한줄 요약
강화학습을 통한 요약 수준 ROUGE 최적화와 BERT 기반 추출기를 도입하여, CNN/Daily Mail 및 New York Times 데이터셋에서 최고 성능을 달성한 추상적 요약을 위한 개선된 문장 재작성 프레임워크입니다.
배경 및 동기
추상적 요약(abstractive summarization)은 문서의 핵심 내용을 간결하고 자연스러운 문장으로 재구성하는 과제입니다. 문장 재작성(Sentence Rewriting) 패러다임(Chen & Bansal, 2018)은 추출적 방법과 추상적 방법을 결합한 2단계 접근법으로, 먼저 추출기가 원문에서 핵심 문장을 선택하고, 이어서 추상기가 각 문장을 더 간결한 형태로 재작성합니다. 최종 요약은 재작성된 문장들의 연결로 구성됩니다.
이 분해 방식은 우아하지만, 기존 문장 재작성 모델에는 두 가지 근본적 한계가 있습니다:
학습-평가 불일치: 추출기는 문장 수준 ROUGE 보상으로 학습됩니다 -- 각 문장이 참조 문장과 독립적으로 매칭되어 개별 ROUGE 점수에 따라 보상을 받습니다. 그러나 최종 모델은 요약 수준 ROUGE로 평가되며, 이는 생성된 전체 요약을 전체 참조 요약과 비교합니다. 개별 점수가 높은 문장들을 탐욕적으로 선택하면 정보가 겹치는 중복 요약이 생성되어 요약 수준 성능이 저하될 수 있습니다.
제한적 문맥 이해: 기존 추출기(예: 시간적 합성곱 네트워크 기반)는 문장 간 장거리 의존성과 풍부한 의미적 관계를 포착하는 능력이 제한되어, 전체 문서 맥락에서 진정으로 핵심적인 내용을 식별하는 데 한계가 있습니다.
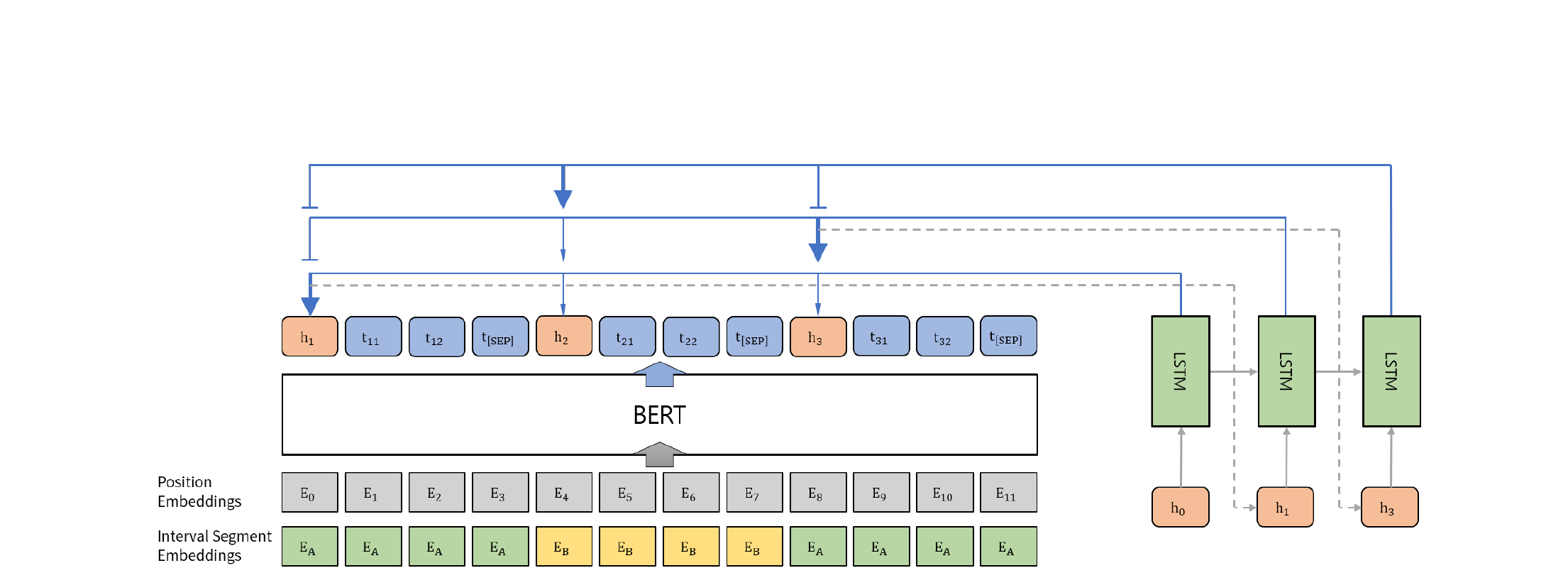
제안 방법
제안 모델은 추출기-추상기 2모듈 구조를 유지하되, 두 구성 요소와 학습 절차 모두에 상당한 개선을 도입합니다:
실험 결과
CNN/Daily Mail(비익명화 버전), New York Times(NYT50), DUC-2002 세 가지 벤치마크 데이터셋에서 평가하였습니다. BERT 기반 추출기와 요약 수준 RL 학습 모두에서 일관된 성능 향상을 확인하였습니다.
CNN/Daily Mail
| 모델 (CNN/Daily Mail) | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|
| Sentence Rewrite (Chen & Bansal, 2018) | 40.88 | 17.80 | 38.54 |
| Bottom-Up (Gehrmann et al., 2018) | 41.22 | 18.68 | 38.34 |
| BERTSUM (Liu, 2019) -- 추출적 | 43.25 | 20.24 | 39.63 |
| BERT-ext + abs (제안) | 40.14 | 17.87 | 37.83 |
| BERT-ext + abs + RL (제안) | 41.58 | 18.87 | 39.34 |
| BERT-ext + abs + RL + rerank (제안) | 41.90 | 19.08 | 39.64 |
NYT50 & DUC-2002
| 모델 | 데이터셋 | ROUGE-1 | ROUGE-2 | ROUGE-L |
|---|---|---|---|---|
| BERT-ext + abs + RL + rerank (제안) | NYT50 | 46.63 | 26.76 | 43.38 |
| BERT-ext + abs + RL + rerank (제안) | DUC-2002 | 43.39 | 19.38 | 40.14 |
분석 및 Ablation
- 추상적 요약 새 SOTA: BERT-ext + abs + RL + rerank이 CNN/Daily Mail에서 최고 추상적 요약 결과 달성 (R-AVG 33.54), 기존 문장 재작성 베이스라인을 큰 폭으로 능가합니다.
- 강력한 추출기: BERT 기반 추출기만으로도(BERT-ext) 문장 재작성 프레임워크 내 모든 이전 추출기를 능가 (R-1: 42.29, R-2: 19.38, R-L: 38.63), 사전학습된 BERT 표현과 구간 세그먼트 임베딩의 문장 선택에 대한 효과를 입증합니다.
- RL이 격차를 해소: 요약 수준 RL 학습은 비RL 베이스라인 대비 R-1 +1.44, R-2 +1.00, R-L +1.51의 향상을 달성하여, 학습 목표와 평가 지표의 정렬이 실질적인 성능 향상을 가져옴을 보여줍니다.
- 재순위화의 추가 개선: 재순위화 단계는 추가적인 향상(R-1 +0.32, R-2 +0.21, R-L +0.30)을 제공하여, 여러 추상기 출력 중 선택함으로써 중복을 줄이고 전체 품질을 향상시킬 수 있음을 보여줍니다.
- DUC-2002 일반화: DUC-2002에서 큰 마진으로 베이스라인 능가 (R-1: 43.39, R-2: 19.38, R-L: 40.14), CNN/DM 학습으로부터의 강력한 도메인 외 일반화를 입증합니다.
- 인간 평가: 인간 평가에서 전체 모델이 관련성(66점)과 가독성(61점)에서 최고 총점(127점)을 달성하여, 요약 수준 최적화가 높은 ROUGE뿐 아니라 인간 평가자가 판단하기에도 더 일관되고 정보가 풍부한 요약을 생성함을 확인합니다.
의의
본 연구는 추출-추상 요약의 근본적 문제인 모델 학습 방식(문장 수준 최적화)과 평가 방식(요약 수준 지표) 사이의 괴리를 다룹니다. 핵심 기여는 세 가지입니다:
- 원칙적 학습 목표 정렬: 요약 수준 ROUGE를 RL 보상으로 사용하고 보상 정형화를 통해 밀집 감독 신호를 제공함으로써, 추출기가 개별적으로 높은 점수를 받지만 잠재적으로 중복되는 문장을 탐욕적으로 선택하는 대신, 종합적으로 최적의 요약을 구성하는 문장 조합을 학습하도록 합니다.
- 사전학습 모델의 효과적 활용: 구간 세그먼트 임베딩을 적용한 BERT 기반 추출기는 대규모 사전학습 언어 모델이 문서 수준 문장 추출에 성공적으로 적응될 수 있음을 보여주며, 풍부한 문맥적 표현으로 선택 품질을 크게 향상시킵니다.
- 실용적 프레임워크: 모듈형 추출기-추상기 설계는 각 구성 요소를 독립적으로 학습하고 개선할 수 있게 합니다. RL 학습, 트라이그램 블로킹, 재순위화의 결합은 파이프라인의 여러 단계에서 중복을 줄이는 포괄적 접근법을 형성하며, 이후 추상적 요약 연구의 견고한 기반을 마련합니다.