한줄 요약
각 트리 노드에서 구조 인식 태그 표현을 조건으로 합성 함수를 동적으로 변환하는 재귀 신경망 아키텍처(SATA Tree-LSTM)를 제안하여, 구문적으로 적응적인 문장 인코딩을 구현하고 감성 분석 및 자연어 추론 성능을 향상시킵니다.
배경 및 동기
재귀 신경망(RecNN)은 구문 분석 트리를 따라 단어 벡터를 상향식으로 합성하여 문장 표현을 구축합니다. 이러한 트리 구조 계산은 언어학적으로 동기가 부여되지만, 표준 RecNN은 관형어-명사 결합이든, 형용사-명사구 수식이든, 두 독립절의 병합이든 모든 노드에서 동일한 합성 함수를 적용합니다. 그러나 이 서로 다른 구문 구조는 근본적으로 다른 합성 연산을 요구합니다.
핵심 문제: 표준 Tree-LSTM은 구문 트리의 모든 노드에서 하나의 고정된 가중치 행렬 집합을 사용합니다. 즉, 다음과 같이 서로 다른 합성을 수행할 때도 동일한 변환을 적용합니다:
- NP + VP → S (주어-술어 병합)
- DT + NN → NP (관형어-명사 결합)
- JJ + NN → NP (형용사-명사 수식)
- VP + PP → VP (동사구와 전치사구 부착)
각 구문은 서로 다른 의미적 관계를 포함하지만, 모델은 모든 곳에서 동일한 변환을 적용합니다. 이러한 정적 합성성이 재귀 모델의 표현력을 제한합니다.
이 한계를 해결하려는 기존 시도들은 서로 다른 합성 행렬을 선택하기 위해 수작업 규칙에 의존하거나(예: MV-RNN), 과도하게 큰 파라미터 공간을 필요로 했습니다. 본 연구의 핵심 통찰은 구문 분석 트리에서 이미 제공되는 구성소 태그(constituency parse tags)가 합성 함수를 조건화하기 위한 자연스럽고 컴팩트한 신호를 제공하여, 파라미터 폭발 없이 각 노드의 구문적 역할에 적응하는 동적 합성을 가능하게 한다는 것입니다.
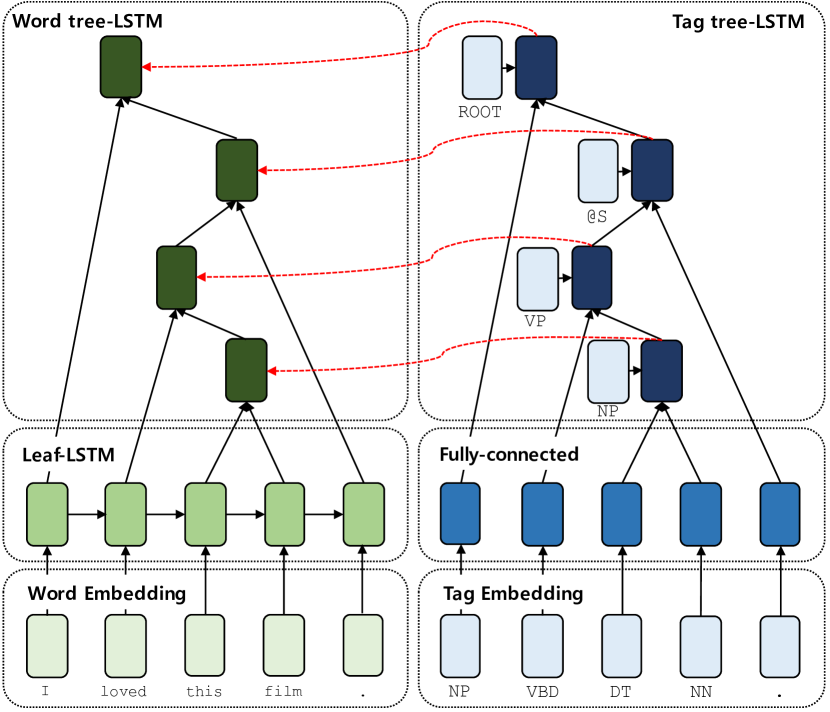
제안 방법: SATA Tree-LSTM
제안 모델인 SATA(Structure-Aware Tag Augmented) Tree-LSTM은 표준 단어 수준 Tree-LSTM과 병렬로 실행되는 태그 수준 재귀 네트워크를 도입합니다. 태그 표현은 각 트리 노드에서 합성 함수를 동적으로 조절하는 데 사용됩니다.
이 아키텍처는 범용적이며 모든 이진 분기 Tree-LSTM 또는 Tree-GRU 변형에 적용할 수 있습니다. 태그 임베딩과 파라미터 생성 네트워크의 추가만 필요하며, 일반적으로 전체 파라미터 수 대비 15% 미만의 증가만 발생합니다.
실험 결과
모델은 두 가지 주요 NLP 벤치마크에서 평가됩니다: 감성 분석을 위한 Stanford Sentiment Treebank(SST)와 자연어 추론을 위한 Stanford Natural Language Inference(SNLI). 두 과제 모두 높은 품질의 문장 표현을 요구하며 합성적 이해로부터 혜택을 받습니다.
감성 분석 (SST)
| 모델 | SST-5 (세분류) | SST-2 (이진 분류) |
|---|---|---|
| Tree-LSTM (기준선) | 51.0 | 88.0 |
| Tree-LSTM + 태그 임베딩 | 51.6 | 88.2 |
| SATA Tree-LSTM (제안) | 52.6 | 89.2 |
자연어 추론 (SNLI)
| 모델 | 테스트 정확도 (%) |
|---|---|
| Tree-LSTM (300D, 기준선) | 85.9 |
| SPINN | 86.6 |
| SATA Tree-LSTM (제안) | 87.2 |
- 일관된 성능 향상: SATA Tree-LSTM은 SST와 SNLI 모두에서 표준 Tree-LSTM 기준선을 능가하여, 구조 인식 동적 합성이 다양한 과제에서 더 높은 품질의 문장 임베딩을 생성함을 입증합니다.
- 태그 임베딩만으로는 불충분: 동적 가중치 생성 없이 태그 임베딩을 단어 임베딩에 단순 연결하는 것은 미미한 성능 향상만 가져옵니다. 이는 핵심 기여가 태그 특징 추가가 아닌 합성 함수의 동적 조절에 있음을 확인합니다.
- 구문 분석 품질에 강건: 골드 구성소 트리와 Stanford Parser의 자동 생성 구문 분석 모두에서 성능 향상이 유지되어, 실제 환경에서 구문 분석 오류에 대한 강건성을 보여줍니다.
- 동적 행동의 정성적 증거: 생성된 가중치 행렬의 시각화를 통해 모델이 서로 다른 구문 구성에 대해 구별되는 합성 패턴을 학습함을 확인합니다. 예를 들어, 형용사-명사 합성은 주어-동사 합성과 현저히 다른 가중치 패턴을 생성하여, 모델이 진정으로 구문 구조에 맞게 처리를 적응시킴을 확인합니다.
- 최소한의 파라미터 오버헤드: 태그 Tree-LSTM과 파라미터 생성 네트워크는 기본 모델 대비 상대적으로 적은 파라미터를 추가하여, 효율적이면서도 일관된 성능 향상을 달성합니다.
의의
본 연구는 언어학 이론과 신경망 설계 사이의 중요한 간극을 메우며, 재귀적 합성을 구문적으로 인식하게 만듭니다. 그 기여는 여러 방향으로 확장됩니다:
- 원칙적인 동적 합성: 수작업 규칙이나 거대한 파라미터 행렬(예: MV-RNN의 단어별 행렬)에 의존하던 기존 연구와 달리, SATA는 구문 트리에서 이미 사용 가능한 구문 태그를 활용하여 동적 합성을 위한 원칙적이고 파라미터 효율적인 메커니즘을 제공합니다.
- 언어학적 근거: 서로 다른 구문 구조가 서로 다른 의미 연산을 수반한다는 언어학적 직관을 구현합니다. 정성적 분석을 통해 모델이 언어학적 범주에 부합하는 의미 있는 합성 패턴을 발견함을 확인합니다.
- 범용 프레임워크: SATA 메커니즘은 특정 RecNN 변형이나 과제에 종속되지 않습니다. 모든 트리 구조 신경망에 적용 가능하여, 구문 인식 NLP 모델을 위한 범용적 개선 방법입니다.
- 후속 연구의 기반: 구조적 메타데이터에 기반하여 신경망 연산을 조건화하는 아이디어는 구조 인식 트랜스포머, 문법 인식 언어 모델, 구문 정보 활용 사전학습 목표 등 후속 연구에 영향을 미쳤습니다.