One-Line Summary
Hanja-level SISG enriches Korean word embeddings by incorporating Hanja (Chinese character) n-grams into the Skip-gram scoring function, optionally initializing them with pre-trained Chinese embeddings for cross-lingual transfer, and demonstrates gains on word analogy, word similarity, news headline generation, and sentiment analysis.
Background & Motivation
Korean and Chinese share a deep historical and cultural connection. A set of logograms very similar to Chinese characters, called Hanja, served as the sole medium for written Korean until Hangul was created in 1443. As a result, a substantial portion of Korean words are Sino-Korean (한자어) -- words of Chinese origin that can be written in both Hanja and Hangul, with the latter now commonplace in modern Korean.
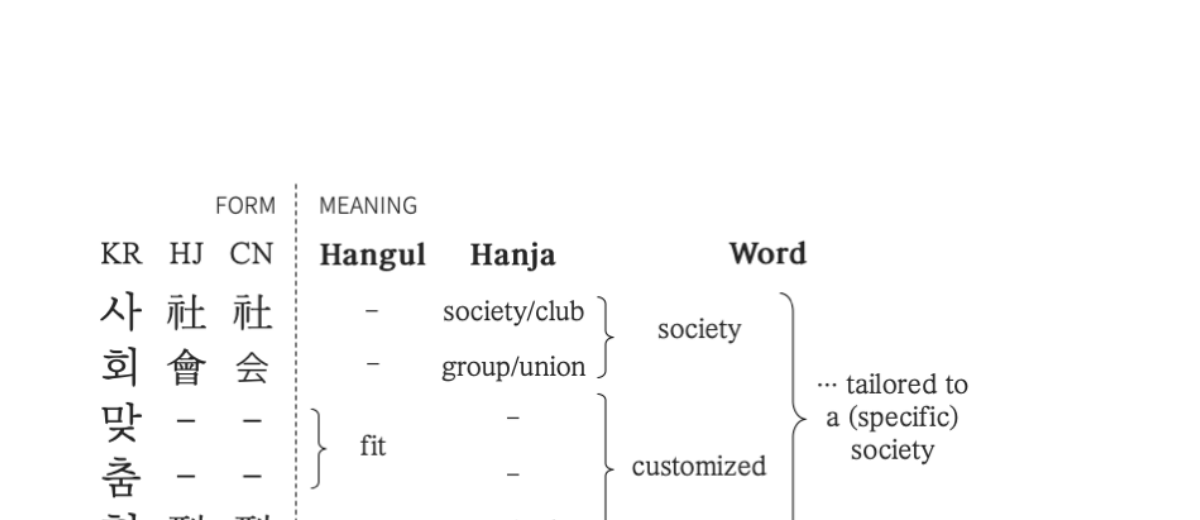
Phonograms vs. Logograms: Korean Hangul characters are phonograms -- they encode pronunciation but not meaning. In contrast, Hanja characters are logograms, where each character carries its own lexical meaning. For example, the word "사회맞춤형" contains the Hanja sequence 社會 (society) and 型 (type/style), while the Hangul syllables "맞춤" (customized) have no Hanja equivalent. This semantic richness of Hanja is invisible to standard word embeddings that only operate on Hangul surface forms.
Limitation of Existing Subword Methods: Prior approaches for Korean word representations -- character-level (syllable) n-grams (Bojanowski et al., 2017) and jamo-level n-grams (Park et al., 2018) -- capture orthographic patterns at the surface level but miss the deeper semantic structure encoded in Hanja origins. The agglutinative nature of Korean further limits the effectiveness of these surface-only methods, as sub-character and inter-character information specific to Korean understanding remains uncaptured.
Key Insight -- Cross-Lingual Transfer via Hanja: Since Hanja characters share deep roots with Chinese characters (with many having one-to-one correspondence), mapping Korean words to their Hanja equivalents creates a bridge to Chinese. This enables character-level cross-lingual knowledge transfer: pre-trained Chinese character embeddings (Li et al., 2018) can be used to initialize Hanja n-gram vectors, injecting semantic knowledge across languages without any parallel corpus. This is the first work to introduce character-level cross-lingual transfer learning based on etymological grounds.
The paper's core hypothesis is simple yet powerful: native Koreans intuitively use Hanja to resolve the ambiguity of Sino-Korean words, because each Hanja logogram contains more lexical meaning than its Hangul phonogram counterpart. Can we replicate this human heuristic in word embeddings?
Proposed Method
The proposed model, Hanja-level SISG (Hanja-level Subword Information Skip-Gram), extends the Skip-gram framework by progressively incorporating three levels of subword information into the scoring function. The architecture builds on existing work -- SG (Mikolov et al., 2013), SISG (Bojanowski et al., 2017), and Jamo-level SISG (Park et al., 2018) -- adding a new Hanja n-gram level on top.
- Additive Composition: All three levels of n-gram vectors are summed with the context vector via dot products in the scoring function -- a clean, modular extension of the standard Skip-gram objective trained with negative sampling
- Separate Vocabulary: Unlike approaches using shared BPE vocabulary, Hanja n-grams form a separate vocabulary from Hangul n-grams, preserving the distinct semantic information of each writing system
- Graceful Degradation: For words without Hanja mappings (pure Korean or loanwords), the Hanja n-gram set is simply empty, and the model naturally falls back to character + jamo representations
- Open Source: Code and pre-trained models are publicly available at github.com/kaniblu/hanja-sisg
Experimental Results
The method is evaluated on intrinsic tasks (word analogy and word similarity) and two downstream tasks (Korean news headline generation and sentiment analysis). The training corpus is based on the dataset from Park et al. (2018) with additional data cleansing (removing non-Korean sentences, unifying number tags).
Word Analogy Test
Using the Korean word analogy dataset (10,000 quadruples with semantic and syntactic categories from Park et al., 2018), the metric is cosine distance (lower is better) between predicted and target analogy vectors.
| Model | Semantic | Syntactic | All (Avg.) |
|---|---|---|---|
| SG | 0.42 | 0.49 | 0.45 |
| SISG(c) -- syllable n-grams | 0.45 | 0.59 | 0.52 |
| SISG(cj) -- + jamo n-grams | 0.39 | 0.48 | 0.44 |
| SISG(cjh3) -- + Hanja (1-3) | 0.34 | 0.45 | 0.39 |
| SISG(cjh4) -- + Hanja (1-4) | 0.34 | 0.45 | 0.40 |
| SISG(cjhr) -- random init | 0.35 | 0.46 | 0.40 |
Word Similarity Test (Korean WS353)
Evaluates correlation between word vector distances and human-annotated similarity scores. Higher Pearson/Spearman correlations are better.
| Model | Pearson | Spearman |
|---|---|---|
| SG | 0.60 | 0.62 |
| SISG(c) -- syllable n-grams | 0.62 | 0.61 |
| SISG(cj) -- + jamo n-grams | 0.66 | 0.67 |
| SISG(cjh3) -- + Hanja (1-3) | 0.63 | 0.63 |
| SISG(cjh4) -- + Hanja (1-4) | 0.62 | 0.61 |
| SISG(cjhr) -- random init | 0.65 | 0.64 |
Korean News Headline Generation
A novel downstream task using 840,205 Korean news articles (published Jan--Feb 2017, covering balanced categories such as politics, sports, world). An encoder-decoder model (bidirectional LSTM encoder + LSTM decoder, hidden size 512, with Bahdanau attention) generates a headline from the first three sentences of the article body. Word embeddings initialize the encoder. Split is 8:1:1 for train/validation/test.
| Embeddings | BLEU-1 | BLEU-2 | BLEU-3 | BLEU-4 | PPL |
|---|---|---|---|---|---|
| None (random) | 26.02 | 7.76 | 3.08 | 1.38 | 5.335 |
| SG | 30.33 | 10.20 | 4.29 | 1.98 | 4.122 |
| SISG(c) | 31.34 | 10.96 | 4.69 | 2.19 | 3.942 |
| SISG(cj) | 31.78 | 11.17 | 4.80 | 2.25 | 3.938 |
| SISG(cjh3) | 32.03 | 11.25 | 4.83 | 2.27 | 3.941 |
| SISG(cjh4) | 32.02 | 11.34 | 4.92 | 2.30 | 3.909 |
Sentiment Analysis (NSMC)
Evaluated on the Naver Sentiment Movie Corpus (200K movie reviews, positive/negative labels; split 100K/50K/50K). A basic LSTM encoder (hidden size 300) with feed-forward + softmax classifier is used to isolate the effect of input embeddings. Results are averaged over 3 runs with different random seeds.
| Embeddings | Accuracy | Precision | Recall | F1 |
|---|---|---|---|---|
| SISG(c) | 77.43 | 75.89 | 80.41 | 78.08 |
| SISG(cj) | 83.16 | 82.36 | 84.66 | 83.50 |
| SISG(cjh3) | 81.61 | 81.23 | 82.28 | 81.75 |
| SISG(cjh4) | 82.25 | 82.57 | 81.77 | 82.17 |
- Strong analogy improvements: SISG(cjh3) achieves the best overall analogy score (0.39 avg. cosine distance), significantly outperforming all baselines including jamo-level SISG (0.44), with the largest gains on semantic analogies
- Cross-lingual transfer helps analogies: Pre-trained Chinese initialization (SISG(cjh3): 0.39) outperforms random initialization (SISG(cjhr): 0.40), confirming that knowledge transfers across the Hanja-Chinese bridge
- Trade-offs in word similarity: Hanja-level models improve over pure character-level SISG(c) on similarity but do not surpass jamo-level SISG(cj), possibly due to the relatively small WS353 evaluation set being prone to statistical bias
- Consistent headline generation gains: SISG(cjh4) achieves the best BLEU-4 (2.30) and lowest perplexity (3.909), explained by formal Korean texts (news articles) containing more Sino-Korean words where Hanja awareness gives an edge
- Competitive on sentiment: While SISG(cj) leads on NSMC (spoken/informal text with fewer Sino-Korean words), Hanja-level models remain competitive and substantially outperform character-only SISG(c), demonstrating general applicability
Why It Matters
This paper makes a compelling case that language-specific etymological knowledge is a valuable and underexploited resource for building better word representations. The key contributions and implications are:
- First etymological cross-lingual transfer: This is the first work to introduce character-level cross-lingual transfer learning based on etymological grounds, using a separated vocabulary approach (as opposed to shared BPE vocabulary). By treating Hanja as a bridge between Korean and Chinese, the paper demonstrates a novel form of transfer that requires no parallel data -- only a dictionary-based character mapping.
- Beyond surface-level tokenization: While most subword approaches (BPE, character, jamo) focus on surface orthography, this work shows that incorporating deeper logographic structure can yield better representations, especially for tasks involving formal/written Korean. This insight generalizes to other languages with layered etymological histories (e.g., Japanese with Kanji, Vietnamese with Han-Nom).
- A new evaluation paradigm: The introduction of Korean news headline generation (840K articles) as a downstream evaluation task provides a practical, large-scale benchmark for Korean NLP, complementing the smaller intrinsic evaluation datasets available at the time.
- Practical simplicity: The approach is a modular extension of Skip-gram -- adding Hanja n-grams to the scoring function requires no change to the training pipeline. Code and models are publicly released for easy adoption.
- Honest limitations: The paper transparently discusses the dependence on the Hanja tagger (which may introduce errors, especially on spoken/informal text) and identifies developing an end-to-end system that does not rely on external taggers as important future work.