One-Line Summary
A fully unsupervised constituency parsing method that ranks and ensembles transformer self-attention heads based on their inherent syntactic properties, achieving competitive parsing performance without any labeled data or development set, while also enabling analysis of the implicit grammars learned by pre-trained language models.
Background & Motivation
Constituency parsing — decomposing a sentence into nested sub-phrases such as noun phrases (NP), verb phrases (VP), and prepositional phrases (PP) — is fundamental to understanding sentence structure. Traditional supervised parsers require expensive treebank annotations such as the Penn Treebank (PTB), which contains roughly 40,000 hand-annotated sentences of Wall Street Journal text. Unsupervised parsers attempt to recover this hierarchical structure without labeled data, but have historically lagged far behind their supervised counterparts.
Meanwhile, probing studies have revealed that pre-trained language models (PLMs) like BERT encode surprisingly rich syntactic information in their internal representations. A natural question arises: can we directly extract parse trees from PLM attention patterns, rather than merely probing for syntactic features? Prior work by Kim et al. (2020) showed that individual BERT attention heads can produce constituency trees, but required a labeled development set to select the best head — a critical limitation that undermines the unsupervised premise.
Key Gaps Addressed by This Work:
- Probe limitations: Prior work on analyzing syntax in PLMs relied on external probing classifiers (e.g., linear probes over hidden states) or curated test suites (e.g., subject-verb agreement), which themselves introduce confounds — a high-performing probe may reflect the probe's capacity rather than the model's knowledge — and cannot directly produce parse trees.
- Development set dependency: Existing unsupervised parsing methods that leverage PLMs (e.g., selecting the single best attention head via oracle comparison) require a labeled development set to choose hyperparameters, undermining the truly unsupervised setting. In practice, this means you need a treebank to do “unsupervised” parsing — a contradictory requirement.
- Low-resource applicability: For low-resource languages with no treebanks at all — the vast majority of the world's 7,000+ languages — a method that needs no development data is essential, yet no prior approach could operate under this constraint.
- Interpretability gap: There was no principled way to compare the implicit grammars learned by different PLMs against human-annotated treebanks at the grammar rule level (not just tree accuracy), limiting our understanding of what these models actually learn about syntax.
This paper addresses all four gaps by proposing a method that (1) directly extracts constituency trees from attention patterns, (2) requires no development set or labeled data, (3) works across different PLMs and languages, and (4) enables grammar-level analysis through induced PCFGs. The key insight is that syntactic information is distributed across many attention heads, and that an unsupervised criterion based on tree structure quality can identify and combine the most informative ones.
Proposed Method
The approach consists of three stages: computing span scores from attention matrices, ranking and selecting the most syntactically informative heads without supervision, and constructing trees via a greedy top-down algorithm. An optional fourth stage induces explicit grammars for analysis purposes.
For each attention head h at layer l, the method computes a syntactic affinity score for every possible text span (i, j) in a sentence of length n. Given the attention matrix A of shape n × n, the span score captures how much tokens within the span attend to each other versus tokens outside it. Formally, for a span from position i to j, the score is computed as the ratio of intra-span attention mass (total attention that tokens in positions i..j pay to other tokens in i..j) to the total attention from those tokens. High scores indicate that the tokens form a self-contained attention cluster, which is the expected signature of a syntactic constituent — words within a phrase like “the big red ball” should attend primarily to each other.
This score is computed for all O(n2) possible spans in the sentence, yielding a complete span score chart for each attention head. The chart is analogous to the chart used in CKY parsing, but here the scores come from pre-trained attention patterns rather than learned grammar rules.
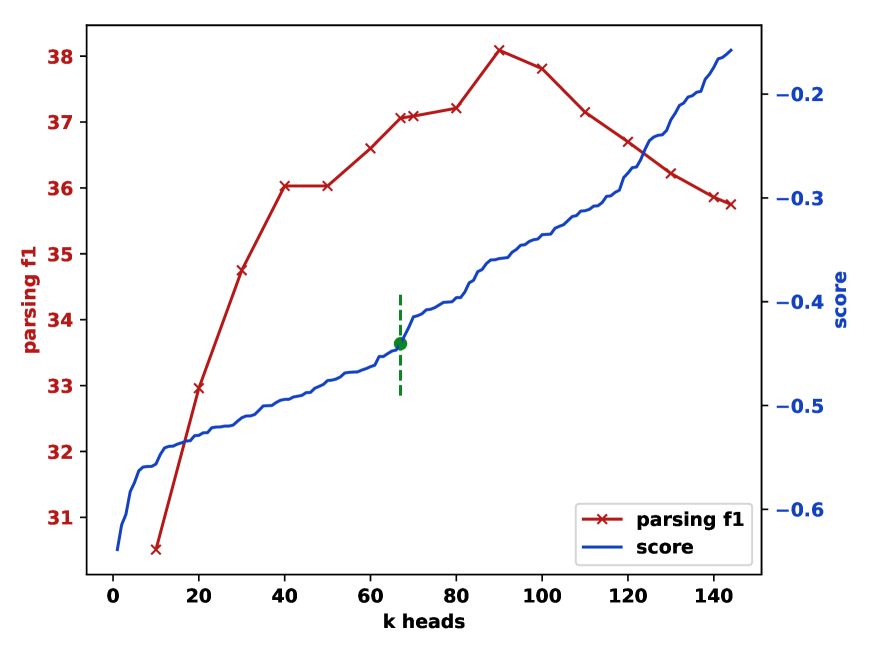
Not all attention heads encode syntax — many attend to positional patterns (e.g., attending to the previous or next token), punctuation, or semantic relations. The paper introduces an unsupervised ranking criterion based on the structural properties of each head's induced trees.
The criterion measures the branching entropy of the trees a head produces across a corpus: a head that always produces left-branching trees (equivalent to always splitting off the first word) or always right-branching trees (splitting off the last word) receives a low score, because such trees are trivially degenerate and carry no real syntactic information. In contrast, a head whose trees exhibit varied, non-trivial branching patterns — sometimes splitting left, sometimes right, depending on the actual sentence structure — receives a high score, as this variability indicates genuine sensitivity to syntax.
The top-K heads (typically K = 5–15) are then ensembled by averaging their span scores element-wise, creating a robust composite signal that benefits from complementary syntactic information across different heads and layers. This ranking requires no labeled data or development set — only unlabeled text from the target domain.
Given the ensembled span scores, a greedy top-down algorithm recursively builds the constituency tree. Starting from the full sentence span (1, n), the algorithm finds the split point k that maximizes the sum of the scores of the two resulting sub-spans: score(1, k) + score(k+1, n). It then recurses on each sub-span, continuing until reaching individual tokens (spans of length 1).
This produces an unlabeled binary constituency tree. The algorithm has O(n2) time complexity per sentence (linear scan for the split point at each level of recursion), making it highly efficient compared to chart-parsing approaches. The resulting trees are binarized — each internal node has exactly two children — which is standard for evaluation against gold-standard binarized trees from the PTB.
As an additional analysis tool, the induced parse trees are used as supervision to train a neural PCFG (Probabilistic Context-Free Grammar) following the compound PCFG framework of Kim et al. (2019). The neural PCFG learns explicit production rules (e.g., S → NP VP, NP → DT NN) with associated probabilities, parameterized by neural networks.
This allows quantitative comparison of the implicit grammars captured by different PLMs: by training separate PCFGs on trees induced from BERT, GPT-2, XLNet, etc., one can compare the resulting rule distributions against the human-annotated grammar from the PTB. The comparison reveals which phrase types each model captures well (e.g., NPs vs. VPs), which constructions are problematic, and how the implicit grammars of different PLM architectures systematically differ.
Experimental Results
The method is evaluated on the WSJ10 (sentences ≤ 10 words) and WSJ test sets (section 23, all lengths) from the Penn Treebank, comparing against both traditional unsupervised parsers and PLM-based approaches. Multiple PLMs are tested, including BERT (base/large, cased/uncased), GPT-2, XLNet, and RoBERTa. All results use unlabeled F1 as the evaluation metric.
Unsupervised Parsing F1 on PTB (No Development Set)
| Method | WSJ10 F1 | WSJ Test F1 |
|---|---|---|
| PRPN (Shen et al., 2018) | 70.5 | 38.3 |
| ON-LSTM (Shen et al., 2019) | 65.1 | 47.7 |
| URNNG (Kim et al., 2019) | 73.6 | 51.6 |
| Single Best Head (oracle) | — | 52.1 |
| Heads-up! (Ours, BERT-base) | 69.5 | 49.4 |
| Heads-up! (Ours, BERT-large) | 71.3 | 50.8 |
Note that the “Single Best Head (oracle)” result requires a labeled development set to identify which head is best — making it not truly unsupervised. The proposed method achieves 50.8 F1 with BERT-large without any such supervision, closing the gap to within 1.3 F1 of the oracle head selection.
Performance Across Different PLMs
| Pre-Trained Model | WSJ Test F1 | Total Heads | Selected K |
|---|---|---|---|
| BERT-base-cased | 49.4 | 144 | ~10 |
| BERT-base-uncased | 48.2 | 144 | ~10 |
| BERT-large-cased | 50.8 | 384 | ~15 |
| GPT-2 | 40.1 | 144 | ~10 |
| XLNet-base | 45.7 | 144 | ~10 |
| RoBERTa-base | 47.3 | 144 | ~10 |
Layer-wise Analysis
Where does syntax live in PLMs?
The head ranking analysis reveals a clear pattern across all tested models:
- Early layers (1–3): Dominated by positional attention heads — attending to the previous token, next token, or first token. These produce nearly left- or right-branching trees and score low on the ranking criterion.
- Middle layers (4–8): Contain the highest-ranked heads. These heads exhibit variable branching patterns that correlate with actual syntactic structure. They often specialize in specific constituent types (e.g., one head may be particularly good at identifying NPs while another captures VPs).
- Late layers (9–12): Attention patterns become more diffuse and semantically oriented. These heads often attend to related words across long distances (e.g., coreference-like patterns) rather than forming tight syntactic clusters.
Grammar Induction Analysis
The neural PCFG analysis yields insights into how different PLMs conceptualize sentence structure:
- BERT vs. PTB grammar: BERT's induced grammar tends to produce flatter structures for verb phrases — merging the subject with the verb more often than PTB's VP-internal subject analysis. This suggests BERT organizes clause-level structure differently from linguistic convention.
- NP identification: All tested PLMs show relatively strong agreement with PTB on noun phrase boundaries. NPs are among the most consistently identified constituent types, likely because the attention mechanism naturally clusters determiners, adjectives, and head nouns.
- PP attachment: Prepositional phrase attachment remains ambiguous in PLM-induced trees, mirroring a well-known difficulty in both human parsing and NLP systems.
- Competitive without dev set: Despite using no labeled data at all, the method achieves F1 scores competitive with unsupervised parsers like PRPN and ON-LSTM, and approaches URNNG which uses a more complex training procedure involving variational inference.
- Closing the oracle gap: BERT-large achieves 50.8 F1 vs. the oracle single-head selection of 52.1 F1. The proposed unsupervised ranking nearly matches oracle head selection while requiring zero labeled data, confirming that the branching entropy criterion is an effective proxy for syntactic quality.
- Head ensemble beats single head: Ensembling the top-K ranked heads consistently outperforms using any single head (even the oracle-selected best head in some configurations), confirming that syntactic information is distributed across multiple heads and that combining complementary signals is beneficial.
- BERT > GPT-2 for syntax: Bidirectional models (BERT, RoBERTa) consistently outperform unidirectional models (GPT-2) at constituency parsing by a substantial margin (~9 F1 points). This suggests that bidirectional attention is critical for capturing the nested, hierarchical structure of constituents, since a left-to-right model cannot attend to future tokens that complete a phrase.
- Cased vs. uncased: BERT-base-cased slightly outperforms BERT-base-uncased (49.4 vs. 48.2), suggesting that capitalization provides useful syntactic cues (e.g., sentence-initial words, proper nouns) that aid parsing.
- Efficiency: The method requires no training and runs in a single forward pass through the PLM plus O(n2) parsing per sentence, making it fast enough for large-scale application. Processing the entire WSJ test set takes only minutes on a single GPU.
Why It Matters
This work makes several important contributions at the intersection of unsupervised parsing and PLM interpretability:
- Truly unsupervised parsing: Unlike prior PLM-based parsing methods that require a development set for head selection, this approach needs no labeled data whatsoever. This makes it directly applicable to low-resource languages where no treebank annotations exist — a practitioner can simply run a multilingual PLM on raw text to obtain constituency analyses.
- Principled PLM analysis: By extracting constituency trees and training PCFGs from them, the method provides a systematic way to compare the syntactic knowledge encoded in different PLMs at the grammar rule level — going beyond probing classifiers to reveal what kind of grammars these models implicitly learn and where they deviate from human linguistic annotations.
- Evidence for distributed syntax: The finding that syntactic information is distributed across multiple attention heads (not concentrated in a single head) and that middle layers are most syntactically informative has informed subsequent research on model pruning, distillation, and architecture design for syntax-sensitive tasks. This layer-wise characterization (positional → syntactic → semantic) has become a widely cited reference point in the PLM interpretability literature.
- Bridging probing and generation: The work bridges two previously separate research threads: structural probing of PLMs (which analyzes but does not produce outputs) and unsupervised grammar induction (which produces parses but did not leverage PLMs). By showing that attention heads directly yield competitive parses, the paper opened a new line of research on extraction-based analysis of transformer internals.
- Practical baseline: The method serves as a strong, zero-cost baseline for unsupervised parsing: it requires no training, no hyperparameter tuning on labeled data, and runs efficiently at inference time. This makes it a convenient tool for bootstrapping syntactic resources in new languages or domains.