One-Line Summary
HEAVEN is a two-stage hybrid retrieval framework that introduces Visually-Summarized Pages and query token filtering to achieve 99.87% of multi-vector Recall@1 while reducing per-query computation by 99.82%, enabling scalable retrieval over visually rich documents.
Background & Motivation
Visually rich documents—PDFs containing tables, charts, figures, and complex layouts—are central to legal discovery, scientific search, and enterprise knowledge management. Traditional text-based retrieval fails on such content because crucial information is embedded in visual elements, not extractable text. Large Vision-Language Models (LVLMs) have enabled a new paradigm of direct image-based page encoding that bypasses OCR entirely, but existing approaches present a stark trade-off:
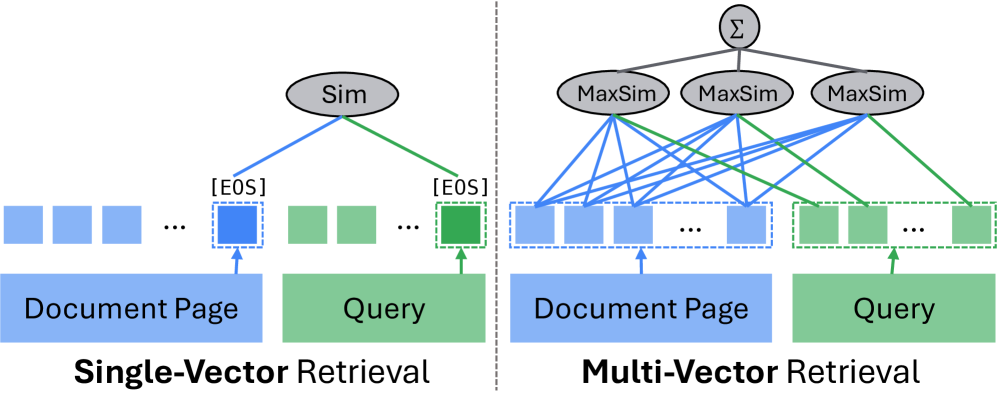
- Single-vector retrieval (e.g., DSE, GME) encodes each page as one embedding and uses efficient dot-product similarity, requiring only O(d|P|) operations. However, it produces coarse representations that miss fine-grained visual details.
- Multi-vector retrieval (e.g., ColQwen2.5, ColPali) preserves token/patch-level embeddings and computes MaxSim interactions for fine-grained matching. This achieves high accuracy but requires O(d·n_q·Σn_P) operations—orders of magnitude more expensive.
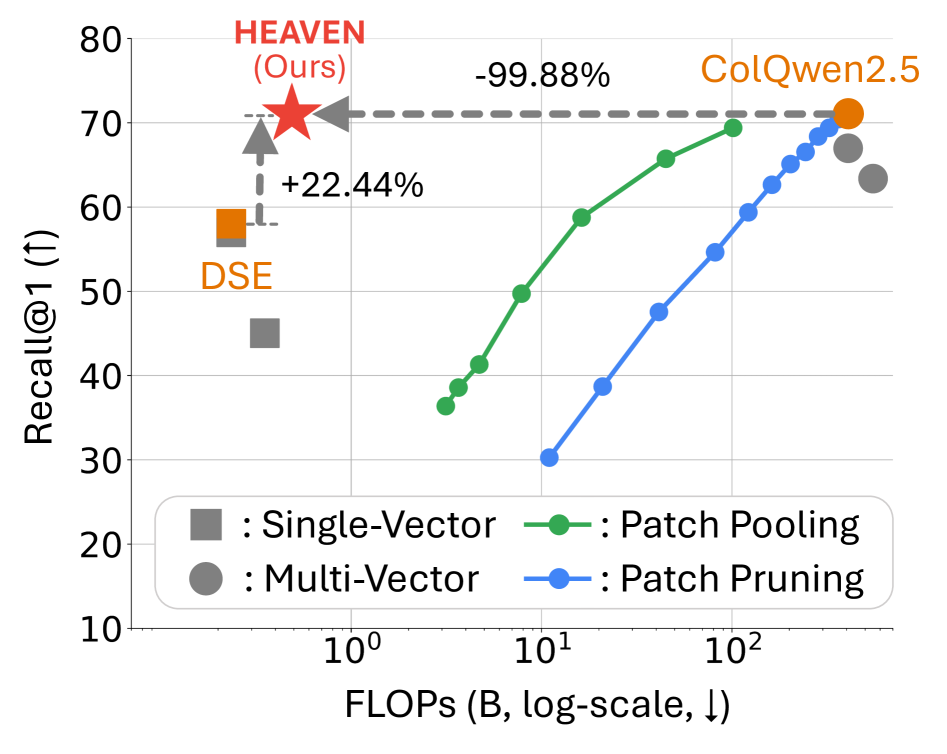
A key observation motivates HEAVEN: the performance gap between the two paradigms shrinks dramatically when retrieving larger candidate sets. On ViMDoc, the gap is 22.5% at Recall@1 but narrows to only 0.63% at Recall@200. This suggests that single-vector methods can reliably identify a broad set of candidates, which a targeted multi-vector reranker can then refine.
Core Insight: Single-vector retrieval already captures most relevant pages at moderate recall depths. By combining efficient single-vector candidate generation with focused multi-vector reranking on only key query tokens, we can achieve near-optimal accuracy at a fraction of the cost.
Proposed Method: HEAVEN Framework
HEAVEN (Hybrid-vector retrieval for Efficient and Accurate Visual multi-documENt) is a two-stage framework with two key innovations: Visually-Summarized Pages (VS-Pages) that reduce index size while preserving visual information, and POS-based query token filtering that eliminates redundant multi-vector computation.
Candidate Scoring: Single-vector similarity S_SV(q, VS) = ⟨E_q, E_VS⟩ is computed over all VS-Pages. The top p1 × 100% candidates (default p1 = 0.5) are retained, expanded to their constituent pages, and refined using a combined score: S(q, P) = α · S_SV(q, Γ^{-1}(P)) + (1-α) · S_SV(q, P), with α = 0.1. The top K = 200 pages proceed to Stage 2.
Reranking: Filtered multi-vector scoring S_MV(q_key, P) = Σ_i max_j ⟨E_{q_key}^{(i)}, E_P^{(j)}⟩ reranks the K candidates. A final refinement step combines scores: S(q, P) = β · S_SV(q, P) + (1-β) · S_MV(q, P), with β = 0.3 by default, using the top p2 = 25% candidates scored with all query tokens for the final output.
ViMDoc Benchmark
The paper introduces ViMDoc, the first benchmark designed for visually rich, multi-document, long-document retrieval. Existing VDR benchmarks either restrict evaluation to single documents or use short documents, failing to capture the realistic challenge of retrieving across large document collections.
- 76,347 pages across 1,379 documents (sourced from VisR-Bench, REAL-MM-RAG, MMLongBench-Doc, MMDocIR, LongDocURL)
- 10,904 queries after two-stage filtering that removed 45.8% of context-dependent or position-dependent queries
- 55.4 pages average document length—significantly longer than existing benchmarks
- 677 cross-page queries (6.2%) requiring information from multiple pages simultaneously
Experimental Results
HEAVEN uses DSE for Stage 1 single-vector retrieval and ColQwen2.5 for Stage 2 multi-vector reranking. Results are evaluated on four benchmarks using page-level Recall@{1,3} and per-query FLOPs.
Main Results (vs. ColQwen2.5 multi-vector baseline)
| Dataset | Method | Recall@1 | Recall@3 | FLOPs (B) |
|---|---|---|---|---|
| ViMDoc | DSE (single-vec) | 58.03 | 77.08 | 0.235 |
| ColQwen2.5 (multi-vec) | 71.13 | 86.39 | 407.320 | |
| HEAVEN | 71.05 | 86.41 | 0.486 | |
| OpenDocVQA | DSE (single-vec) | 59.38 | 75.82 | 0.247 |
| ColQwen2.5 (multi-vec) | 72.63 | 86.38 | 482.049 | |
| HEAVEN | 71.56 | 84.53 | 0.541 | |
| ViDoSeek | DSE (single-vec) | 69.53 | 87.13 | 0.017 |
| ColQwen2.5 (multi-vec) | 75.57 | 91.94 | 41.514 | |
| HEAVEN | 75.04 | 91.33 | 0.623 | |
| M3DocVQA | DSE (single-vec) | 55.14 | 71.30 | 0.126 |
| ColQwen2.5 (multi-vec) | 57.99 | 78.73 | 288.507 | |
| HEAVEN | 59.31 | 78.66 | 0.545 |
Efficiency Analysis (ViMDoc)
| Method | Latency (sec/query) | FLOPs (B) |
|---|---|---|
| DSE (single-vec) | 0.115 | 0.235 |
| ColQwen2.5 (multi-vec) | 2006.361 | 407.320 |
| HEAVEN | 2.412 | 0.486 |
- 99.87% average Recall@1 of ColQwen2.5 across all four benchmarks, with 99.82% FLOPs reduction
- On M3DocVQA, HEAVEN surpasses ColQwen2.5 with 102.27% relative Recall@1, demonstrating that the hybrid approach can even outperform full multi-vector retrieval
- HEAVEN is 832x faster than ColQwen2.5 per query (2.4 sec vs. 2006 sec) while matching accuracy
- Stage 1 alone (VS-Pages only) already matches or exceeds DSE accuracy while reducing FLOPs by 40–80% through index compression
Ablation Study Highlights
- Removing VS-Pages increases Stage 1 FLOPs by 75% (0.235B vs. 0.134B on ViMDoc) with only marginal recall improvement (+0.5%)
- Removing query token filtering in Stage 2 nearly doubles FLOPs (0.871B vs. 0.486B) with negligible accuracy change (+0.03% Recall@1)
- HEAVEN outperforms four ColQwen2.5-based efficiency variants—document patch pooling, document patch pruning, query token pooling, and query token pruning—achieving the best efficiency-accuracy trade-off across all operating points
Why It Matters
As enterprises manage millions of visually rich PDF documents for legal discovery, scientific search, and knowledge management, the computational cost of multi-vector retrieval (over 2,000 seconds per query) makes it impractical at production scale. HEAVEN solves this by delivering equivalent accuracy in just 2.4 seconds per query—an 832x speedup. The framework is modular: its VS-Page construction and query token filtering techniques are model-agnostic and can be applied on top of any single-vector/multi-vector model pair. Additionally, the introduced ViMDoc benchmark fills a critical gap by enabling realistic evaluation of retrieval systems across multiple long, visually complex documents—a setting that prior benchmarks did not address.