한줄 요약
세션을 넘나드는 개인화된 도구 호출(personalized tool calling)을 위해 265개 다중 세션 대화 / 2,020개 세션 규모의 MPT 벤치마크를 선호 재사용(Recall), 선호 귀납(Induction), 선호 전이(Transfer)의 세 가지 과제로 구성하고, 잠재 선호를 수정 가능한 가설로 다루는 생성–검증–수정(PRefine) 메모리를 제안합니다. PRefine은 전체 히스토리 대비 토큰의 1.24%만 사용하면서 도구 호출 정확도를 일관되게 향상시킵니다.
배경 및 동기
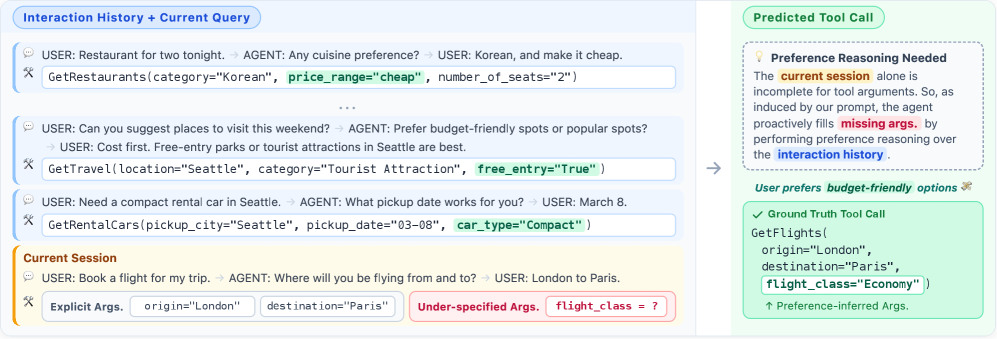
LLM 기반 에이전트는 점점 더 외부 도구에 의존하며, 도구는 대부분 완전히 지정된 인자를 요구합니다. 그러나 실제 사용자는 요청을 자주 불완전하게 표현하기 때문에, 누락된 값을 과거 상호작용으로부터 추론해야 합니다. 이는 단순히 유사한 과거 행동을 검색하는 문제를 넘어 암묵적이고 지속적인 제약을 추상화해 여러 맥락과 세션에서 일관되게 적용하는 문제입니다.
기존 개인화 연구는 대체로 사용자 선호가 정적인 프로필이나 명시적 지침으로 주어진다고 가정하거나, 좁은 도메인 내에서 반복되는 명시적 행동으로만 나타난다고 가정합니다. 그러나 현대적 에이전트는 다양한 작업 공간에서 사전 정의된 선호 스펙 없이 동작합니다. 대형 언어 모델은 유사한 과거 행동을 떠올리는 것은 잘하지만, 도메인을 가로지르는 규칙성을 일반화 가능한 선호 가설로 추상화하는 데는 약합니다.
동기 예시: 항공, 식당, 호텔에서 지속적으로 저가 옵션을 선택하는 사용자는 명시적으로 언급하지 않아도 “이코노미 여행 선호”라는 잠재 선호를 드러냅니다. 이 제약은 여러 세션과 도메인에 걸쳐 분산되어 있고, 누적된 증거가 쌓여야만 드러나며, 새로운 행동이 관찰되면 지속적으로 갱신되어야 합니다.
이로부터 두 가지 공개된 질문이 제기됩니다: (i) 이러한 잠재 선호를 어떻게 효율적으로 표현하고 유지할 수 있는가, 그리고 (ii) 그 선호가 도메인과 심지어 서로 다른 API 스키마 간에도 전이될 수 있는가?
제안 방법: PRefine
PRefine은 잠재 선호를 검색해야 할 정적 사실이 아니라 수정 가능한 선호 제약 가설로 취급합니다. 현재까지 관찰된 행동 규칙성의 가장 좋은 추상화 한 줄만 메모리에 유지하고, 새로운 세션이 생길 때마다 생성–검증–수정 루프로 갱신합니다.
예시로 보는 동작. 세션 1에서 GetMovies(average_rating=6)가 관찰되면, 초기 가설 “중간 평점 영화를 선호”는 지나치게 구체적이어서 기각되고, “영화에 대한 관심이 적음”으로 수정되어 메모리로 채택됩니다. 이후 세션에서 GetRentalCars(car_type=Standard), GetRestaurants(price_range=Cheap)이 관찰되면 생성기는 “도메인 전반에서 경제적이고 단순한 옵션을 선호”라는 도메인 횡단 추상화를 제안하고, 이는 검증을 통과하여 메모리로 유지된 뒤 이후 항공권 예약 등에서 접지됩니다.
MPT 벤치마크
MPT(Multi-Session Personalized Tool Calling)는 세션을 넘나드는 개인화 자체를 평가 대상으로 삼습니다. Schema-Guided Dialogue(SGD)에 다중 세션 그룹화와 수동 선호 어노테이션을 더해 구축되었습니다.
| 통계량 | 값 |
|---|---|
| 다중 세션 대화 수 | 265 |
| 전체 세션 수 | 2,020 |
| 전체 턴 수 | 39,884 |
| 대화당 평균 세션 수 | 7.6 |
| 세션당 평균 턴 수 | 19.7 |
MPT는 서로 다른 개인화 능력을 분리 평가하기 위한 세 가지 과제를 정의합니다.
flight_class=Economy를 반복 선택한 경우).각 인스턴스는 두 가지 쿼리 유형으로 평가됩니다. 문맥 포함(context-guided) 쿼리는 부분적인 명시 제약을 제공하는 세션 내 대화를 함께 포함하여 부분 지정 상황에서의 선호 기반 인자 완성 능력을 평가하고, 문맥 제거(context-free) 쿼리는 대화 맥락을 모두 제거하여 순수한 선호 모델링 능력만을 분리해 측정합니다. 선호는 58개의 API–인자 쌍을 상위 카테고리(예: 예산 — price_range=cheap, car_type=Compact, flight_class=Economy; 여행 인원 — passengers=1 vs. passengers=2-4)로 수동 그룹화하였으며, 19명의 인간 어노테이터가 예산 그룹 89.7%, 여행 그룹 97.4%의 일치도를 보였습니다.
실험 결과
총 8종의 추론 LLM(CodeGemma-7B, Gemma-3-12B, R1-Distill-Llama-8B, R1-Distill-Qwen-7B, GPT-4o-mini, GPT-5-mini, GPT-5, Gemini-3-Flash)을 4종의 메모리 베이스라인(RAG, Mem0, LangMem, PRefine)과 비교하였습니다.
문맥 포함 쿼리 — 베이스 프롬프팅 대비 평균 이득
| 과제 | Base P-EM | Base OA-F1 | PRefine ΔP-EM | PRefine ΔOA-F1 |
|---|---|---|---|---|
| Preference Recall | 33.51% | 54.94% | +13.11 | +11.99 |
| Preference Induction | 16.89% | 51.46% | +6.88 | +10.52 |
| Preference Transfer | 7.81% | 44.81% | +2.87 | +9.27 |
문맥 제거 쿼리 — 평균 F1 이득
| 과제 | Base F1 | PRefine ΔF1 |
|---|---|---|
| Preference Recall | 33.62% | +9.82 |
| Preference Induction | 13.41% | +5.20 |
| Preference Transfer | 22.25% | +3.38 |
메모리 설계 비교
| 방법 | 메모리 형태 | 갱신 방식 | 실행 가능성 | 잠재 선호 인지 |
|---|---|---|---|---|
| RAG | 원시 발화 | 정적 인덱스 | – | – |
| Mem0 | 추출된 사실 | 덧붙이기 / 덮어쓰기 | – | – |
| LangMem | 구조화된 사실 | LLM 재작성 | ✓ | – |
| PRefine | 잠재 제약 | 생성–검증–수정 | ✓ | ✓ |
- 관찰 vs. 추상화 격차: 베이스 프롬프팅은 문맥 제거 설정에서 Recall 53.19% F1을 달성하지만, Induction에서는 43.00%, Transfer에서는 16.26%로 급락합니다. 전체 히스토리를 접근할 수 있다 해도 자동으로 잠재 선호 추상화가 되는 것은 아니라는 점을 보여줍니다.
- 메모리 효율성: PRefine의 평균 메모리 크기는 대화당 23.28 토큰으로, 전체 히스토리 프롬프팅의 1.24%에 불과하며, 다른 메모리 기법 대비 약 80% 감소에 해당합니다. 세션이 10개까지 누적되어도 메모리 크기(20–25 토큰)가 거의 일정하게 유지됩니다.
- 인자 개수 보정: 예측 인자 수와 정답 인자 수의 평균 절대 편차가 문맥 포함 설정에서 0.77 → 0.56, 문맥 제거 설정에서 1.08 → 0.77로 약 28% 감소하여, 불필요한 인자와 누락된 인자가 모두 줄어듭니다.
- 동적 스키마 일반화: 슬롯 이름과 구조가 다른 낯선 API 도메인에서, GPT-5의 문맥 포함 P-EM이 3.75% → 47.00%, 문맥 제거 F1이 36.39% → 51.45%로 크게 향상되어, 스키마 독립적 메모리가 구조적으로 다른 도구 인터페이스에도 전이됨을 확인했습니다.
- 베이스라인은 무너지고 PRefine은 유지: RAG / Mem0 / LangMem은 Recall에서는 어느 정도 작동하지만 Induction과 Transfer에서 급격히 성능이 떨어지는 반면, PRefine의 이득은 세 과제에 걸쳐 상대적으로 일관됩니다.
- 예측 가능한 트레이드오프: 일부 보수적인 백본(R1-Distill-Llama-8B 등)은 PRefine과 결합 시 과도하게 신중해져 평균 인자 수가 3.34 → 2.85로 줄고 EA-F1이 낮아질 수 있습니다. 행동 공간을 좁히는 이점이 때로는 필요 인자의 누락이라는 비용으로 나타날 수 있습니다.
의의
개인 에이전트는 점차 단발성 도구 호출이 아니라 여러 세션을 거치며 사용자를 얼마나 잘 이해해 가는가로 평가될 것입니다. 이 논문은 효과적인 개인화가 사용자의 선택 그 자체가 아니라 그 선택의 이유를 포착하는 데 달려 있으며, 원시 히스토리보다 짧고 수정 가능한 가설 형태의 메모리가 훨씬 더 확장 가능한 표현임을 보여줍니다.
- 새로운 문제 정의: 잠재 선호 모델링을 과거 행동 검색과 분리해 Recall / Induction / Transfer로 분해함으로써 세션 간 개인화를 측정 가능하게 만들었습니다.
- 재사용 가능한 벤치마크: 89.7–97.4%의 일치도로 검증된 선호 어노테이션을 갖춘 MPT는 선호 인지 에이전트 연구에 통제된 테스트베드를 제공합니다.
- 확장 가능한 메모리 설계: 선호를 추상적이고 수정 가능한 가설로 표현하면 토큰 비용이 1.24% 수준으로 줄고 동적 API 스키마에도 자연스럽게 전이되므로, 히스토리가 쌓이고 API가 변하는 실제 에이전트 운영 환경에 잘 맞습니다.