한줄 요약
HEAVEN은 Visually-Summarized Pages와 쿼리 토큰 필터링을 도입하여 다중 벡터 Recall@1의 99.87%를 유지하면서 쿼리당 연산량을 99.82% 절감하는 2단계 하이브리드 검색 프레임워크로, 시각적으로 풍부한 문서의 대규모 검색을 가능하게 합니다.
배경 및 동기
표, 차트, 그림, 복잡한 레이아웃이 포함된 시각적으로 풍부한 문서는 법률 검색, 학술 문헌 탐색, 기업 지식 관리의 핵심 자료입니다. 핵심 정보가 텍스트가 아닌 시각적 요소에 담겨 있어 기존 텍스트 기반 검색은 효과적이지 않습니다. 대규모 비전-언어 모델(LVLM)이 OCR 없이 이미지 기반 페이지 인코딩을 가능하게 했지만, 기존 접근법들은 뚜렷한 트레이드오프를 보입니다:
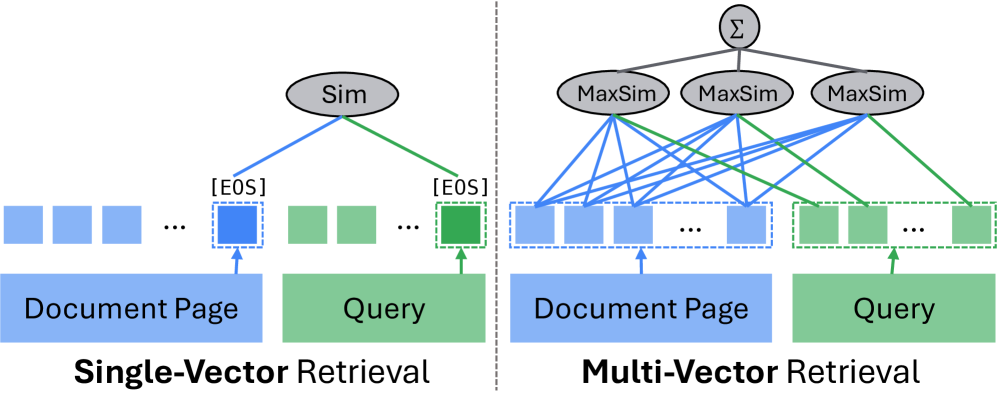
- 단일 벡터 검색(예: DSE, GME)은 각 페이지를 하나의 임베딩으로 인코딩하여 내적 유사도로 효율적으로 검색하며, O(d|P|) 연산만 필요합니다. 그러나 세밀한 시각적 디테일을 놓치는 거친 표현을 생성합니다.
- 다중 벡터 검색(예: ColQwen2.5, ColPali)은 토큰/패치 수준 임베딩을 보존하여 MaxSim 상호작용으로 세밀한 매칭을 수행합니다. 높은 정확도를 달성하지만 O(d·n_q·Σn_P) 연산이 필요하여 수 배 이상 비용이 증가합니다.
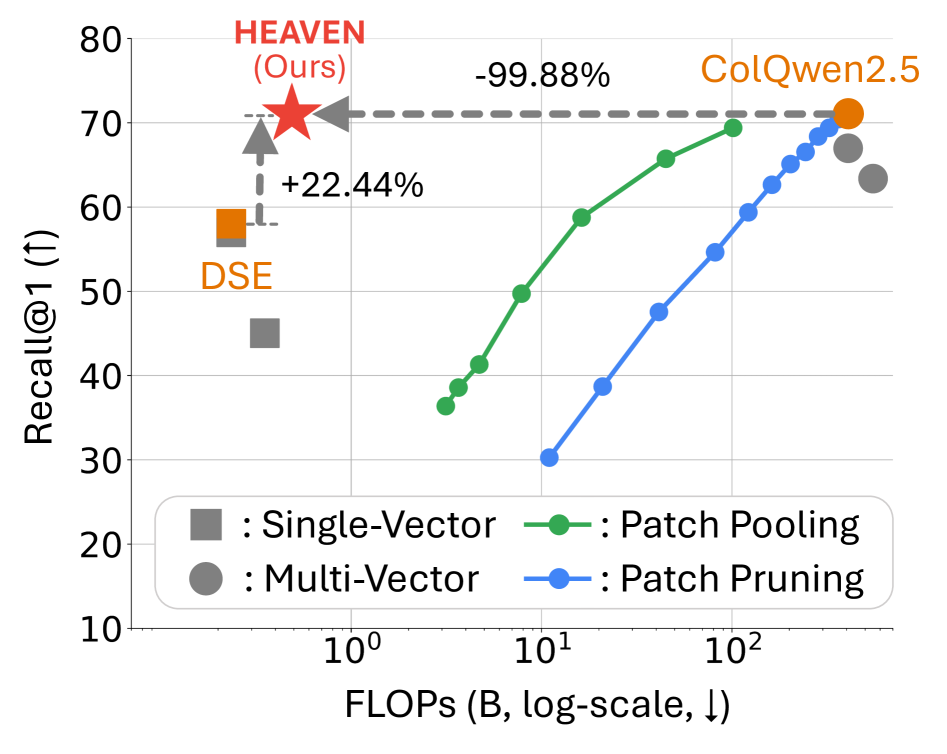
HEAVEN의 핵심 관찰: 두 패러다임 간 성능 차이는 후보 집합이 커질수록 급격히 줄어듭니다. ViMDoc에서 Recall@1 차이는 22.5%이지만, Recall@200에서는 불과 0.63%로 좁혀집니다. 이는 단일 벡터가 넓은 후보 집합을 충분히 확보할 수 있으며, 다중 벡터 재순위화로 정밀하게 보완할 수 있음을 시사합니다.
핵심 통찰: 단일 벡터 검색은 적당한 recall 깊이에서 이미 대부분의 관련 페이지를 포착합니다. 효율적인 단일 벡터 후보 생성과 핵심 쿼리 토큰에 집중하는 다중 벡터 재순위화를 결합하면, 비용의 극히 일부만으로 거의 최적의 정확도를 달성할 수 있습니다.
제안 방법: HEAVEN 프레임워크
HEAVEN(Hybrid-vector retrieval for Efficient and Accurate Visual multi-documENt)은 두 가지 핵심 혁신을 포함하는 2단계 프레임워크입니다: 시각 정보를 보존하면서 인덱스 크기를 줄이는 Visually-Summarized Pages(VS-Pages)와, 불필요한 다중 벡터 연산을 제거하는 POS 기반 쿼리 토큰 필터링입니다.
후보 스코어링: 모든 VS-Page에 대해 단일 벡터 유사도 S_SV(q, VS) = ⟨E_q, E_VS⟩를 계산합니다. 상위 p1 × 100% 후보(기본 p1 = 0.5)를 유지하고, 구성 페이지로 확장한 뒤 결합 점수 S(q, P) = α · S_SV(q, Γ^{-1}(P)) + (1-α) · S_SV(q, P) (α = 0.1)로 정제하여 상위 K = 200개 페이지를 Stage 2로 전달합니다.
재순위화: 필터링된 다중 벡터 스코어링 S_MV(q_key, P) = Σ_i max_j ⟨E_{q_key}^{(i)}, E_P^{(j)}⟩로 K개 후보를 재순위화합니다. 최종 정제 단계에서 S(q, P) = β · S_SV(q, P) + (1-β) · S_MV(q, P) (β = 0.3)로 결합하고, 상위 p2 = 25% 후보에 대해 전체 쿼리 토큰으로 최종 스코어링을 수행합니다.
ViMDoc 벤치마크
본 논문은 시각적으로 풍부한 다중 문서, 긴 문서 검색을 위한 최초의 벤치마크인 ViMDoc을 소개합니다. 기존 VDR 벤치마크는 단일 문서 내 검색으로 제한되거나 짧은 문서만 사용하여, 대규모 문서 컬렉션에서의 검색이라는 현실적인 과제를 충분히 평가하지 못했습니다.
- 1,379개 문서에 걸친 76,347 페이지 (VisR-Bench, REAL-MM-RAG, MMLongBench-Doc, MMDocIR, LongDocURL에서 수집)
- 2단계 필터링으로 문맥 의존적/위치 의존적 쿼리의 45.8%를 제거하여 10,904개 쿼리 확보
- 문서당 평균 55.4 페이지—기존 벤치마크 대비 현저히 긴 문서 길이
- 여러 페이지의 정보를 동시에 필요로 하는 677개 교차 페이지 쿼리(전체의 6.2%)
실험 결과
HEAVEN은 Stage 1에 DSE, Stage 2에 ColQwen2.5 모델을 사용합니다. 4개 벤치마크에서 페이지 수준 Recall@{1,3}과 쿼리당 FLOPs로 평가했습니다.
주요 결과 (ColQwen2.5 다중 벡터 기준 대비)
| 데이터셋 | 방법 | Recall@1 | Recall@3 | FLOPs (B) |
|---|---|---|---|---|
| ViMDoc | DSE (단일 벡터) | 58.03 | 77.08 | 0.235 |
| ColQwen2.5 (다중 벡터) | 71.13 | 86.39 | 407.320 | |
| HEAVEN | 71.05 | 86.41 | 0.486 | |
| OpenDocVQA | DSE (단일 벡터) | 59.38 | 75.82 | 0.247 |
| ColQwen2.5 (다중 벡터) | 72.63 | 86.38 | 482.049 | |
| HEAVEN | 71.56 | 84.53 | 0.541 | |
| ViDoSeek | DSE (단일 벡터) | 69.53 | 87.13 | 0.017 |
| ColQwen2.5 (다중 벡터) | 75.57 | 91.94 | 41.514 | |
| HEAVEN | 75.04 | 91.33 | 0.623 | |
| M3DocVQA | DSE (단일 벡터) | 55.14 | 71.30 | 0.126 |
| ColQwen2.5 (다중 벡터) | 57.99 | 78.73 | 288.507 | |
| HEAVEN | 59.31 | 78.66 | 0.545 |
효율성 분석 (ViMDoc)
| 방법 | 지연 시간 (초/쿼리) | FLOPs (B) |
|---|---|---|
| DSE (단일 벡터) | 0.115 | 0.235 |
| ColQwen2.5 (다중 벡터) | 2006.361 | 407.320 |
| HEAVEN | 2.412 | 0.486 |
- 4개 벤치마크 평균 ColQwen2.5 대비 Recall@1 99.87% 유지, FLOPs 99.82% 절감
- M3DocVQA에서 HEAVEN은 ColQwen2.5를 상회 (상대 Recall@1 102.27%)하여, 하이브리드 접근법이 전체 다중 벡터 검색을 능가할 수도 있음을 입증
- 쿼리당 ColQwen2.5 대비 832배 빠른 속도 (2.4초 vs. 2006초)를 달성하면서 동등한 정확도 유지
- Stage 1만으로도 (VS-Pages 단독) DSE 정확도에 필적하거나 상회하면서 인덱스 압축을 통해 FLOPs를 40~80% 절감
Ablation Study 주요 결과
- VS-Pages 제거 시 Stage 1 FLOPs가 75% 증가 (ViMDoc에서 0.235B vs. 0.134B), recall 향상은 미미 (+0.5%)
- Stage 2에서 쿼리 토큰 필터링 제거 시 FLOPs가 거의 2배 증가 (0.871B vs. 0.486B), 정확도 변화는 무시 가능 (+0.03% Recall@1)
- 문서 패치 풀링, 문서 패치 프루닝, 쿼리 토큰 풀링, 쿼리 토큰 프루닝 등 4가지 ColQwen2.5 기반 효율화 변형 대비 모든 운영점에서 최적의 효율성-정확도 트레이드오프 달성
연구의 의의
법률 검색, 학술 문헌 탐색, 지식 관리를 위해 수백만 건의 시각적으로 풍부한 PDF 문서를 다루는 기업 환경에서, 다중 벡터 검색의 쿼리당 2,000초 이상의 연산 비용은 프로덕션 배포를 사실상 불가능하게 합니다. HEAVEN은 쿼리당 단 2.4초만으로 동등한 정확도를 달성하여 832배의 속도 향상을 제공합니다. 이 프레임워크는 모듈형 설계로, VS-Page 구성과 쿼리 토큰 필터링 기법은 모델에 구애받지 않아 어떤 단일 벡터/다중 벡터 모델 조합에도 적용할 수 있습니다. 또한 도입된 ViMDoc 벤치마크는 여러 개의 긴 시각적 복합 문서에 걸친 검색 시스템의 현실적 평가를 가능하게 하여, 기존 벤치마크가 다루지 못한 중요한 공백을 채웁니다.