한줄 요약
기계번역 사전학습에서 얻은 맥락화된 단어 벡터(CoVe)를 활용하는 간단한 3부분 신경망 구조 SECOVARC로, 논증 추론 이해라는 도전적인 논리적 추론 과제에서 전이학습의 효과를 입증합니다.
배경 및 동기
논증 추론 이해 과제(Argument Reasoning Comprehension Task, Habernal et al., 2018)는 SemEval 2018에서 새롭게 발표된 과제로, 자연어 논증에서 추론의 핵심인 암시적 보증(implicit warrant)을 식별하는 것을 목표로 합니다. 주장(claim)과 이유(reason)가 주어졌을 때, 두 후보 보증 중 논리적으로 올바른 것을 선택해야 합니다. 데이터셋은 약 2K개의 크라우드소싱 인스턴스로 구성되며, 각 인스턴스에는 토론의 제목과 간략한 설명, 그리고 주장, 이유, 두 후보 보증이 포함됩니다.
이 과제가 도전적인 이유는 다음과 같습니다:
- 인간 수준의 추론 필요: 이진 분류로 단순화할 수 있지만, 주장이 이유와 보증에 의해 논리적으로 뒷받침되는지 판단하는 고차원적 추론이 요구됨
- 상식 지식 의존: 문제 해결을 위해 입력 문장에 명시적으로 존재하지 않는 상식 지식이 필요한 경우가 많음
- 데이터 부족: 약 2K개의 학습 데이터는 CNN이나 어텐션 기반 RNN과 같은 복잡한 신경망 모델을 처음부터 학습하기에 턱없이 부족
핵심 아이디어: 복잡한 아키텍처를 설계하는 대신, 저자들은 전이학습(transfer learning)이 데이터 부족 문제를 해결할 수 있다고 가정합니다. 대규모 기계번역(MT) 데이터로 사전학습된 Bi-LSTM 인코더를 활용함으로써, 2K개의 데이터만으로는 달성할 수 없는 의미 있는 맥락화된 문장 표현을 얻습니다. 이를 통해 모델 구조는 의도적으로 단순하게 유지하면서도, 수백만 개의 MT 문장 쌍에서 전이된 지식의 혜택을 받습니다.
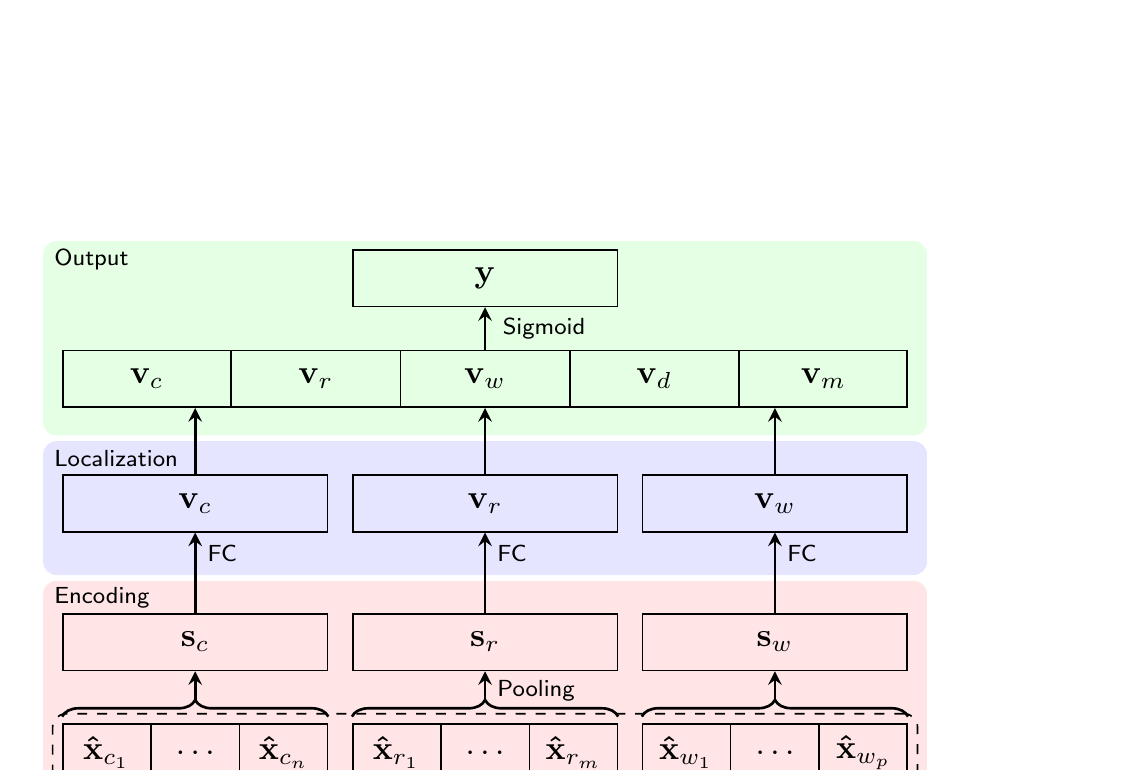
제안 방법: SECOVARC
SECOVARC(Sentence Encoder with COnextualized Vectors for Argument Reasoning Comprehension)는 주장, 이유, 보증 세 문장을 입력으로 받아 0과 1 사이의 점수를 출력하며, 이는 이유와 보증에 기반하여 주장이 얼마나 합리적인지를 나타냅니다. 아키텍처는 3개 레이어로 구성됩니다:
핵심 설계 결정
모델 설계에는 두 가지 중요한 결정이 반영되었습니다. 첫째, 모델은 한 번에 하나의 보증만 입력으로 받습니다. 이는 두 보증 사이에서 단순히 선택하는 것이 아니라, (주장, 이유, 보증) 세 쌍이 타당한지 판단하는 것을 학습해야 한다는 직관에 기반합니다. 둘째, 제한된 학습 데이터에서의 과적합을 방지하기 위해 어텐션 메커니즘 없이 가능한 한 단순한 구조를 유지하며, 대신 전이학습에 의존하여 표현력을 확보합니다.
데이터 처리 및 추론
모델이 한 번에 하나의 보증만 받으므로, 학습 데이터는 올바른 보증에 1점, 잘못된 보증에 0점을 부여하도록 전처리되어 학습 데이터가 실질적으로 두 배로 늘어납니다. 테스트 시에는 두 보증을 독립적으로 평가하여 -- y1 = SECOVARC(c, r, w1), y2 = SECOVARC(c, r, w2) -- 더 높은 점수의 보증을 선택합니다.
학습 세부사항
하이퍼파라미터: 단어 임베딩 차원 de = 300 (840B GloVe), 문장 표현 차원 ds = 600, 위치화 차원 df = 300. 옵티마이저: Adam (학습률 0.001). 배치 크기: 64. 최대 에폭: 10 (개발 셋 정확도 기준 최적 모델 선택). 정규화: L2 가중치 감쇠 (1e-5) + 드롭아웃 (p = 0.1). 단어 벡터 포함 모든 파라미터를 파인튜닝. CoVe 외 가중치는 Uniform(-0.005, 0.005)로 초기화, 편향은 0으로 초기화.
실험 결과
SemEval-2018 Task 12 데이터셋(~2K 크라우드소싱 인스턴스)에서 평가하였습니다. 무작위 초기화로 인한 결과 불안정성 때문에, 동일한 하이퍼파라미터로 20회 실험한 평균과 표준편차로 보고합니다.
주요 결과: SECOVARC vs. 베이스라인
| 모델 | 개발 정확도 (±) | 테스트 정확도 (±) |
|---|---|---|
| 인간 평균 | - | 0.798 (±0.162) |
| 인간 (추론 훈련 후) | - | 0.909 (±0.114) |
| 무작위 베이스라인 | 0.473 (±0.039) | 0.491 (±0.031) |
| 언어 모델 | 0.617 | 0.500 |
| Attention | 0.488 (±0.006) | 0.513 (±0.012) |
| Attention w/ context | 0.502 (±0.031) | 0.512 (±0.014) |
| Intra-warrant attention | 0.638 (±0.024) | 0.556 (±0.016) |
| Intra-warrant attention w/ context | 0.637 (±0.040) | 0.560 (±0.055) |
| SECOVARC (공식 제출) | 0.731 | 0.565 |
| SECOVARC-last (휴리스틱 미포함) | 0.701 (±0.011) | 0.559 (±0.019) |
| SECOVARC-last (휴리스틱 포함) | 0.706 (±0.014) | 0.554 (±0.015) |
| SECOVARC-max (휴리스틱 미포함) | 0.680 (±0.007) | 0.591 (±0.016) |
| SECOVARC-max (휴리스틱 포함) | 0.684 (±0.008) | 0.592 (±0.016) |
전이학습 효과 검증
사전학습된 CoVe 인코더가 실질적으로 성능 향상에 기여하는지 검증하기 위해, 동일한 구조이지만 Bi-LSTM을 무작위 초기화한 비전이 모델과 비교 실험을 수행하였습니다:
| 모델 | 개발 정확도 (±) | 테스트 정확도 (±) |
|---|---|---|
| BoW (단어 벡터 평균) | 0.677 (±0.006) | 0.502 (±0.014) |
| Bi-LSTM-last (무작위 초기화) | 0.678 (±0.010) | 0.554 (±0.024) |
| Bi-LSTM-max (무작위 초기화) | 0.670 (±0.011) | 0.543 (±0.027) |
| SECOVARC-last (CoVe) | 0.706 (±0.014) | 0.554 (±0.015) |
| SECOVARC-max (CoVe) | 0.684 (±0.008) | 0.592 (±0.016) |
- 최고 테스트 성능: 휴리스틱이 포함된 SECOVARC-max가 59.2% 테스트 정확도를 달성하여, 과제 주최자의 intra-warrant attention 모델을 포함한 모든 베이스라인을 능가
- 전이학습 효과 확인: SECOVARC가 동일 구조의 비전이 Bi-LSTM 변형(BoW: 50.2%, Bi-LSTM-max: 54.3%)을 일관되게 능가하여, 아키텍처가 아닌 CoVe 사전학습이 성능 향상의 핵심 요인임을 직접적으로 확인
- 작은 편차: SECOVARC 모델이 20회 실행에서 비전이 모델보다 작은 표준편차를 보여, 전이학습이 더 안정적이고 신뢰할 수 있는 학습으로 이어짐을 입증
- 휴리스틱 특징의 효과: 요소별 차이(|vw − vr − vc|)와 곱(vw ⊙ vr ⊙ vc) 특징이 전반적으로 테스트 정확도를 향상시켰으며, SECOVARC-max에서 가장 뚜렷한 효과를 보임
- 개발-테스트 성능 격차: 개발과 테스트 정확도 간의 뚜렷한 격차(예: 공식 제출에서 73.1% vs. 56.5%)는 이 과제가 본질적으로 과적합 기반 개선에 저항적이며, 일반화가 핵심 과제임을 시사
- 인간 성능 격차: 인간 정확도는 79.8%(추론 훈련 후 90.9%)로, SECOVARC의 성과를 넘어서도 상당한 모델 개선의 여지가 존재
의의
본 연구는 기계번역에서의 전이학습이 제한된 학습 데이터를 가진 추론 과제에서 성능을 크게 향상시킬 수 있음을 보여주는 초기이자 영향력 있는 연구입니다. NAACL-HLT 2018과 공동 개최된 SemEval 2018에서 발표된 본 논문은 ELMo(Peters et al., 2018)와 BERT가 분야를 변혁시키기 직전의 중요한 시점에 등장하여, 사전학습된 맥락화 표현이 논리적 추론을 요구하는 자연어 이해 과제에 필수적이라는 구체적인 증거를 제시하였습니다.
SECOVARC 아키텍처의 의도적인 단순함은 중요한 교훈을 담고 있습니다: 학습 데이터가 부족할 때, 아키텍처의 복잡성을 높이는 것보다 (전이학습을 통한) 더 나은 표현에 투자하는 것이 더 효과적입니다. 이 원칙은 이후 현대 NLP를 지배하는 사전학습-미세조정(pre-train-then-fine-tune) 패러다임에서 대규모로 검증되었습니다.
향후 연구 방향 (논문에서 제시): 저자들은 CoVe 대신 Subramanian et al. (2018)이나 ELMo(Peters et al., 2018)와 같은 더 강력한 범용 문장 인코더를 적용할 것을 제안하며, 정교한 규칙이나 휴리스틱을 통해 제한된 학습 세트를 더욱 확장하는 데이터 증강 방법도 고려할 수 있다고 언급합니다.