한줄 요약
LLM의 과신(overconfidence)이 신뢰도 생성과 답변 생성이 내부적으로 분리되는 "답변 독립성"에서 비롯됨을 밝히고, 대조 학습 기반 미세조정 프레임워크 ADVICE를 제안하여 신뢰도 보정을 크게 개선합니다 (예: Llama-3.1-8B에서 ECE 16.9 → 10.4, AUROC 56.2 → 77.0).

배경 및 동기
대규모 언어 모델(LLM)은 불가피하게 사실과 다른 내용(할루시네이션)을 생성하며, 이를 완전히 제거하는 것은 이론적으로도 어려울 수 있습니다. 이에 대한 유망한 대안으로, LLM이 답변과 함께 신뢰도 추정치를 제공하는 방법이 주목받고 있습니다. 특히 자연어로 신뢰도를 표현하는 verbalized confidence는 모델 내부 상태에 접근할 필요 없이 범용적으로 적용할 수 있어 매력적입니다.
그러나 핵심적인 문제가 있습니다: LLM은 출력 품질과 무관하게 높은 신뢰도를 부여하는 체계적인 과신(overconfidence)을 보입니다. 본 연구는 과신을 사후적으로 완화하는 것을 넘어, 왜 과신이 발생하는가라는 근본적인 질문에 답합니다.
핵심 발견: 모델 내부 프로세스를 분석한 결과, LLM의 답변 생성과 신뢰도 표현이 내부적으로 분리(decoupled)되어 있음을 발견했으며, 이를 "답변 독립성(answer-independence)"이라 명명합니다.
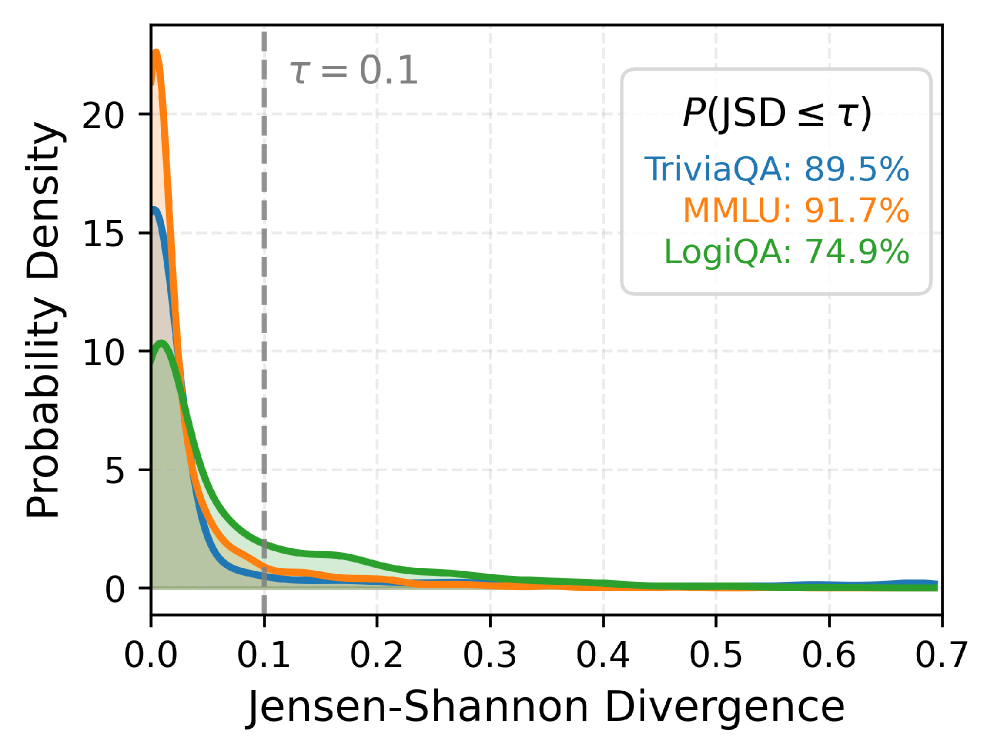
- 분포 분석: 정답과 오답에 조건부인 신뢰도 분포 간 Jensen-Shannon 발산(JSD)이 대부분의 샘플에서 0.1 이하에 집중되어, 모델이 답변과 무관하게 거의 동일한 신뢰도를 생성함을 증명합니다.
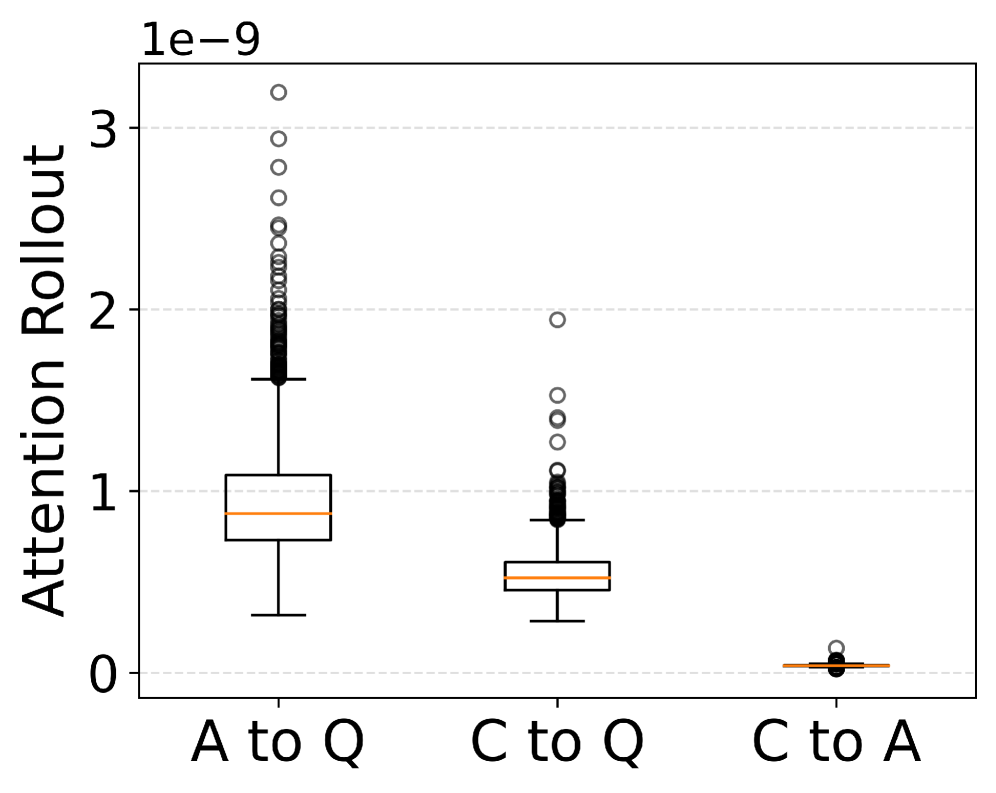
- Attention Rollout 분석: 신뢰도 토큰에서 답변 토큰으로의 어텐션 흐름이 질문 토큰 대비 유의미하게 낮아, 모델이 신뢰도 생성 시 답변 정보에 덜 의존함을 확인했습니다.
- Integrated Gradients 분석: 토큰 기여도 분석에서 답변 토큰이 질문이나 지시문 등 다른 구성 요소에 비해 일관되게 과소 가중치를 받고 있음이 드러났습니다.
제안 방법: ADVICE 프레임워크
ADVICE(Answer-Dependent VerbalIzed Confidence Estimation)는 답변에 기반한 신뢰도 추정을 명시적으로 촉진하는 경량 미세조정 프레임워크입니다. 핵심 아이디어는 정답/오답 쌍에 대한 대조 학습을 통해 답변의 정확성에 따라 신뢰도가 근본적으로 달라져야 한다는 것을 모델에게 가르치는 것입니다.
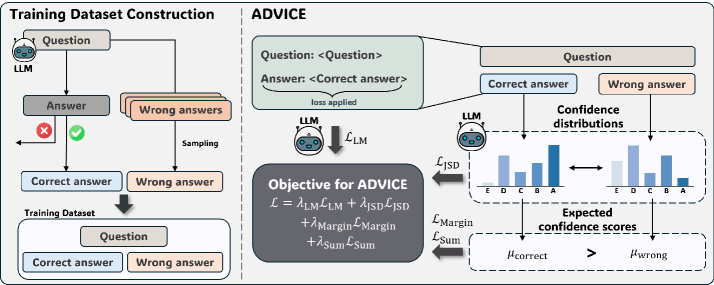
네 가지 손실 함수의 구체적 역할:
- Language Modeling Loss (L_LM): 정답에 대한 표준 음의 로그 우도로, 모델의 일반적인 QA 능력을 보존하고 미세조정 중 치명적 망각(catastrophic forgetting)을 방지합니다.
- Jensen-Shannon Divergence Loss (L_JSD): 정답과 오답 간 신뢰도 분포를 명시적으로 구별하도록 유도합니다. max(0, δ_JSD - D_JSD(P_correct || P_wrong))로 공식화되어 두 분포가 충분히 분리되도록 합니다.
- Margin Loss (L_Margin): max(0, δ_Margin - (μ_correct - μ_wrong))를 통해 방향성 분리를 강제하여, 정답에 대한 평균 신뢰도가 오답보다 최소 δ_Margin 이상 높도록 보장합니다.
- Sum Loss (L_Sum): μ_correct + μ_wrong = 1이라는 이상적 제약을 강제하여, 신뢰도가 답변 정확성의 실제 확률을 반영하도록 합니다. 모든 가중치 파라미터는 간결성을 위해 1로 설정됩니다.
실험 결과
세 가지 모델(Llama-3.1-8B-Instruct, Mistral-7B-Instruct-v0.3, Gemma-2-9b-it)을 대상으로 도메인 내(TriviaQA) 및 도메인 외(MMLU, LogiQA) 벤치마크에서 실험을 수행하며, ECE(Expected Calibration Error), |NCE|(Absolute Net Calibration Error), BS(Brier Score), AUROC의 네 가지 지표를 사용합니다.
도메인 내 결과 (TriviaQA)
| 모델 | 방법 | ECE ↓ | |NCE| ↓ | BS ↓ | AUROC ↑ |
|---|---|---|---|---|---|
| Llama-3.1-8B | Default | 16.9 | 16.6 | 21.2 | 56.2 |
| Llama-3.1-8B | Self-Consistency | 15.7 | - | - | 58.6 |
| Llama-3.1-8B | ConfTuner | 5.2 | 1.1 | 15.3 | 66.3 |
| Llama-3.1-8B | ADVICE | 10.4 | 9.8 | 14.8 | 77.0 |
| Llama-3.1-8B | ADVICE + ConfTuner | 9.4 | - | - | 77.9 |
도메인 외 결과 (Out-of-Distribution)
| 데이터셋 | 방법 | ECE ↓ | AUROC ↑ |
|---|---|---|---|
| MMLU | Default | 26.9 | - |
| MMLU | ConfTuner | 13.9 | - |
| MMLU | ADVICE | 8.6 | 69.2 |
| LogiQA | Default | 53.8 | - |
| LogiQA | ConfTuner | 28.6 | - |
| LogiQA | ADVICE | 23.0 | 57.9 |
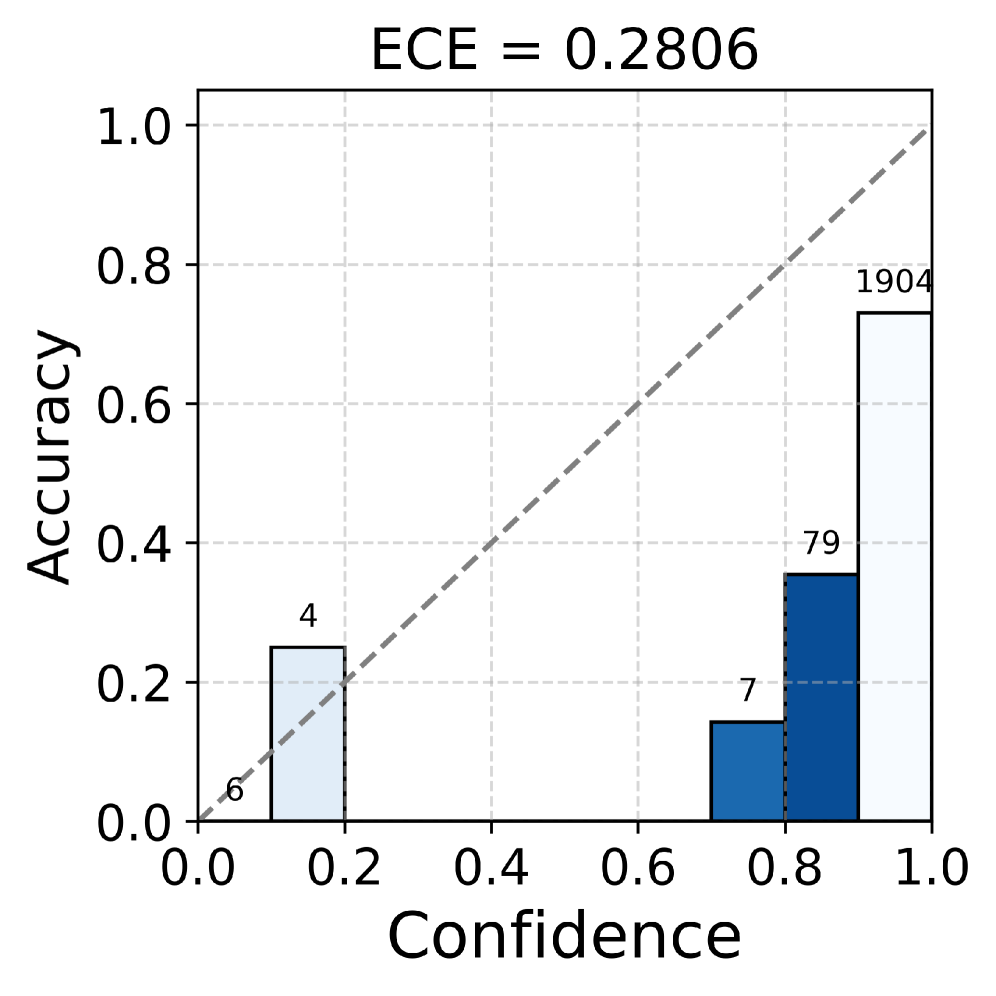
절삭 연구 (Gemma-2-9b, TriviaQA)
| 구성 | ECE ↓ |
|---|---|
| L_LM만 사용 | 23.0 |
| L_LM + L_JSD | 8.6 |
| L_LM + L_Margin | 16.8 |
| 전체 ADVICE (모든 목적 함수) | 6.2 |
- OOD 일반화: MMLU와 LogiQA에서 24개 도메인 외 설정 중 19개에서 ConfTuner를 능가하며 강한 견고성을 입증합니다. MMLU에서 ECE가 26.9(Default)에서 8.6(ADVICE)으로 감소하여 ConfTuner의 13.9를 크게 상회합니다.
- 효율성: ADVICE는 ECE-토큰 사용량 그래프의 좌하단 영역에 위치하여, 적은 토큰으로 낮은 ECE를 달성합니다. 반면 Self-Consistency(M=5)는 토큰 사용량을 급격히 증가시키면서도 보정 개선은 제한적입니다.
- 태스크 성능 보존: 미세조정 후 QA 정확도가 유지되거나 소폭 향상됩니다. Llama-3.1은 75.2% → 78.1%, Gemma-2는 70.7% → 71.7%로, 핵심 능력의 저하가 없음을 확인합니다.
- 형식 간 일반화: 두 가지 신뢰도 형식(ScoreLetter, ScoreNumber)으로만 학습했음에도, 미학습 형식으로 일반화됩니다: Gemma-2에서 ScoreText (ECE 8.3), ScorePercent (ECE 6.7), ScoreFloat (ECE 6.2).
- 답변 인식 검증: 답변 마스킹 실험에서 기본 모델은 답변을 패딩으로 대체해도 높은 값에 치우친 신뢰도를 생성하지만, ADVICE 학습 모델은 답변이 마스킹되면 신뢰도가 크게 하락하여 실제로 답변 인식이 강화되었음을 입증합니다. Attention Rollout 점수도 학습 후 답변 토큰 방향으로 유의미하게 증가합니다.
왜 중요한가?
AI가 "확실합니다"라고 말할 때 정말 확신하는 것인지 아는 것은 매우 중요합니다. 의료, 법률, 금융과 같은 고위험 분야에서 LLM의 과신은 심각한 실제 결과를 초래할 수 있습니다 -- 사용자가 잘못된 출력을 의심 없이 신뢰할 수 있기 때문입니다.
본 연구는 기존 접근법을 넘어 세 가지 핵심 기여를 합니다:
- 메커니즘적 통찰: 과신을 블랙박스 현상으로 다루는 대신, 분포 분석, Attention Rollout, Integrated Gradients를 활용하여 과신을 유발하는 구체적인 내부 메커니즘(답변 독립성)을 식별하고 엄밀하게 검증합니다.
- 실용적이고 경량인 해결책: ADVICE는 단일 데이터셋(TriviaQA)의 4,000개 학습 인스턴스만으로도 미학습 데이터셋, 모델, 신뢰도 형식으로 일반화되어 실제 배포에 매우 실용적입니다.
- 신뢰할 수 있는 AI의 토대: 신뢰도를 실제 답변에 기반시킴으로써, 사용자가 표현된 신뢰도 수준을 의미 있게 활용할 수 있는 시스템의 기반을 마련하여, 더 나은 인간-AI 협업과 핵심 응용 분야에서의 안전한 LLM 배포를 가능하게 합니다.