One-Line Summary
A cross-sentence latent variable model (CS-LVM) that generates a target sentence conditioned on a source sentence and their relationship label, enabling principled semi-supervised training for natural language inference and paraphrase identification with novel semantic constraints for diverse and plausible generation.
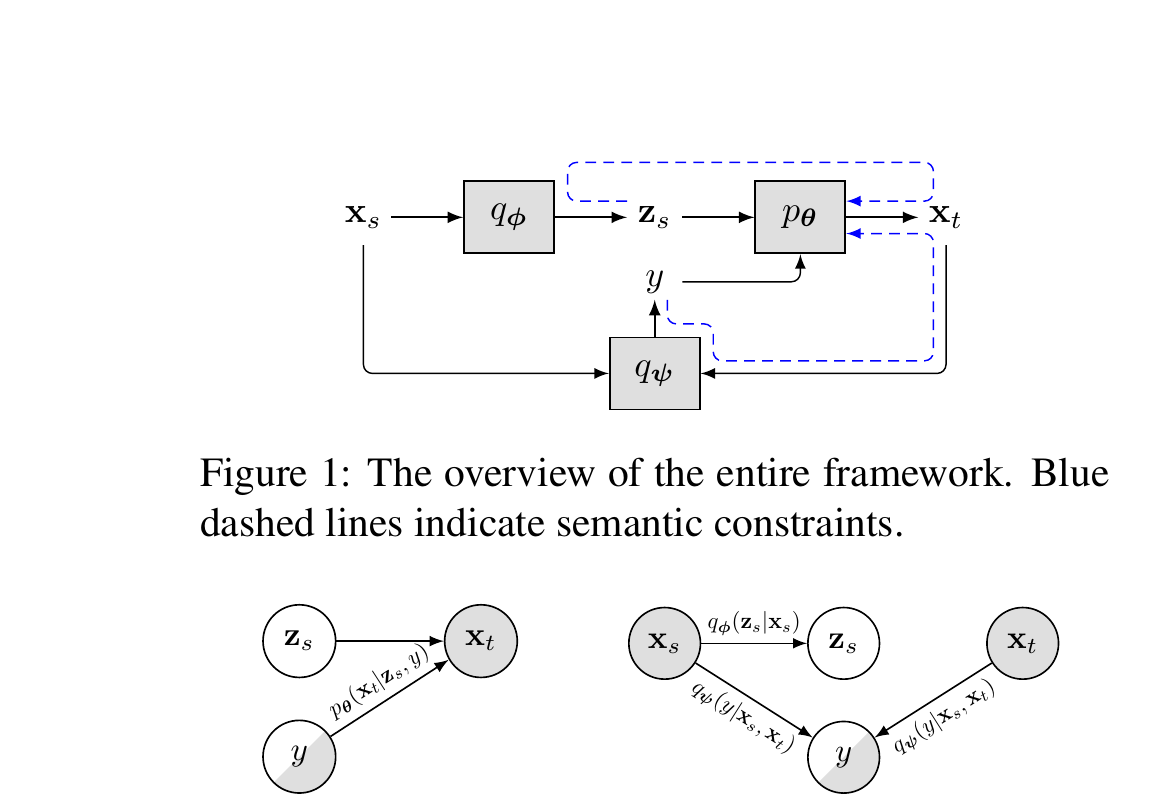
Background & Motivation
Text sequence matching — predicting the relationship between two text sequences such as entailment, contradiction, or paraphrase — is a fundamental NLP task that underpins answer sentence selection, text retrieval, and machine comprehension. While deep neural models have achieved remarkable results on these tasks, they require abundant labeled training data, which is time-consuming and labor-intensive to construct. Semi-supervised learning paradigms that leverage unlabeled data offer a promising solution, but prior VAE-based approaches for text pair modeling treat each sentence independently within the auto-encoding framework, limiting the interaction between the generative model and the discriminative classifier.
Limitation of Prior Work: Existing VAE-based semi-supervised matching models (e.g., LSTM-VAE, DeConv-VAE) encode and reconstruct each sentence in a pair separately. This means the generative modeling process is confined within a single sequence, and pair-wise information is only considered through the classifier network. In the unsupervised setting, only the reconstruction objective is used for training, so the classifier parameters are not updated and the interaction between the encoder and classifier is restricted. Each sentence is mapped to its own latent variable and decoded back to itself, so the generative model never learns about the relationship between two sentences.
Key Insight: This work proposes cross-sentence generation: instead of reconstructing each sentence independently, the model generates a target sentence that has a given relationship with a source sentence. This mirrors the actual dataset construction process (e.g., in SNLI, annotators write hypotheses given a premise and a label), naturally integrating both sequences and the label within a single generative model and enabling stronger interaction between generation and classification.
Problem Setting
Given a dataset of sentence pairs {(x_1, x_2)} where some pairs have relationship labels y (e.g., entailment, neutral, contradiction for NLI; paraphrase or non-paraphrase for QQP) and others are unlabeled, the goal is to train a classifier that predicts y for unseen sentence pairs. The semi-supervised setting is realistic because obtaining large-scale labeled sentence pair datasets is expensive, while vast amounts of unlabeled text pairs can be collected cheaply. The challenge is to design a framework where the generative component (modeling unlabeled data) and the discriminative component (classifying relationships) reinforce each other through shared representations.
Proposed Method
The Cross-Sentence Latent Variable Model (CS-LVM) is built on deep probabilistic generative models (VAEs) but fundamentally differs from prior approaches by generating text across sentence pairs rather than within individual sentences. The model uses a von Mises-Fisher (vMF) distribution instead of Gaussian for the latent space, which avoids the posterior collapse problem inherent to standard VAEs.
Training Procedure: Training proceeds in two phases. Phase 1 (Pre-training): The full model (encoder, decoder, classifier) is trained jointly with the combined supervised and unsupervised ELBO objectives until convergence. Phase 2 (Fine-tuning): The semantic constraints R^y, R^z, and R^μ are added to the loss function and the model is fine-tuned further. This two-phase strategy is necessary because the semantic constraints rely on a reasonably well-trained generator and classifier to provide meaningful gradient signals.
Experimental Results
The model is evaluated on two semi-supervised tasks: natural language inference (SNLI, ~570k pairs, 3-way classification) and paraphrase identification (Quora Question Pairs, ~400k pairs, binary classification). Following prior work, experiments use limited labeled subsets with the remainder as unlabeled data, a vocabulary of 20,000 words, and no pre-trained embeddings. This controlled setting isolates the contribution of the semi-supervised framework from the effects of large-scale pre-trained representations.
Semi-Supervised NLI (SNLI Dataset)
| Model | 28k | 59k | 120k |
|---|---|---|---|
| LSTM | 57.9 | 62.5 | 65.9 |
| CNN | 58.7 | 62.7 | 65.6 |
| LSTM-AE | 59.9 | 64.6 | 68.5 |
| LSTM-VAE | 64.7 | 67.5 | 71.1 |
| DeConv-VAE | 67.2 | 69.3 | 72.2 |
| LSTM-vMF-VAE (ours) | 65.6 | 68.7 | 71.1 |
| CS-LVM (ours) | 68.4 | 73.5 | 76.9 |
| CS-LVM + all constraints | 69.6 | 74.1 | 77.4 |
Semi-Supervised Paraphrase Identification (QQP Dataset)
| Model | 1k | 5k | 10k | 25k |
|---|---|---|---|---|
| CNN | 56.3 | 59.2 | 63.8 | 68.9 |
| LSTM-AE | 60.2 | 65.1 | 67.7 | 71.6 |
| DeConv-VAE | 65.1 | 69.4 | 70.5 | 73.7 |
| LSTM-vMF-VAE (ours) | 65.0 | 69.9 | 72.1 | 74.9 |
| CS-LVM (ours) | 66.5 | 71.1 | 74.6 | 76.9 |
| CS-LVM + all constraints | 66.3 | 71.3 | 74.7 | 77.6 |
Ablation: Individual Constraint Effects (SNLI, 59k labels)
| Configuration | Accuracy |
|---|---|
| CS-LVM (no constraints) | 73.5 |
| + R^y only | 73.8 |
| + R^z only | 73.6 |
| + R^μ only | 73.6 |
| + R^y + R^z | 73.9 |
| + R^y + R^z + R^μ (all) | 74.1 |
Ablation: Architectural Choices (SNLI, 59k labels)
| Variant | Accuracy |
|---|---|
| CS-LVM (full) | 73.5 |
| Without cross-sentence generation | 68.7 |
| Without encoder sharing | 70.1 |
| Gaussian instead of vMF | 72.8 |
Generation Quality Analysis
| Model | Artificial Acc. | Distinct-1 | Distinct-2 |
|---|---|---|---|
| CS-LVM (no constraints) | 76.5% | 0.042 | 0.170 |
| + R^y | 81.9% | 0.043 | 0.173 |
| + R^y + R^z + R^μ | 81.2% | 0.048 | 0.202 |
Artificial Acc. measures whether a separately trained classifier correctly identifies the relationship label of generated pairs. Distinct-1/2 measure the ratio of unique unigrams/bigrams to total tokens, indicating generation diversity.
- State-of-the-Art on Both Tasks: CS-LVM substantially outperforms all prior auto-encoding-based models on both SNLI and QQP in every labeled data setting, with improvements of up to 5+ accuracy points over the previous best (DeConv-VAE). The gap is especially large in low-label regimes, confirming that cross-sentence generation is particularly effective when labeled data is scarce
- Cross-Sentence Generation is the Key Factor: The ablation study reveals that removing cross-sentence generation (reverting to within-sentence auto-encoding) causes the largest performance drop of ~4.8 points. Encoder weight sharing between the generative model and classifier is the second most critical factor (~3.4 point drop when removed)
- Semantic Constraints Add Further Gains: Fine-tuning with R^y, R^z, and R^μ provides additional performance boosts. R^y (label consistency) contributes the largest accuracy improvement by ensuring generated sentences faithfully reflect the conditioned relationship, while R^z and R^μ primarily enhance generation diversity as measured by distinct-1/distinct-2 metrics
- Full Supervision Benefit: Even with all ~550k SNLI labels, CS-LVM achieves 82.8% accuracy, surpassing supervised LSTM (81.5%), LSTM-AE (81.6%), and DeConv-VAE (80.9%), showing that the cross-sentence generative framework provides a better inductive bias even when unlabeled data is not needed
- vMF vs. Gaussian: Replacing vMF with Gaussian slightly hurts accuracy (73.5 vs. 72.8) and also requires careful KL cost annealing to avoid posterior collapse. The vMF distribution offers a simpler, more stable training procedure while maintaining strong performance
- Generation Quality: Generated sentences properly reflect conditioned labels. Fine-tuning with R^y increases artificial dataset classification accuracy from 76.5% to 81.9%, confirming that the label consistency constraint effectively teaches the generator to produce label-faithful outputs. R^z and R^μ further improve diversity (distinct-2 rises from 0.170 to 0.202)
Why It Matters
This work introduced the first cross-sentence generating latent variable model for semi-supervised text sequence matching, demonstrating that jointly modeling both sentences in a pair through generation leads to fundamentally stronger semi-supervised learning than treating sentences independently. The key architectural insight — that the generative process should mirror how datasets are actually constructed (generating a target given a source and a label) — enables much tighter integration between the generative model and the discriminative classifier, allowing unlabeled data to provide meaningful training signal to the classifier through shared encoder weights.
Beyond classification performance, the work also contributed novel semantic constraints (label consistency, latent alignment, diversity) that improve both the quality and diversity of generated text. These ideas of cross-sentence generation, vMF latent spaces to avoid posterior collapse, and semantic fine-tuning constraints remain relevant to modern generative approaches for data augmentation and controlled text generation in low-resource NLP settings.
From a broader perspective, this paper demonstrated an important principle for semi-supervised learning with structured outputs: the generative model should capture the relational structure of the data rather than modeling individual data points in isolation. This insight has since been echoed in later work on conditional text generation, data augmentation for NLU, and contrastive learning for sentence pairs, where explicitly modeling inter-sentence relationships leads to more effective representation learning. The work was published at ACL 2019, one of the top venues in natural language processing, and presented at the 57th Annual Meeting of the Association for Computational Linguistics in Florence, Italy.