한줄 요약
BERT의 중간 레이어 표현을 자기 지도 신호로 활용하는 대조 학습 방법으로, 외부 데이터나 증강, 레이블 없이도 고품질 문장 임베딩을 생성하며 STS 벤치마크(예: BERT-base 기준 전체 STS 평균 74.62)와 다국어 STS, 다양한 전이 학습 태스크에서 우수한 성능을 달성합니다.
배경 및 동기
BERT와 같은 사전학습 언어 모델은 강력한 문맥적 단어 표현을 생성하지만, 이로부터 고품질의 문장 수준 표현을 도출하는 것은 여전히 어려운 과제입니다. 토큰 임베딩 평균이나 [CLS] 토큰을 사용하는 단순한 방법은 의미 유사도 태스크에서 GloVe와 같은 비문맥적 기준선보다도 낮은 성능을 보이는 경우가 많습니다. 이러한 현상은 비등방성(anisotropy) 문제라 불리며, BERT의 토큰 표현이 임베딩 공간에서 좁은 원뿔 형태로 분포하여 코사인 유사도가 의미적 유사성을 제대로 반영하지 못하기 때문에 발생합니다.
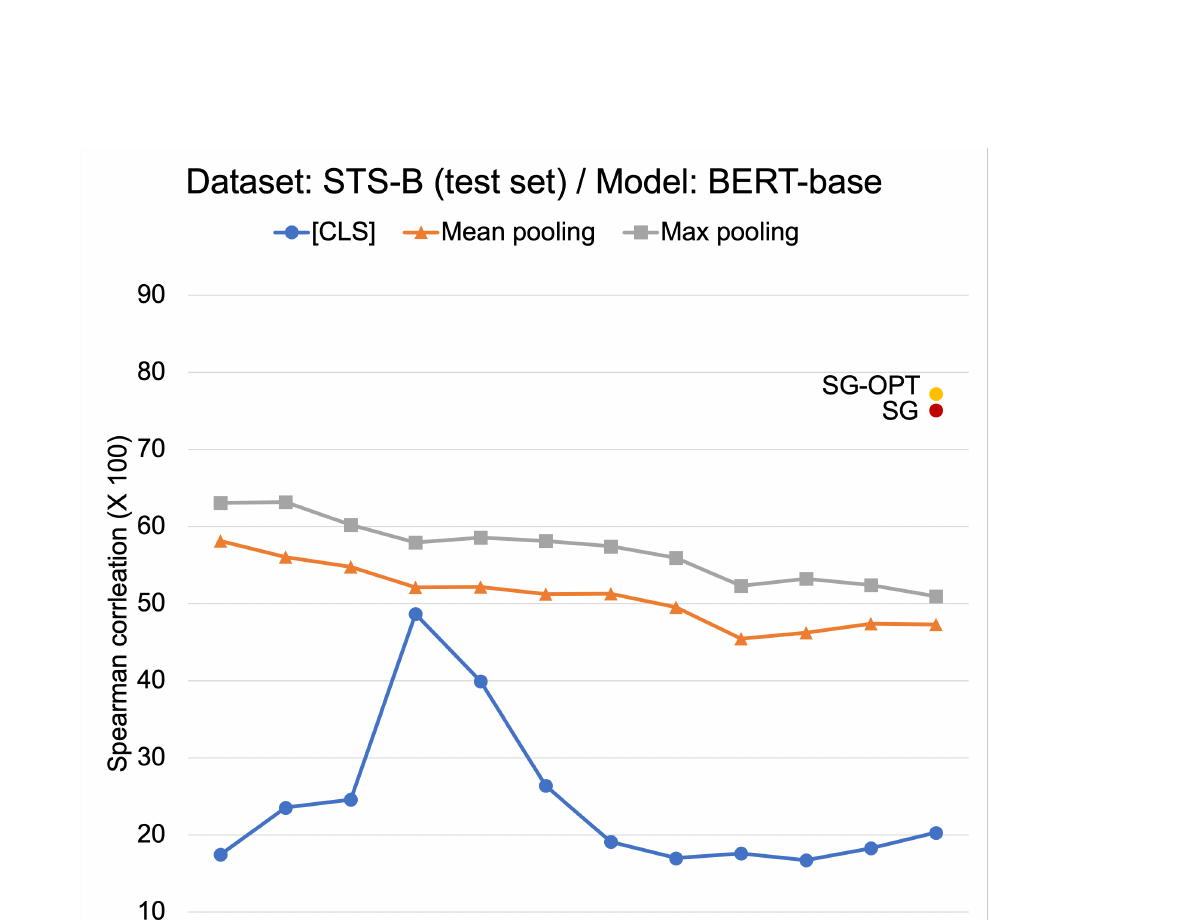
문제의 심각성: 사전 실험에서 저자들은 다양한 BERT 레이어와 풀링 방법의 조합으로 문장 임베딩을 구성하여 STS-B에서 테스트했습니다. BERT-base의 Spearman 상관계수(x100)는 16.71(10번째 레이어의 [CLS])부터 63.19(2번째 레이어의 max pooling)까지 범위를 보였습니다. 레이어/풀링 선택에 따라 거의 47점이나 차이가 나는 이 극적인 편차는, 최종 레이어 [CLS] 토큰을 사용하는 표준 관행이 최적과 거리가 멀며 개선의 여지가 크다는 것을 보여주었습니다.
기존 연구의 한계: 문장 임베딩을 위한 기존 대조 학습 방법들(예: Fang and Xie (2020)의 역번역 기반 CERT, NLI 지도 학습 기반 SBERT)은 긍정/부정 쌍 구성을 위해 외부 데이터셋이나 증강 파이프라인에 의존합니다. 역번역은 번역 모델이 필요하고 노이즈를 유발하며, NLI 지도 학습은 해당 데이터가 존재하는 도메인으로 적용을 제한합니다. 이러한 의존성은 특수 도메인 텍스트에 적용할 때 도메인 불일치 문제를 야기합니다.
핵심 관찰: BERT의 서로 다른 레이어는 서로 다른 수준의 언어적 추상화를 포착합니다 -- 하위 레이어는 표면적/구문적 특징을, 상위 레이어는 의미적 정보를 인코딩합니다(Jawahar et al., 2019). 이러한 자연스러운 계층 구조가 동일 문장에 대한 다양한 "관점(view)"을 제공하며, 중간 레이어 표현은 해당 문장을 개념적으로 대표하는 것이 보장되므로 대조 학습의 이상적인 피벗으로 활용할 수 있습니다.
이 관찰을 바탕으로, 저자들은 BERT의 최종 레이어 [CLS] 표현을 중간 레이어 표현과 대조하여 미세조정하는 Self-Guided Contrastive Learning을 제안합니다. 기본 NT-Xent 손실을 사용하는 SG와 최적화된 대조 목적함수를 사용하는 SG-OPT 두 가지 변형이 있으며, 외부 데이터, 증강, 추론 시 후처리가 일절 필요 없습니다.
제안 방법
본 방법은 비레이블 문장만을 사용하는 대조 학습 프레임워크를 통해 BERT를 미세조정합니다. 핵심 아이디어는 BERT를 두 복사본 -- BERTF(고정, 중간 레이어에서 학습 신호 제공)와 BERTT(조정, 최종 레이어 [CLS]가 문장 임베딩으로 최적화) -- 으로 복제하고, 맞춤형 대조 목적함수로 학습하는 것입니다.
학습 상세 설정: STS-B의 일반 문장(학습, 검증, 테스트 세트의 금표준 주석 미사용)을 사용하여 BERT를 미세조정합니다 -- BERT-flow와 동일한 설정입니다. 하이퍼파라미터는 STS-B 검증 세트에서 최적화: 온도 tau=0.01, 정규화 가중치 lambda=0.1. 투영 헤드 f는 은닉 크기 4096, GELU 활성화의 2층 MLP입니다. 모든 학습 모델 성능은 무작위성을 줄이기 위해 8회 실행의 평균으로 보고됩니다. 구현은 HuggingFace Transformers와 SBERT 라이브러리를 기반으로 하며, github.com/galsang/SG-BERT에서 공개되어 있습니다.
- 데이터 증강 불필요: 드롭아웃 마스크, 역번역 등의 증강 전략을 필요로 하는 방법들과 달리, SG-CL은 모델의 내부 레이어 계층 구조만으로 대조 관점을 도출
- 효율적인 추론: 테스트 시 BERTT의 단일 순전파만 필요 -- BERTF, 투영 헤드, 모든 중간 레이어는 학습 후 폐기됨. [CLS] 토큰이 표준 BERT 추론과 동일한 비용으로 곧바로 문장 벡터로 사용
- 도메인 비종속적: 비레이블 텍스트만 필요하므로, NLI, 패러프레이즈 등 특수 지도 데이터 없이 어떤 도메인에도 적용 가능
- 원칙적인 목적함수 설계: NT-Xent의 네 가지 상호작용 요소에 대한 체계적 분석이 각 설계 결정에 이론적 근거를 제공하며, 임의적 수정에 의존하지 않음
실험 결과
SG-CL은 의미 텍스트 유사도(STS) 태스크, SentEval 전이 학습 태스크, 다국어 STS에서 포괄적으로 평가되며, 계산 효율성과 도메인 강건성도 분석됩니다. BERT-base, BERT-large, SBERT-base, SBERT-large 네 가지 기본 모델에서 테스트되었습니다.
의미 텍스트 유사도 (Spearman 상관계수 x100, BERT-base)
| 모델 | 풀링 | STS-B | SICK-R | STS12 | STS13 | STS14 | STS15 | STS16 | 평균 |
|---|---|---|---|---|---|---|---|---|---|
| GloVe | Mean | 58.02 | 53.76 | 55.14 | 70.66 | 59.73 | 68.25 | 63.66 | 61.32 |
| 미조정 | CLS | 20.30 | 42.42 | 21.54 | 32.11 | 21.28 | 37.89 | 44.24 | 31.40 |
| 미조정 | Mean | 47.29 | 58.22 | 30.87 | 59.89 | 47.73 | 60.29 | 63.73 | 52.57 |
| Flow | Mean-2 | 71.35 | 64.95 | 64.32 | 69.72 | 63.67 | 77.77 | 69.59 | 68.77 |
| Contrastive (BT) | CLS | 63.27 | 66.91 | 54.26 | 64.03 | 54.28 | 68.19 | 67.50 | 62.63 |
| Contrastive (SG) | CLS | 75.08 | 68.19 | 63.60 | 76.48 | 67.57 | 79.42 | 74.85 | 72.17 |
| Contrastive (SG-OPT) | CLS | 77.23 | 70.20 | 66.84 | 80.13 | 71.23 | 81.56 | 77.17 | 74.62 |
SentEval 전이 학습 태스크 (정확도, BERT-base)
| 모델 | MR | CR | SUBJ | MPQA | SST2 | TREC | MRPC | 평균 |
|---|---|---|---|---|---|---|---|---|
| + Mean pooling | 81.46 | 86.71 | 95.37 | 87.90 | 85.83 | 90.30 | 73.36 | 85.85 |
| + WK pooling | 80.64 | 85.53 | 95.27 | 88.63 | 85.03 | 94.03 | 71.71 | 85.83 |
| + SG-OPT | 82.47 | 87.42 | 95.40 | 88.92 | 86.20 | 91.60 | 74.21 | 86.60 |
어블레이션 연구
어블레이션 연구는 전체 STS 테스트 세트에서 각 변형을 평가하여 모든 설계 결정을 체계적으로 검증합니다:
| 변형 | STS 평균 | 변화 |
|---|---|---|
| SG-OPT (Lopt3) | 74.62 | -- |
| + Lopt2 (단일 관점) | 73.14 | -1.48 |
| + Lopt1 (cj 척력 포함) | 72.61 | -2.01 |
| + SG (Lbase, 최적화 없음) | 72.17 | -2.45 |
| tau = 0.1 (0.01 대비) | 70.39 | -4.23 |
| lambda = 0.0 (정규화 없음) | 73.76 | -0.86 |
| lambda = 1.0 (강한 정규화) | 73.18 | -1.44 |
| 투영 헤드 (f) 제거 | 72.78 | -1.84 |
계산 효율성
| 방법 | 학습 시간 | 추론 시간 (초) |
|---|---|---|
| BERT + Mean pooling | -- | 13.94 |
| BERT + WK pooling | -- | 197.03 (~3.3분) |
| BERT + Flow | 155.37초 (~2.6분) | 28.49 |
| BERT + SG-OPT | 455.02초 (~7.5분) | 10.51 |
SG-OPT는 적절한 학습 시간(~7.5분)이 필요하지만, 학습 완료 후 후처리가 필요 없기 때문에 모든 방법 중 가장 빠른 추론(STS-B에서 10.51초)을 달성합니다. WK pooling은 추론 시 가장 느리고(197초), Flow도 흐름 기반 변환으로 인해 오버헤드가 발생합니다(28.5초).
주요 실험 결과
- 기본 BERT 대비 극적인 향상: SG-OPT는 전체 STS 평균 점수를 31.40 (BERT [CLS])에서 74.62로 -- 43점 이상의 절대적 향상을 달성하여, 기본 BERT 문장 임베딩의 품질 문제가 자기 안내 대조 학습을 통해 해결 가능함을 입증
- 후처리 방법 대비 우위: BERT-flow(68.77 평균), WK pooling(25.58 평균)과 비교하여 SG-OPT가 월등한 성능 달성. 특히 자기 안내 대조 학습(SG-OPT: 74.62)이 역번역 대조 학습(BT: 62.63)을 크게 상회하여, 외부 증강 대비 내부 안내의 우수성을 입증
- 모델 크기에 걸친 일관성: BERT-base, BERT-large, SBERT-base, SBERT-large에서 모두 성능 향상이 유지되어, 모델 아키텍처와 크기에 대한 방법의 범용성을 확인
- 다국어 역량: MBERT와 교차 언어 제로샷 전이를 활용하여, SemEval-2014 Task 10 (스페인어)에서 82.09, SemEval-2017 Task 1 (아랍어, 스페인어, 영어)에서 경쟁적 결과를 달성하여, 본 방법이 다국어 환경으로 자연스럽게 확장됨을 확인
- 우수한 전이 학습 성능: SentEval 전이 학습 태스크에서 SG-OPT(86.60 평균)가 mean pooling(85.85)과 WK pooling(85.83) 모두를 상회하여, 대조 미세조정이 범용적 활용성을 저하시키지 않고 오히려 향상시킴을 확인
- 도메인 강건성: STS-B 대신 NLI 데이터로 학습 시, SG-OPT는 STS-B에서 1.83점, 전체 STS 평균에서 1.63점만 하락 -- Flow가 각각 12.16점, 4.19점 하락하는 것과 대비되어, 도메인 이동에 대한 강한 강건성을 입증
- 어블레이션 분석 결과: NT-Xent에 대한 세 가지 최적화가 모두 성능에 기여하며, 투영 헤드가 중요(-1.84점 하락)하고, 온도 tau=0.01이 0.1보다 훨씬 우수(-4.23점 차이)하며, 역번역 + 자기 안내 앙상블(75.10 평균)이 개별 기법 이상의 성능을 달성
의의
본 연구는 문장 표현 학습 분야에 여러 중요한 기여를 했습니다:
- 문장 임베딩을 위한 자기 지도 대조 학습의 선구적 연구: SG-CL은 레이블 데이터나 데이터 증강 없이 모델 자체의 내부 레이어 계층 구조만을 학습 신호로 활용하여 BERT로부터 고품질 문장 임베딩을 도출할 수 있음을 최초로 보여준 방법 중 하나입니다. 중간 은닉 표현을 긍정 샘플로 "재활용"하는 아이디어는 참신하고 우아한 해법이었습니다.
- 대조 목적함수의 원칙적 분석: NT-Xent를 블랙박스로 사용하는 대신, 본 논문은 손실함수를 네 가지 상호작용 요소로 체계적으로 분해하고, 어떤 것이 필수적이고(자신의 중간 관점에 대한 인력, 타 문장 관점에 대한 척력) 어떤 것이 불필요한지(임베딩 간 척력, 관점 간 척력)를 실험적으로 검증했습니다. 이 분석은 다른 환경에서 대조 손실을 맞춤 설계할 때 재사용 가능한 프레임워크를 제공합니다.
- BERT 레이어 계층 구조의 귀납적 편향 활용: 중간 레이어와 최종 레이어가 동일 입력에 대해 자연스럽게 상호 보완적인 관점을 제공한다는 통찰은, 이후 레이어별 표현 학습 및 다중 관점 대조 목적함수 연구에 영향을 미쳤습니다. 레이어/풀링 조합에 따라 47점의 편차를 보여준 사전 실험 자체도 독자적인 발견이었습니다.
- 실용성과 효율성: SG-OPT는 가장 빠른 추론 시간(10.51초 vs. Flow 28.49초, WK pooling 197초)을 달성하며, 후처리가 필요 없습니다. 학습은 8분 미만이 소요됩니다. 코드가 공개되어 있어 도메인별 환경에 즉시 적용할 수 있습니다.
- 다국어 일반화: 스페인어와 아랍어 STS 태스크에서 교차 언어 제로샷 전이를 통한 MBERT 적용 성공은, 자기 안내 대조 학습이 영어에 국한되지 않으며 저자원 언어의 문장 임베딩 향상을 위한 가능성을 열어주었습니다.
- NLP 대조 학습 커뮤니티에 미친 영향: ACL-IJCNLP 2021에 발표된 본 연구는 SimCSE(Gao et al., 2021), Carlsson et al. (2021), Wang et al. (2021) 등 다른 주요 방법들과 동시기에 등장하여, 대조 학습을 비지도 문장 임베딩의 표준 접근법으로 확립하는 데 기여했습니다. 역번역과 자기 안내의 앙상블 실험(75.10 평균 달성)은 이러한 접근법들이 상호 보완적임을 보여주었습니다.