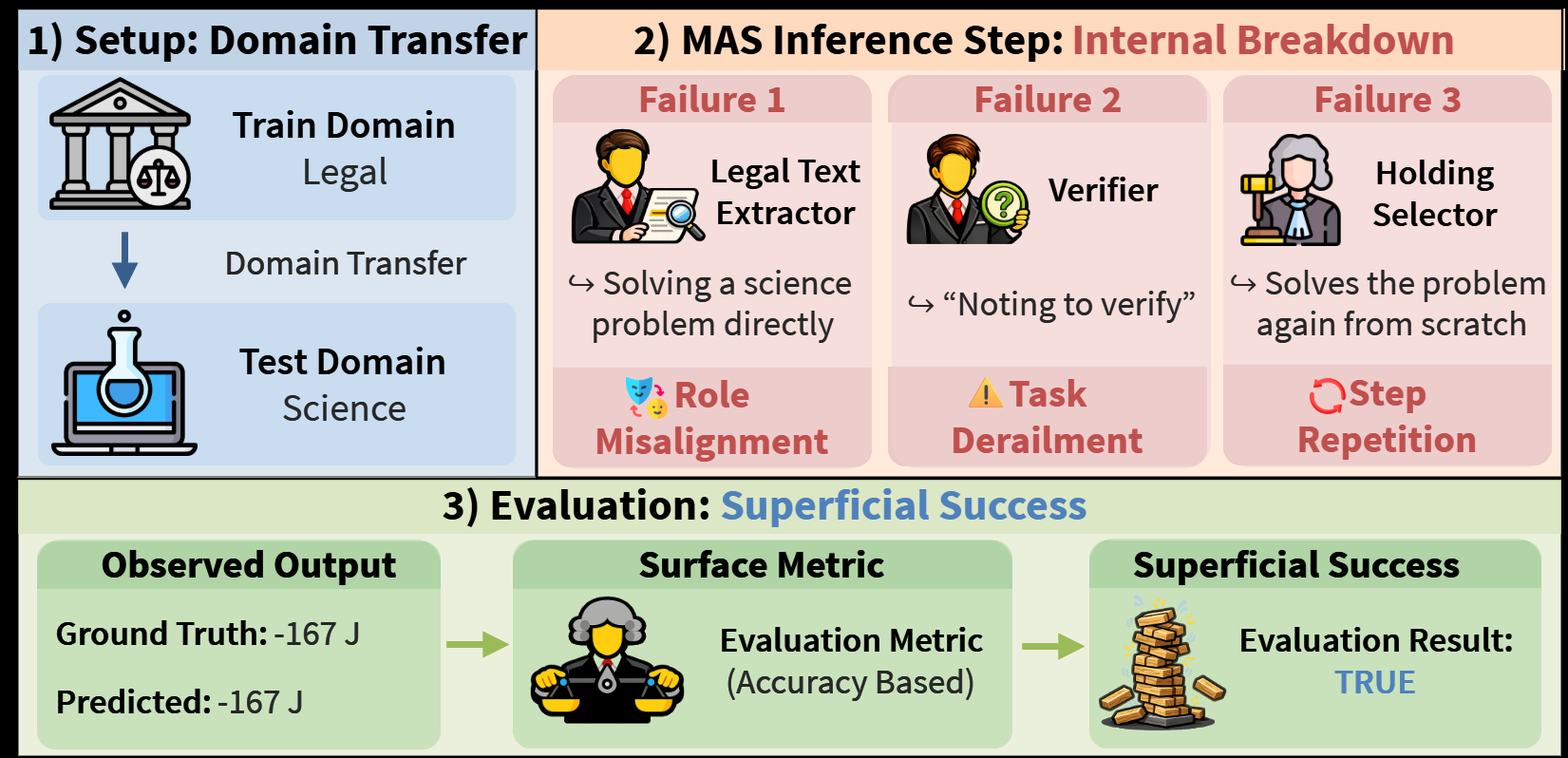
Adaptive multi-agent systems (MAS) optimize both the set of agents A (roles) and their connections C (communication topology) from data, much like supervised topology search. The appeal is obvious: plug in a strong base LLM, learn a task-specific collaboration graph, and enjoy the gains. The paradox is that these systems are built from general-purpose LLMs yet are routinely tuned on a narrow slice of tasks—so it is unclear whether they behave as general-purpose systems at all.
This is more than an academic concern. Constructing an adaptive MAS is expensive (multiple LLM calls, repeated search, orchestration overhead), and deploying a separate MAS per task defeats the original motivation. If adaptive MAS only work in-domain, they are effectively narrow solvers in disguise.
Central question: When an adaptive MAS transfers well across domains, is the transfer driven by genuine collective intelligence, or simply by the raw ability of the underlying LLM? The paper argues the latter is alarmingly common and proposes metrics that expose it.
Study Setup
Finding 1: Topological Overfitting
Single-domain MAS optimization produces topologies that are surprisingly brittle under distribution shift. AgentDropout trained on CaseHOLD (Legal) drops from 63.5% in-domain to an average of 55.78% across the five unseen domains, and AgentDropout trained on StrategyQA (Commonsense) cannot even produce valid outputs on most other domains (e.g., 0.6% / 0.5% / 0.1% / 15.7% on Legal / Detective / Science / Math) because topologies tuned for binary true/false answers fail to produce multiple-choice or numerical solutions.
AgentDropout on GPT-oss-20B — Train Domain (row) → Test Domain (col) Accuracy
| Train / Test | Legal | Detective | Multi-Hop | Science | Math | Commonsense |
|---|---|---|---|---|---|---|
| CaseHOLD (Legal) | 63.5 | 44.2 | 57.4 | 41.8 | 65.5 | 70.0 |
| COM2 (Detective) | 53.4 | 47.9 | 53.8 | 35.8 | 54.4 | 19.5 |
| MuSiQue (Multi-Hop) | 63.2 | 49.0 | 58.4 | 40.1 | 65.4 | 73.8 |
| SciBench (Science) | 61.8 | 34.2 | 54.9 | 38.9 | 62.8 | 47.5 |
| TheoremQA (Math) | 62.2 | 47.2 | 57.5 | 36.9 | 63.8 | 75.1 |
| StrategyQA (Commonsense) | 0.6 | 0.5 | 41.5 | 0.1 | 15.7 | 72.5 |
| Multi-Domain Training | 60.2 | 46.7 | 52.9 | 41.1 | 64.4 | 75.3 |
A simple mitigation—mixing training data across all six domains while holding the total instance budget constant—recovers most of the in-domain baselines and significantly stabilizes the worst cases, hinting that generalization failures are driven by narrow training scope rather than an intrinsic limit of adaptive MAS.
Finding 2: Illusory Coordination
Even where accuracy looks acceptable, the qualitative and quantitative analyses reveal that collaboration is often not the reason. Applying MAST to 100 execution logs, role- and connection-related failures (categories 1–6) make up roughly 59% of all errors under domain transfer.
Failure Distribution under Domain Transfer (MAST)
| Failure Type | Share |
|---|---|
| Disobey Role Specification | 15.22% |
| No or Incorrect Verification | 10.10% |
| Task Derailment | 8.97% |
| Disobey Task Specification | 8.94% |
| Step Repetition | 8.65% |
| Ignored Other Agent’s Input | 7.21% |
| Miscellaneous (8 other MAST cases) | 40.90% |
Representative case studies show the pattern vividly: a Legal Text Extractor attempting Carnot-efficiency physics (role misalignment), a Validator ignoring prior agent outputs and re-solving from scratch (input neglect), and an Answer Synthesizer replying “True” to a multiple-choice question (task violation).
Role Alignment (R) and Connection Significance (O) under Domain Transfer — AgentDropout
Each value is normalized per row by the row-wise maximum, so the diagonal (in-domain) entries equal 1.00. Low normalized values expose illusory coordination even when raw accuracy is deceptively reasonable.
| Train / Test | L (R / O) | D | MH | S | MA | CS |
|---|---|---|---|---|---|---|
| CaseHOLD (Legal) | 1.00 / 1.00 | 0.56 / 0.07 | 0.04 / −1.79 | 0.22 / −2.07 | 0.25 / −1.89 | 0.54 / −1.56 |
| COM2 (Detective) | 0.79 / 0.90 | 1.00 / 1.00 | 0.04 / 0.17 | 0.43 / 0.65 | 0.47 / 0.58 | 0.82 / 0.46 |
| MuSiQue (Multi-Hop) | 0.69 / 1.00 | 1.00 / 0.96 | 0.38 / 0.15 | 0.50 / 0.95 | 0.58 / 0.80 | 0.58 / 0.86 |
| SciBench (Science) | 0.44 / −0.75 | 0.49 / −0.50 | 0.04 / −0.57 | 1.00 / 1.00 | 0.62 / 0.77 | 0.46 / −0.07 |
| TheoremQA (Math) | 0.38 / −0.12 | 0.36 / 0.21 | 0.04 / −0.07 | 0.60 / 1.00 | 1.00 / 0.88 | 0.32 / 0.48 |
| StrategyQA (Commonsense) | 1.00 / 0.93 | 0.96 / 0.95 | 0.07 / 0.17 | 0.32 / 1.00 | 0.45 / 0.90 | 0.95 / 0.81 |
| Multi-Domain Training | 0.89 / 0.69 | 1.00 / 0.99 | 0.31 / −0.23 | 0.58 / 0.88 | 0.62 / 0.85 | 0.98 / 1.00 |
- Accuracy up, R collapsed: CaseHOLD → SciBench accuracy looks tolerable, but R falls to 22% of its in-domain value—the “success” does not come from role adherence.
- Accuracy down, R intact: COM2 → StrategyQA shows R at 82% of in-domain despite poor accuracy—confirming that accuracy and collaboration quality are largely dissociated.
- Influential but unhelpful messages: CaseHOLD-trained topologies produce strongly negative O under most transfers (down to −2.07 at SciBench), meaning messages drive outputs yet degrade them.
- Accuracy is a weak signal: Pearson correlations between accuracy and R / O are near-zero or mixed across all six benchmarks (|ρ| ≤ 0.12), formalizing that final-answer correctness is not a reliable proxy for coordination quality.
- Multi-domain training helps, but unevenly: It yields more stable positive O and higher R on most pairs, yet multi-hop transfer remains fragile.
Correlation and Ablation
A component-swap ablation isolates what exactly overfits. Role-OOD (keep in-domain connections, swap roles with OOD ones) drops accuracy by an average of −13.00 pp, while Connection-OOD (swap only connections) drops by only −1.24 pp—indicating that learned roles are substantially more task-specific than learned connections. A notable exception is MuSiQue (Multi-Hop), where Connection-OOD alone causes a 5.36 pp drop, showing that valid inter-agent links matter most when the task itself requires multi-hop integration.
| Benchmark | Acc – R (Pearson) | Acc – O (Pearson) | In-Domain | Connection-OOD | Role-OOD |
|---|---|---|---|---|---|
| CaseHOLD | −0.007 | 0.0002 | 63.50 | 62.88 (−0.62) | 48.26 (−15.24) |
| COM2 | −0.035** | 0.045*** | 47.90 | 50.68 (+2.78) | 34.50 (−13.40) |
| MuSiQue | 0.003 | 0.123*** | 58.40 | 53.04 (−5.36) | 48.44 (−9.96) |
| SciBench | 0.084*** | −0.039* | 38.90 | 38.69 (−0.21) | 30.29 (−8.61) |
| TheoremQA | 0.113*** | −0.081*** | 63.80 | 61.26 (−2.54) | 51.64 (−12.16) |
| StrategyQA | −0.096*** | 0.067** | 72.50 | 71.00 (−1.50) | 53.89 (−18.61) |
Why It Matters
The paper reframes what it means for an adaptive MAS to “work.” A system can post competitive numbers on a new benchmark while internally collapsing into a single strong LLM carrying the load, with other agents producing irrelevant or actively misleading messages. Benchmarks that reward only final-answer accuracy miss this, and the field’s current optimization objectives actively encourage it.
- Diagnosis, not dismissal. Illusory coordination is defined as a diagnostic regime (high accuracy, low R and/or low O)—the claim is not that collaboration is always fake, but that it is invisible unless measured.
- Two portable metrics. R and O are lightweight—sentence-embedding cosines plus a per-message LLM-as-judge—and can be added to any adaptive MAS evaluation pipeline.
- Design implication. Because roles are the dominant source of overfitting, future adaptive MAS may benefit from role regularization, multi-domain role libraries, or joint role–connection objectives that explicitly reward cross-domain transfer.
- Evaluation implication. The community should move beyond single-domain accuracy and pair it with internal-dynamics diagnostics; reporting only aggregate correctness can reward systems that do not actually coordinate.