One-Line Summary
TACT is a large-scale dataset (9,936 dialogues from SLURP + 7,109 from MultiWOZ) with structurally diverse mode transitions between task-oriented dialogue and chitchat, paired with novel Switch/Recovery metrics and a DPO-based training framework that achieves 75.74% joint mode-intent accuracy and a 70.1% human win rate against GPT-4o.
Background & Motivation
Conversational agents have traditionally been developed for either task-oriented dialogue (TOD) systems or open-ended chitchat, with limited progress in unifying the two. Yet real-world conversations naturally involve fluid transitions between these modes -- for example, a user booking a train ticket might casually mention enjoying scenic routes, then expect the agent to return to the booking task seamlessly.
Problem with Existing Datasets: Prior mode-switching datasets like FusedChat and InterfereChat allow only a single transition between TOD and chitchat (at most 1 switch point), and lack structural diversity. They adhere to a TOD-centric perspective, inserting chitchat at fixed points as single exchanges. This makes them unsuitable for modeling the dynamic, multi-turn transitions that occur in real conversations.
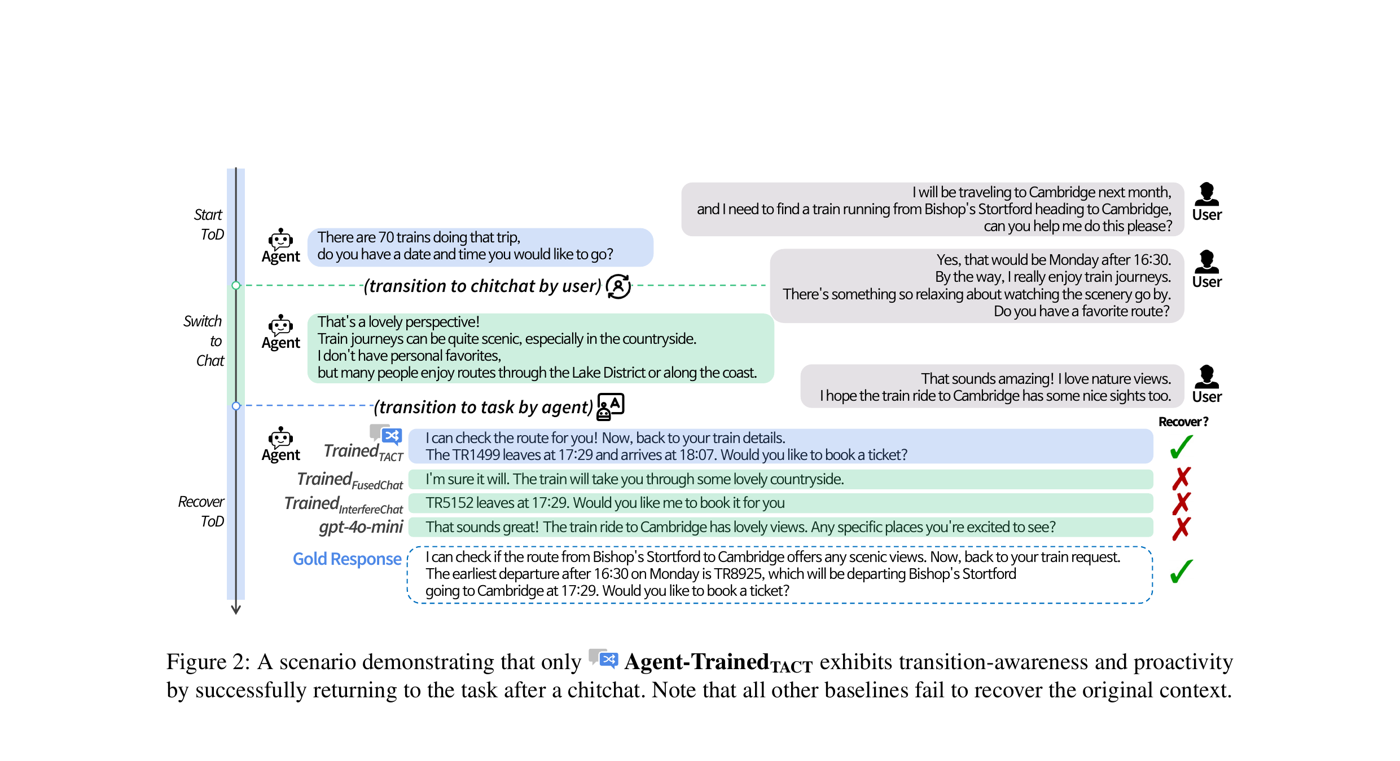
Two Missing Capabilities: Current systems lack (1) transition-awareness -- the ability to detect and adapt to mode changes, and (2) proactivity -- the ability to plan ahead and guide the conversation flow when appropriate. TACT is the first dataset that requires agents to both initiate and recover from mode transitions across multiple turns.
Proposed Method
Dataset Construction
TACT (TOD-And-Chitchat Transition) is built by augmenting two established TOD corpora -- MultiWOZ 2.2 and SLURP -- with structurally diverse chitchat transitions. Two core dialogue flow types are defined:
Dataset Statistics
| Statistic | TACTMultiWOZ | TACTSLURP |
|---|---|---|
| # Intents | 11 | 50+ |
| # Dialogues | 7,109 | 9,936 |
| # Avg. Turns | 15.04 | 16.42 |
| # Avg. Switch | 1.93 | 2.06 |
| # Avg. Recovery | 0.93 | 1.07 |
| # Unique Flow Types | 11 | 12 |
| Flow Patterns | TCT, CTC, TCTCT, etc. | |
Training Framework
Evaluation Metrics: Switch & Recovery
Experimental Results
All SFT models are initialized with LLaMA-3.1-8B-Instruct and trained for 3 epochs with a learning rate of 1e-5 and batch size of 256. Four methods are compared: ICL (zero-shot and few-shot with GPT-4o), SFT, SFT-DPO, and a generative-classifier-based Pipeline.
Method Comparison (Table 4)
| Method | Mode Sel. Acc. | Mode Sel. F1 | Intent Acc./turn | Joint Acc./turn | Joint Acc./dlg | Switch Att. | Switch Suc. | Recov. Att. | Recov. Suc. | Chitchat Win-Rate |
|---|---|---|---|---|---|---|---|---|---|---|
| ICL-ZS | 90.46 | 86.21 | 87.57 | 85.01 | 30.00 | 0.879 | 0.374 | 0.880 | 0.099 | - |
| ICL-FS | 91.45 | 88.98 | 84.09 | 86.89 | 36.76 | 1.577 | 0.865 | 1.571 | 0.652 | - |
| SFT | 98.95 | 98.50 | 96.35 | 96.41 | 75.59 | 1.322 | 1.300 | 0.977 | 0.856 | 23.16 |
| SFT-DPO | 98.82 | 98.32 | 96.03 | 96.21 | 75.74 | 1.343 | 1.322 | 0.977 | 0.859 | 40.86 |
| Pipeline | 98.95 | 98.50 | 96.35 | 96.41 | 75.59 | 1.322 | 1.300 | 0.977 | 0.856 | 24.32 |
Human Preference Evaluation (Figure 8)
Human annotators (10 evaluators) assessed DPO vs. GPT-4o (few-shot) on 77 dialogues without a tie option:
| Criterion | DPO Win % | DPO Lose % |
|---|---|---|
| Sensibleness | 71.4 | 28.6 |
| Specificity | 77.9 | 22.1 |
| Interestingness | 71.4 | 28.6 |
| Transition Naturalness | 81.9 | 18.2 |
| Overall | 70.1 | 14.3 |
Cross-Dataset Comparison (Table 3)
Only the TACT-trained agent achieves non-zero transition-aware scores. Models trained on FusedChat and InterfereChat produce zero switch and recovery attempts due to their lack of multi-turn transition structures:
| Training Set | Avg. Joint Acc./turn | Avg. Joint Acc./dlg | Switch Att. | Switch Suc. | Recov. Suc. |
|---|---|---|---|---|---|
| FusedChat | 92.25 | 56.13 | 0.000 | 0.000 | - |
| InterfereChat | 84.82 | 35.39 | 0.000 | 0.000 | - |
| TACTMultiWOZ | 92.11 | 58.60 | 1.322 | 1.300 | 0.856 |
- Only TACT enables transitions: Models trained on FusedChat and InterfereChat achieve zero switch/recovery attempts across all test sets, while the TACT-trained model consistently handles multi-turn transitions with 1.322 switch attempts and 0.977 recovery attempts per dialogue
- DPO doubles chitchat quality: SFT-DPO achieves a 40.86% chitchat win rate against GPT-4o, nearly doubling the SFT-only rate of 23.16%, while maintaining competitive TOD performance
- Transition Naturalness is the biggest gain: In human evaluation, DPO achieves 81.9% win rate on Transition Naturalness vs. GPT-4o, compared to SFT's 11.3% -- the largest improvement across all criteria
- DPO is the first to surpass GPT-4o on Transition Naturalness: With a win rate of 33.7% in LLM-based evaluation, DPO surpasses GPT-4o for the first time on this criterion, compared to SFT's 11.3%
- Recovery analysis: Only ~34% of successful recoveries return to the exact previous intent; the rest initiate a new but relevant intent in the correct mode, showing realistic recovery behavior
Why It Matters
Real-world deployed dialogue systems frequently encounter users who shift between task-oriented requests and casual conversation within a single session. TACT is the first dataset to model this conversational fluidity with structurally diverse, multi-turn transitions and recoverable dialogue structures. By combining TACT's diverse training data with preference optimization via DPO, the resulting agent learns soft conversational skills -- engagement, flow continuity, and transition smoothness -- that go beyond mere response accuracy. The open-source dataset (HuggingFace) and code (GitHub) pave the way for building more autonomous and predictive conversational agents.