One-Line Summary
We discover that LLM overconfidence stems from "answer-independence" -- where confidence verbalization is internally decoupled from the model's own answer -- and propose ADVICE, a contrastive fine-tuning framework that grounds confidence estimation in the actual answer, achieving substantial calibration improvements (e.g., ECE from 16.9 to 10.4 on Llama-3.1-8B) with strong out-of-distribution generalization.

Background & Motivation
Large language models inevitably generate factually inaccurate content (hallucinations), and while eliminating this entirely may be theoretically unavoidable, a promising mitigation strategy is to have LLMs provide confidence estimates alongside their answers. Verbalized confidence -- where models express confidence levels in natural language -- is particularly attractive due to its universal applicability and user-friendly nature, requiring no access to internal model states.
However, a well-known and critical issue hinders broader application: systematic overconfidence, where models assign high confidence irrespective of output quality. Rather than simply mitigating overconfidence after the fact, this work asks a deeper question: why does overconfidence arise in the first place?
Key Finding: Through analysis of intermediate processes, the authors discover that LLM-generated answers and confidence verbalization are internally decoupled -- a phenomenon they term "answer-independence." Specifically:
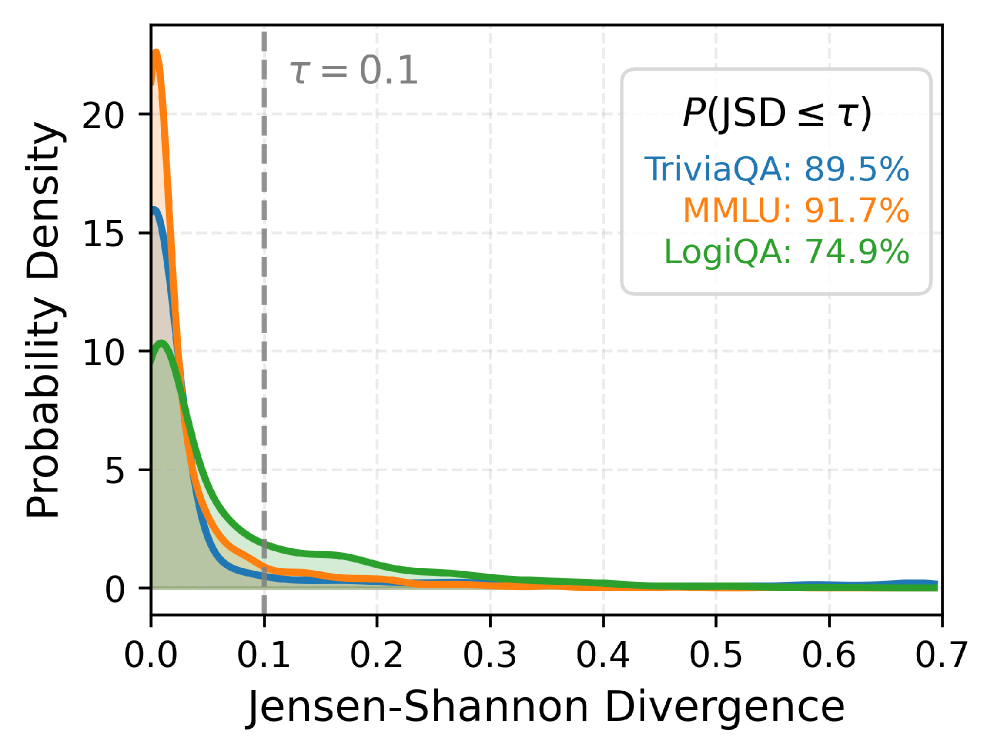
- Distribution analysis: The Jensen-Shannon divergence (JSD) between confidence distributions conditioned on correct vs. incorrect answers shows strong concentration near zero (JSD ≤ 0.1 for the vast majority of samples), proving that models produce nearly identical confidence regardless of the answer.
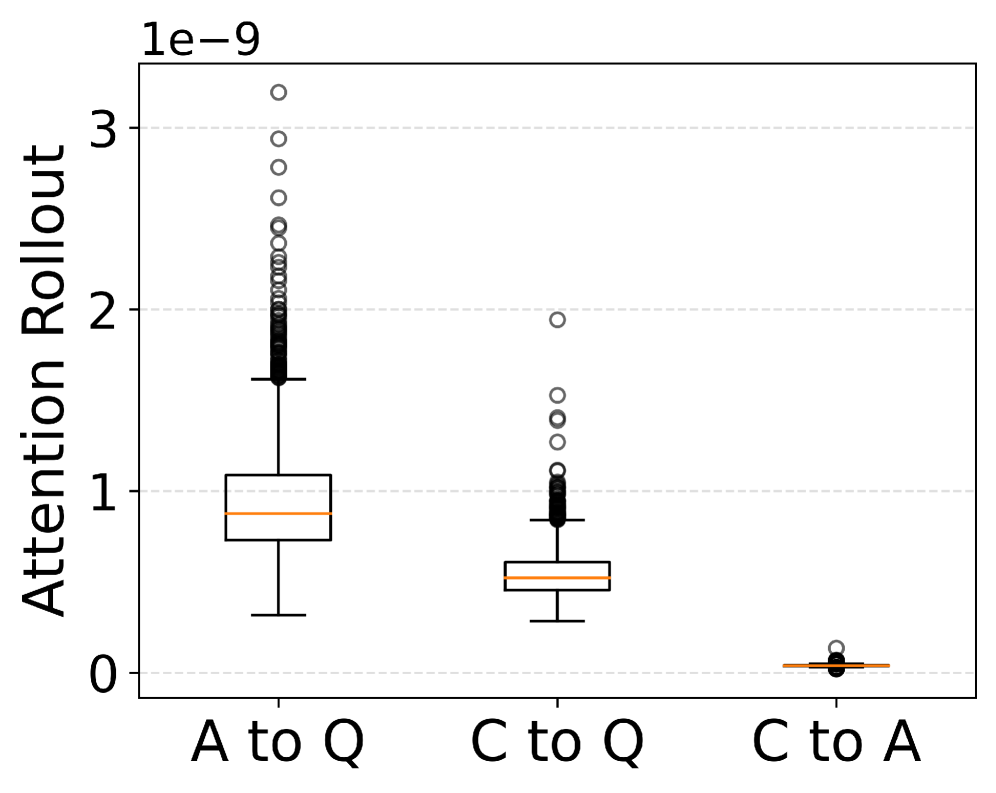
- Attention Rollout analysis: Attention flow from confidence tokens to answer tokens is significantly lower than attention to question tokens, indicating models rely less on answer-specific information when generating confidence.
- Integrated Gradients analysis: Token attribution reveals that answer tokens are consistently under-weighted compared to tokens in other components (e.g., question, instruction), further confirming the decoupling.
Proposed Method: ADVICE Framework
ADVICE (Answer-Dependent VerbalIzed Confidence Estimation) is a lightweight fine-tuning framework that explicitly promotes answer-grounded confidence estimation. The key insight is to teach the model, through contrastive training on correct/incorrect answer pairs, that confidence should fundamentally differ depending on the answer's correctness.
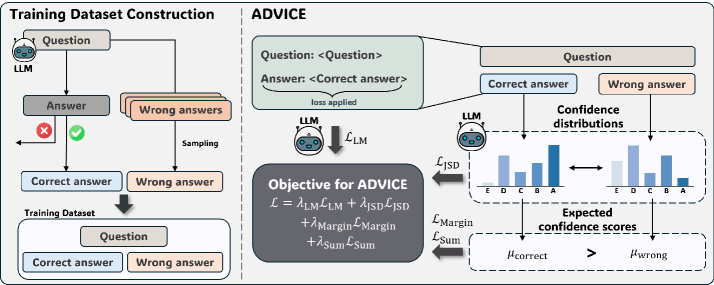
The four loss objectives and their specific roles:
- Language Modeling Loss (L_LM): Standard negative log-likelihood of correct answers, preserving the model's general QA capabilities and preventing catastrophic forgetting during fine-tuning.
- Jensen-Shannon Divergence Loss (L_JSD): Explicitly drives the model to distinguish confidence distributions between correct and incorrect answers. Formulated as max(0, δ_JSD - D_JSD(P_correct || P_wrong)), ensuring the two distributions are sufficiently separated.
- Margin Loss (L_Margin): Enforces directional separation via max(0, δ_Margin - (μ_correct - μ_wrong)), guaranteeing that the mean confidence for correct answers exceeds that for incorrect ones by at least δ_Margin.
- Sum Loss (L_Sum): Enforces the ideal constraint μ_correct + μ_wrong = 1, reflecting that confidence should represent the true likelihood of answer correctness. All weighting parameters are set to 1 for simplicity.
Experimental Results
Experiments are conducted on three models (Llama-3.1-8B-Instruct, Mistral-7B-Instruct-v0.3, Gemma-2-9b-it) across in-domain (TriviaQA) and out-of-distribution (MMLU, LogiQA) benchmarks, using four metrics: Expected Calibration Error (ECE), Absolute Net Calibration Error (|NCE|), Brier Score (BS), and AUROC.
In-Domain Results (TriviaQA)
| Model | Method | ECE ↓ | |NCE| ↓ | BS ↓ | AUROC ↑ |
|---|---|---|---|---|---|
| Llama-3.1-8B | Default | 16.9 | 16.6 | 21.2 | 56.2 |
| Llama-3.1-8B | Self-Consistency | 15.7 | - | - | 58.6 |
| Llama-3.1-8B | ConfTuner | 5.2 | 1.1 | 15.3 | 66.3 |
| Llama-3.1-8B | ADVICE | 10.4 | 9.8 | 14.8 | 77.0 |
| Llama-3.1-8B | ADVICE + ConfTuner | 9.4 | - | - | 77.9 |
Out-of-Distribution Results
| Dataset | Method | ECE ↓ | AUROC ↑ |
|---|---|---|---|
| MMLU | Default | 26.9 | - |
| MMLU | ConfTuner | 13.9 | - |
| MMLU | ADVICE | 8.6 | 69.2 |
| LogiQA | Default | 53.8 | - |
| LogiQA | ConfTuner | 28.6 | - |
| LogiQA | ADVICE | 23.0 | 57.9 |
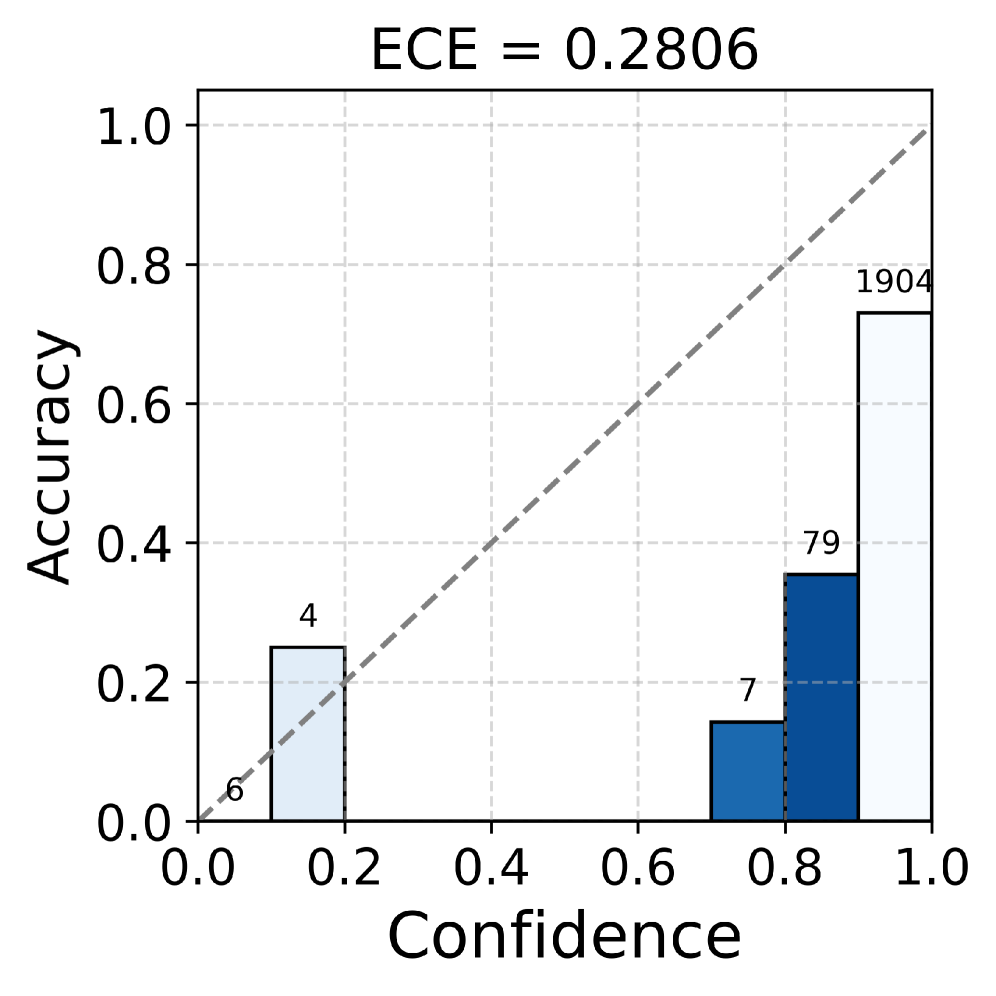
Ablation Study (Gemma-2-9b on TriviaQA)
| Configuration | ECE ↓ |
|---|---|
| L_LM only | 23.0 |
| L_LM + L_JSD | 8.6 |
| L_LM + L_Margin | 16.8 |
| Full ADVICE (all objectives) | 6.2 |
- OOD Generalization: ADVICE outperforms ConfTuner in 19 of 24 out-of-distribution settings across MMLU and LogiQA, demonstrating strong robustness. On MMLU, ECE drops from 26.9 (Default) to 8.6 (ADVICE), surpassing ConfTuner's 13.9.
- Efficiency: ADVICE clusters in the lower-left region of the ECE-vs-token-usage plot, achieving lower ECE with fewer generated tokens. Self-Consistency (M=5), by contrast, dramatically increases token usage with limited calibration gains.
- Task Performance Preservation: QA accuracy is preserved or even slightly improved after fine-tuning -- Llama-3.1 goes from 75.2% to 78.1%, and Gemma-2 from 70.7% to 71.7%, confirming no degradation of core capabilities.
- Cross-Format Generalization: Trained on only two confidence formats (ScoreLetter, ScoreNumber), ADVICE generalizes to unseen formats: ScoreText (ECE 8.3), ScorePercent (ECE 6.7), and ScoreFloat (ECE 6.2) on Gemma-2.
- Verified Answer-Awareness: Answer masking experiments confirm that Default models produce confidence markedly skewed toward high values even when answers are replaced with padding, while ADVICE-trained models show substantially declined confidence when answers are masked -- validating that ADVICE genuinely enhances answer-awareness. Attention Rollout scores also increase significantly toward answer tokens after training.
Why It Matters
Knowing whether an AI is truly confident when it says "I'm sure" is critically important. In high-stakes domains such as healthcare, law, and finance, LLM overconfidence can lead to serious real-world consequences -- users may trust incorrect outputs without questioning them.
This work makes three key contributions beyond prior approaches:
- Mechanistic insight: Rather than treating overconfidence as a black-box phenomenon, the paper identifies and rigorously validates the specific internal mechanism (answer-independence) causing it, using distributional analysis, attention rollout, and integrated gradients.
- Practical and lightweight solution: ADVICE requires only 4,000 training instances from a single dataset (TriviaQA) yet generalizes to unseen datasets, models, and confidence formats -- making it highly practical for real-world deployment.
- Foundation for trustworthy AI: By grounding confidence in the actual answer, ADVICE lays the groundwork for systems where users can meaningfully rely on stated confidence levels, enabling better human-AI collaboration and safer deployment of LLMs in critical applications.