한줄 요약
엔트로피 기반의 적응적 대조 디코딩 방법으로, RAG에서 LLM이 검색된 문맥에 의존하는 정도를 동적으로 조절하여, 노이즈가 있거나 무관한 문서가 검색되더라도 강건한 오픈 도메인 QA 성능을 달성합니다.
배경 및 동기
오픈 도메인 질의응답과 같은 지식 집약적 과제에서 LLM을 사용할 때, 검색 증강 생성(RAG)은 검색된 외부 문서를 문맥으로 제공하여 외부 지식과 모델의 파라메트릭 지식 간의 격차를 해소합니다. 그러나 실제 환경에서의 검색은 완벽하지 않으며, 검색된 문서는 종종 노이즈가 많거나, 무관하거나, 심지어 정답과 모순되는 경우가 있습니다. 모델이 이러한 저품질 문맥을 맹목적으로 조건화하면 생성 품질이 크게 저하됩니다.
최근의 대조적 디코딩 접근법(예: Context-Aware Decoding, CAD)은 문맥 유무에 따른 출력 분포를 대조하여 문맥적 지식을 파라메트릭 지식보다 증폭시키려 시도합니다. 관련 있는 문맥이 제공될 때는 효과적이지만, 이러한 방법들은 고정된 대조 가중치를 사용하기 때문에 노이즈가 있는 검색 시나리오에서 취약합니다. 또 다른 접근법인 Multi-Input Contrastive Decoding(MICD)은 최대 토큰 확률 기반의 동적 가중치를 도입하지만, 그 관련성 추정은 여전히 거친 수준에 머물러 신뢰성이 부족합니다.
고정 대조 디코딩의 한계: CAD와 같은 방법은 문맥의 영향을 억제하거나 증폭하기 위해 일정한 가중치(α = 0.5)를 적용합니다. 이는 근본적으로 최적이 아닙니다: 검색된 문맥이 실제로 유용할 때는 과도하게 보정하여 성능을 저하시키고(예: Llama2-7B에서 TriviaQA가 60.23에서 49.02로 하락), 문맥이 노이즈가 많거나 오해의 소지가 있을 때는 보정이 부족하여 유해한 영향을 충분히 억제하지 못합니다. MICD-F 역시 고정 α = 1.0을 사용하여 문맥 품질과 무관하게 문맥을 과도하게 증폭합니다.
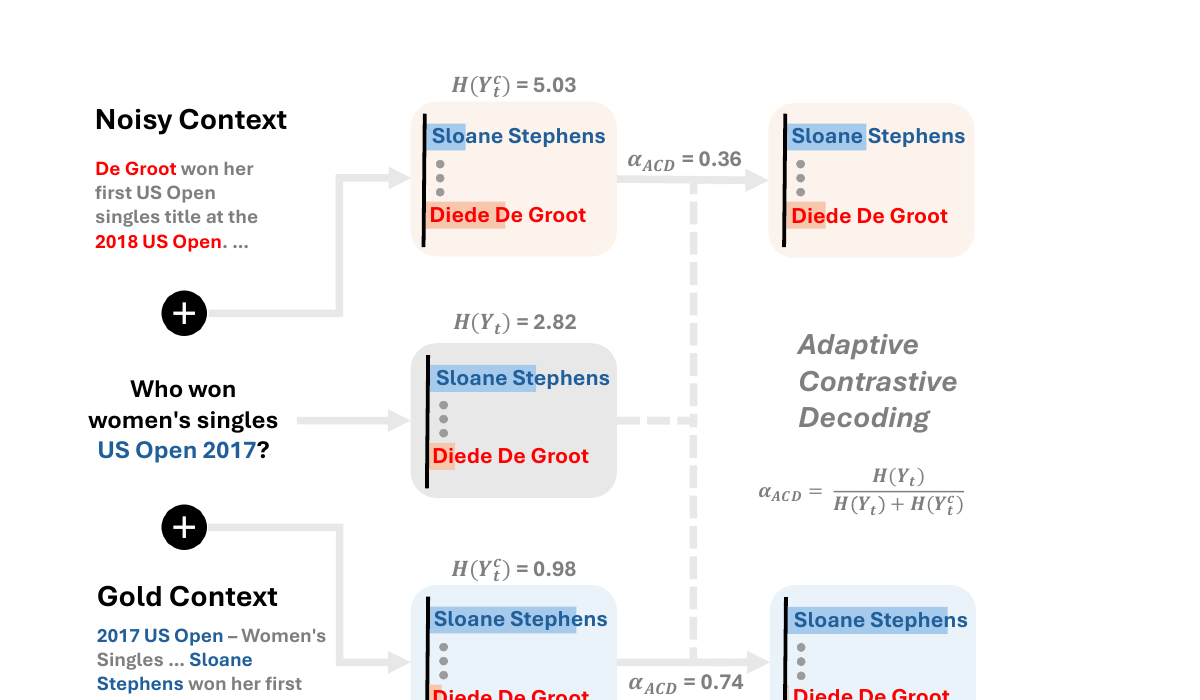
핵심 통찰: 최적의 디코딩 전략은 검색된 문맥이 모델에 실제로 얼마나 도움이 되는지에 따라 동적으로 적응해야 합니다. 문맥 없는 출력 분포와 문맥이 포함된 출력 분포 사이의 엔트로피 변화를 측정함으로써, 모델 자체가 문맥이 불확실성을 줄이는지(유용) 아닌지(노이즈)를 신호할 수 있으며, 대조 가중치는 이에 따라 반응해야 합니다. MICD-D의 최대 확률 휴리스틱과 달리, 엔트로피는 출력 분포의 전체 형태를 포착하여 더 원리적이고 신뢰할 수 있는 관련성 신호를 제공합니다.
제안 방법: 적응적 대조 디코딩 (ACD)
ACD는 표준 대조 디코딩을 엔트로피 기반의 적응적 가중치 메커니즘으로 확장합니다. 핵심 디코딩 수식은 다음과 같습니다:
디코딩 수식: P(Y_t | x, y_<t) = softmax( z_t + αACD · (z_tc - z_t) )
여기서 z_t는 문맥 없는 로짓, z_tc는 문맥이 포함된 로짓, αACD는 적응적 가중치입니다.
적응적 가중치: αACD = H(Y_t) / ( H(Y_t) + H(Y_tc) )
여기서 H(Y_t)는 문맥 없는 분포의 엔트로피, H(Y_tc)는 문맥이 포함된 분포의 엔트로피입니다.
직관은 간단합니다: 검색된 문맥이 모델의 불확실성을 줄일 때(H(Y_tc) < H(Y_t)), αACD는 1에 가까워져 문맥의 영향을 증폭시킵니다. 문맥이 혼란을 야기할 때(H(Y_tc) > H(Y_t)), αACD는 0을 향해 감소하여 문맥의 영향을 억제하고 파라메트릭 지식에 더 의존합니다. 두 엔트로피가 동일할 때는 αACD = 0.5로 중립적 균형을 유지합니다.
실험 설정
ACD는 Wikipedia(2018년 12월 덤프)를 검색 코퍼스로 사용하여 세 가지 오픈 도메인 QA 벤치마크에서 평가되었습니다:
- Natural Questions (NQ): 실제 Google 검색 쿼리에서 파생된 3,610개의 일반 상식 질문
- TriviaQA: 11,313개의 트리비아 스타일 사실 기반 질문
- PopQA: 14,262개의 롱테일(비인기) 지식에 초점을 맞춘 질문 -- 파라메트릭 지식만으로는 가장 어려운 벤치마크
검색에는 Contriever-msmarco를 사용하여 상위 1개 문서를 선택합니다. 네 가지 LLM(Llama2-7B, Llama2-13B, Llama3-8B, Mistral-7B)을 대상으로, 5-shot 프롬프팅과 Exact Match(EM) 평가 지표를 사용합니다. 강건성을 체계적으로 분석하기 위해 각 데이터셋을 다음과 같이 분할합니다:
- SubsetGold: 검색된 문서가 정답을 포함하는 샘플 (검색 성공)
- SubsetNoisy: 검색된 문서가 정답을 포함하지 않는 샘플 (검색 실패 -- 노이즈/무관한 문맥)
베이스라인: RegCls (closed-book, 문맥 없음), RegOpn / Standard RAG (open-book, 표준 그리디 디코딩), CAD (고정 α=0.5), MICD-F (고정 α=1.0), MICD-D (최대 토큰 확률 기반 동적 α).
실험 결과
Gold/Noisy 분할 포함 주요 결과 (Llama2-7B, EM 정확도)
| 방법 | TriviaQA | NQ | PopQA | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 전체 | Gold | Noisy | 전체 | Gold | Noisy | 전체 | Gold | Noisy | |
| Standard RAG | 60.23 | 87.40 | 33.50 | 31.39 | 61.31 | 12.40 | 38.49 | 81.21 | 7.77 |
| CAD (α=0.5) | 49.02 | 73.69 | 24.75 | 25.57 | 51.61 | 9.05 | 33.70 | 72.18 | 6.03 |
| MICD-F (α=1.0) | 60.36 | 85.72 | 35.39 | 29.45 | 56.10 | 12.54 | 35.73 | 74.25 | 8.03 |
| MICD-D | 63.23 | 86.03 | 40.79 | 30.36 | 52.18 | 16.52 | 39.01 | 77.39 | 11.42 |
| ACD (본 연구) | 64.85 | 88.01 | 42.06 | 32.91 | 56.60 | 17.88 | 41.29 | 82.77 | 11.46 |
ACD는 세 데이터셋 모두에서 최고의 전체 성능을 달성합니다. 특히 SubsetGold(검색 이점 보존)와 SubsetNoisy(노이즈 억제) 양쪽에서 동시에 우수한 성능을 보입니다. CAD는 고정 가중치로 인해 양쪽 부분 집합에서 모두 성능이 크게 저하됩니다 -- TriviaQA의 골드 문맥에서 87.40에서 73.69로 하락하여, 무차별적인 대조 증폭이 유용한 문맥에서 오히려 해로움을 보여줍니다.
모델 간 일반화 성능 (전체 데이터, EM 정확도)
| 모델 | 방법 | TriviaQA | NQ | PopQA |
|---|---|---|---|---|
| Llama2-13B | MICD-D | 66.52 | 34.38 | 41.65 |
| ACD | 67.37 | 36.12 | 43.35 | |
| Llama3-8B | MICD-D | 64.01 | 30.72 | 41.35 |
| ACD | 66.32 | 35.48 | 43.25 | |
| Mistral-7B | MICD-D | 66.97 | 33.24 | 39.87 |
| ACD | 67.82 | 35.37 | 41.47 |
ACD는 네 가지 모델 아키텍처 전반에서 일관되게 최강 베이스라인(MICD-D)을 능가하며, 특히 검색 노이즈가 가장 심한 NQ에서 큰 폭의 개선(Llama3-8B에서 +4.76)을 보입니다.
문맥 품질 판별 능력 (AUROC, Llama2-7B)
적응적 가중치가 실제 문맥 품질을 얼마나 잘 반영하는지 검증하기 위해, α 값이 골드 문맥과 노이즈 문맥을 얼마나 잘 분리하는지 AUROC로 측정합니다. 세 가지 집계 방식(최대, 평균, 첫 번째 토큰 α)을 비교합니다.
| 집계 방식 | 방법 | NQ | TriviaQA | PopQA |
|---|---|---|---|---|
| 최대 | MICD-D | 51.53 | 59.76 | 65.49 |
| ACD | 65.78 | 73.37 | 74.84 | |
| 평균 | MICD-D | 54.18 | 63.78 | 72.64 |
| ACD | 68.80 | 72.32 | 78.90 | |
| 첫 번째 토큰 | MICD-D | 53.92 | 62.95 | 68.81 |
| ACD | 73.27 | 80.45 | 80.08 |
ACD의 엔트로피 기반 α는 모든 설정에서 65-80%의 AUROC를 달성하여, MICD-D의 최대 확률 휴리스틱(51-73%)을 크게 능가합니다. 특히 첫 번째 토큰의 α가 가장 높은 판별력을 보여, 문맥에 대한 모델의 초기 반응만으로도 문서 품질에 대한 매우 유용한 정보를 얻을 수 있음을 시사합니다.
Oracle 상한과의 비교 (Llama2-7B)
Oracle은 골드 문맥에 α=1.0, 노이즈 문맥에 α=0.0을 설정하는 완벽한 관련성 추정기입니다:
| 데이터셋 | ACD | Oracle | 차이 |
|---|---|---|---|
| NQ | 32.91 | 35.35 | +2.44 |
| TriviaQA | 64.85 | 65.31 | +0.46 |
| PopQA | 41.29 | 44.10 | +2.81 |
ACD는 정답 레이블 없이도 Oracle 성능의 97-99%에 도달하여, 엔트로피가 실제 문맥 관련성의 탁월한 대리 지표임을 입증합니다.
심층 분석
절제 실험: 적응적 vs. 고정 α
고정 α 값을 0.0에서 1.0까지 변화시키며 성능을 비교하여, 동적 가중치 조절의 우월성을 확인합니다. α=0.0(파라메트릭 지식만 사용)에서는 전체 EM이 낮고, α가 증가할수록 골드 문맥 성능은 향상되지만 노이즈 문맥 성능은 악화됩니다. 어떤 고정 α도 두 부분 집합을 동시에 최적화할 수 없습니다. ACD의 적응적 α는 모든 고정 α를 전체 EM에서 1-3포인트 일관되게 능가하여, 토큰별 동적 조절이 필수적임을 검증합니다.
지식 충돌 시나리오 (NQ-swap)
특히 주목할 만한 분석은 NQ-swap 데이터셋(3,650개 샘플)을 사용합니다. 검색된 문서의 정답 부분을 같은 유형의 임의 엔티티로 대체하여, 문맥이 구조적으로는 관련 있지만 사실적으로는 틀린 시나리오를 만듭니다 -- 모델의 파라메트릭 지식과 직접적으로 충돌합니다.
핵심 발견: ACD는 NQ-swap에서 모델 전반에 걸쳐 60-75%의 EM을 달성하여, 조작된 문맥을 맹목적으로 따르는 Standard RAG(41-50%)를 크게 능가합니다. 중요하게도, 문맥을 과도하게 거부하는 경향이 있는 MICD-D보다도 우수합니다. ACD의 엔트로피 기반 메커니즘은 교체된 문맥이 모델의 불확실성을 증가시킨다는 것을 정확히 감지하여(주입된 엔티티가 파라메트릭 지식과 충돌하므로), 낮은 α를 부여하고 내부 지식에 적절히 의존합니다.
사례 연구: 엔트로피의 실제 작동
두 가지 대표적인 예시가 ACD의 엔트로피 기반 가중치가 실제로 어떻게 작동하는지 보여줍니다:
Known-Noisy 예시: "라이온 킹에서 날라 목소리는 누가 했나요?"
모델이 이미 정답(Moira Kelly)을 알고 있어 엔트로피가 낮습니다: H(Y_t) = 2.92. 노이즈 문서가 Whoopi Goldberg를 제시하자, 문맥 포함 엔트로피가 급등합니다: H(Y_tc) = 5.46. 결과적으로 αACD = 0.35 (낮음)으로, 오해의 소지가 있는 문맥을 올바르게 억제합니다. ACD는 "Moira Kelly"로 정답을 출력합니다.
Unknown-Gold 예시: "Law and Order에서 Ben Stone 역을 누가 맡았나요?"
모델이 불확실하여(Michael Tucker로 추측) 엔트로피가 높습니다: H(Y_t) = 6.67. 골드 문서에서 Michael Moriarty를 언급하자, 불확실성이 급격히 감소합니다: H(Y_tc) = 1.56. 결과적으로 αACD = 0.81 (높음)로, 유용한 문맥을 올바르게 증폭합니다. ACD는 "Michael Moriarty"로 정답을 출력합니다.
이 사례들은 핵심 메커니즘을 보여줍니다: αACD는 별도의 관련성 분류기 없이, 문맥이 불확실성을 해소하는지 아니면 야기하는지를 자연스럽게 추적합니다.
한계점
- 계산 비용: ACD는 각 디코딩 단계에서 두 번의 순전파가 필요하여 추론 비용이 2배입니다(CAD와 동일). MICD(3배 비용)보다는 저렴하지만, 지연 시간에 민감한 배포 환경에서는 부담이 될 수 있습니다.
- 기본 모델에 한정: 실험은 기본 LLM(Llama2, Llama3, Mistral)에 초점을 맞춥니다. 인스트럭션 튜닝이나 RLHF로 정렬된 모델은 문맥 조건화 시 다른 토큰 분포를 보이며(예: "주어진 문맥에 따르면..."과 같은 지시를 따름), 이는 대조 메커니즘에 간섭할 수 있습니다.
- 단답형 QA에 한정: ACD는 짧은 답변의 사실 기반 QA 과제에서 평가됩니다. 장문 생성, 다단계 추론, 또는 부분적으로 관련 있는 문맥에 대한 성능은 미탐구 상태입니다.
실험 결과 요약
- 일관된 최고 성능: ACD는 세 가지 벤치마크와 네 가지 모델 아키텍처 전반에서 Standard RAG, CAD, MICD 변형을 포함한 모든 베이스라인을 능가
- 우수한 노이즈 강건성: SubsetNoisy 데이터에서 ACD는 최고 EM 점수를 달성(예: TriviaQA에서 42.06 vs. MICD-D의 40.79)하는 반면, CAD는 24.75로 심각하게 하락 -- closed-book 성능 이하
- 양질 검색의 이점 보존: SubsetGold에서 ACD는 Standard RAG를 유지하거나 능가(TriviaQA에서 88.01 vs. 87.40)하는 반면, CAD는 무차별적 문맥 감쇠로 73.69까지 하락
- 강력한 문맥 품질 판별: ACD는 세 가지 집계 방식에서 65-80%의 AUROC를 달성하여 골드와 노이즈 문맥을 구별, MICD-D의 51-73%를 크게 능가
- Oracle에 근접한 성능: ACD와 Oracle(문맥 품질에 대한 완벽한 정보를 사용) 간의 차이는 0.46-2.81포인트에 불과하여, 엔트로피 기반 관련성 추정의 효과성을 입증
- 지식 충돌에 강건: NQ-swap(사실 조작된 문맥)에서 ACD는 60-75% EM을 달성하여, 오해의 소지가 있는 문맥보다 파라메트릭 지식을 올바르게 우선시
- 추가 학습 불필요: ACD는 순수하게 디코딩 시점에 2배 추론 비용만으로 작동하므로, 기존 RAG 파이프라인에 플러그 앤 플레이 방식으로 적용 가능
의의
RAG 시스템은 점점 더 많은 실제 서비스에 배포되고 있지만, 검색 품질은 본질적으로 예측 불가능합니다. 완벽한 검색에서 잘 작동하는 시스템도 노이즈가 있는 결과에서는 치명적으로 실패할 수 있습니다. ACD는 네 가지 핵심 기여를 통해 이 근본적인 취약성을 해결합니다:
- 원리적인 적응 메커니즘: 정보 이론적 엔트로피에 대조 가중치를 기반함으로써, ACD는 문맥 영향을 조절하는 원리적이고 해석 가능한 방법을 제공합니다 -- 휴리스틱이나 고정 가중치 접근법과 달리. 엔트로피 비율은 문맥의 분포적 영향 전체를 자연스럽게 포착하여, 정답 레이블 없이도 Oracle에 근접한 관련성 추정을 달성합니다.
- 학습 불필요 강건성: ACD는 추가 학습, 미세 조정, 외부 모델이 필요 없습니다. 기존 대조 방법과 동일한 2배 추론 비용으로 순수하게 디코딩 시점에 작동하므로, 표준 디코딩의 드롭인 대체로서 기존 RAG 파이프라인에 즉시 적용 가능합니다.
- 실용적 신뢰성: Oracle에 근접한 성능(0.46-2.81포인트 차이)과 높은 AUROC 문맥 품질 판별 능력은 엔트로피 기반 신호가 문맥 관련성의 매우 효과적인 대리 지표임을 보여줍니다. 지식 충돌(NQ-swap)에 대한 강건성은 ACD가 적대적이거나 조작된 문맥도 처리할 수 있음을 추가로 입증하여, 검색 품질이 크게 변동하는 실제 배포 환경에서 더 신뢰할 수 있는 RAG 시스템을 위한 길을 열어줍니다.
- 일반화 가능한 설계: 네 가지 서로 다른 LLM 아키텍처(Llama2-7B/13B, Llama3-8B, Mistral-7B)와 세 가지 다양한 QA 벤치마크에서의 일관된 개선은, ACD의 엔트로피 기반 메커니즘이 특정 모델이나 데이터셋에 국한되지 않고 문맥 인식 생성의 일반적 원리를 포착함을 보여줍니다.