One-Line Summary
A knowledge-graph-based benchmark of 1,080 instances that systematically generates inter-context knowledge conflicts in RAG systems across eight conflict types (single/multi-hop x 1-4 conflicts), revealing that even the best LLMs achieve only 55% localization accuracy versus 83.3% for humans.

Background & Motivation
Retrieval-Augmented Generation (RAG) enhances LLM responses by retrieving external documents, but what happens when those retrieved documents contradict each other? This problem of inter-context conflict is critical for safe RAG deployment, yet existing benchmarks fail to capture its full complexity.
Four Key Limitations of Existing Benchmarks:
- Narrow task focus: Prior datasets (ECON: 168 instances, WikiContradict: 103 instances) are limited to QA settings where conflicts occur only among answer candidates.
- Oversimplified construction: Heavy reliance on entity substitution fails to capture nuanced, real-world knowledge conflicts.
- Limited conflict typology: No systematic distinction between single-hop and multi-hop conflicts; ~78% of existing instances are single-hop only.
- Underexplored inter-context conflicts: Most research focuses on conflicts between parametric and external knowledge, not among multiple retrieved documents.
In practice, real-world discrepancies often involve multi-hop reasoning and multiple simultaneous conflicts across documents -- scenarios that existing benchmarks rarely cover. MAGIC addresses all four limitations with a scalable, KG-based framework.
Proposed Method: KG-Based Conflict Generation Framework
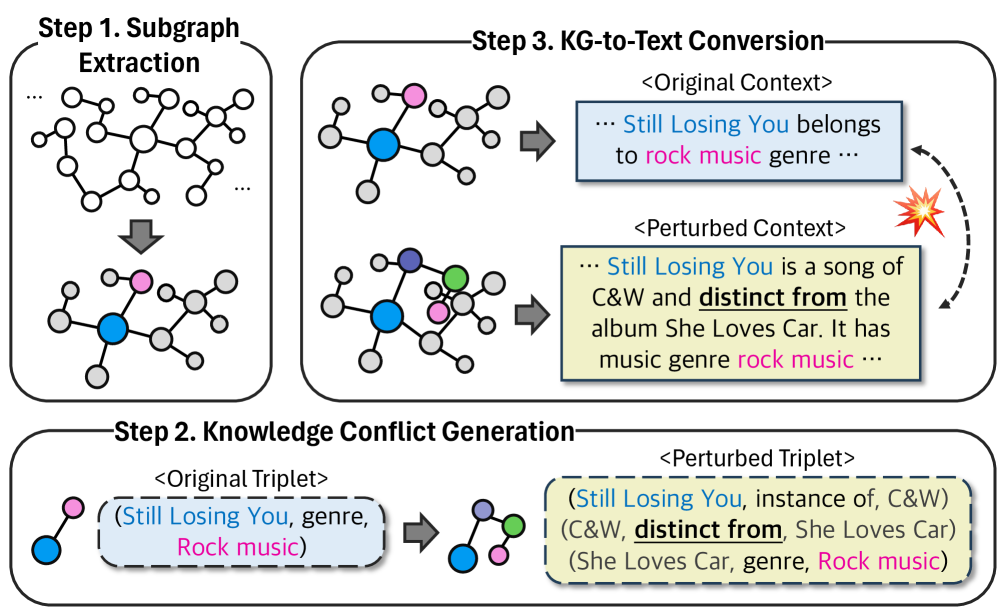
MAGIC uses a three-step pipeline built on Wikidata5M (~20 million triplets), producing 1,080 carefully curated instances across 46 relation types organized into 7 semantic domains (Human, Geography, Organization, Creative Work, Class/Concept, Cause-Effect, General).

Dataset Composition
| Type | 1 Conflict | 2 Conflicts | 3 Conflicts | 4 Conflicts | Total |
|---|---|---|---|---|---|
| Single-Hop | 208 | 154 | 80 | 50 | 492 |
| Multi-Hop | 300 | 158 | 80 | 50 | 588 |
| Total | 508 | 312 | 160 | 100 | 1,080 |
Experimental Results
Five LLMs are evaluated on MAGIC using two metrics: Identification (ID) -- binary detection of whether conflicts exist (scored across 3 inference runs; any failure = 0), and Localization (LOC) -- pinpointing all exact conflict sources (full score only if all locations correctly identified). A multi-step prompting strategy (asking for conflict count, reasoning, and conflicting sentences) outperforms simple binary prompting by up to 39.41%.
Cross-Benchmark Comparison (5-Model Average)
| Benchmark | ID Score (%) | LOC Score (%) |
|---|---|---|
| ECON (168 instances) | 74.73 | 57.09 |
| WikiContradict (103 instances) | 69.93 | 55.74 |
| MAGIC (1,080 instances) | 64.54 | 40.51 |
Per-Model Performance on MAGIC
| Model | ID Score (%) | LOC Score (%) |
|---|---|---|
| Mixtral 8x7B | 37.92 | 17.40 |
| Llama 3.1 70B | 72.86 | 37.92 |
| Claude 3.5 Haiku | 60.28 | 42.50 |
| OpenAI o1 | 68.06 | 49.72 |
| GPT-4o-mini | 83.61 | 55.00 |
| Human Baseline | 92.50 | 83.30 |
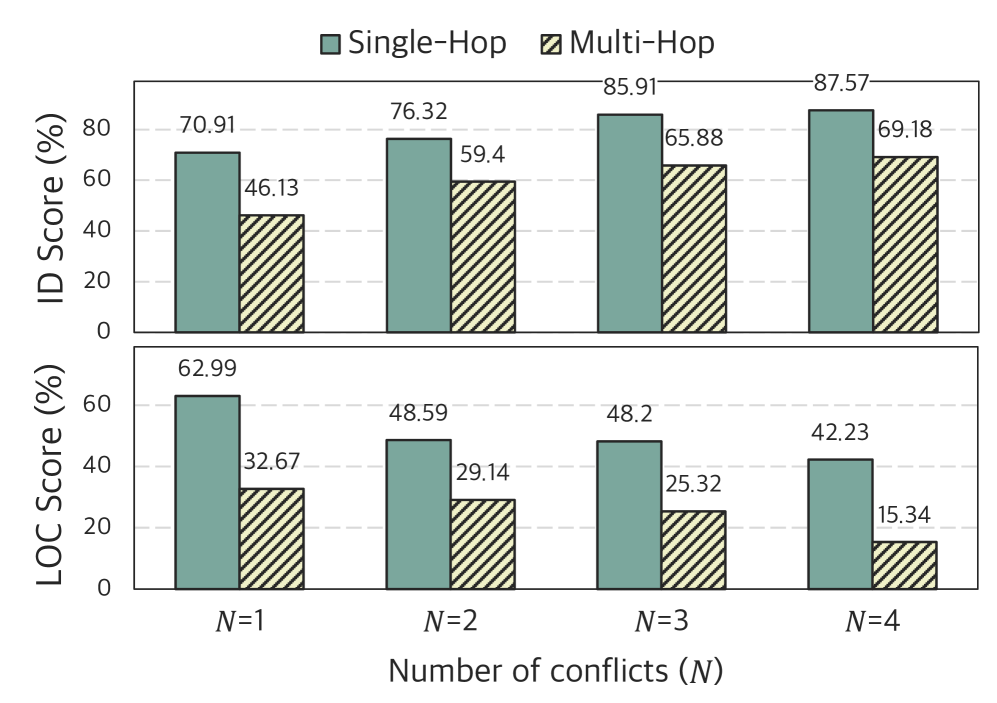

- MAGIC is harder: Compared to existing benchmarks, MAGIC lowers average ID by ~10% and LOC by ~17%, confirming substantially greater difficulty.
- Multi-hop is the bottleneck: Average ID drops from ~71% (single-hop) to ~55% (multi-hop); LOC drops from ~63% to ~29%. Multi-hop reasoning remains a critical weakness for current LLMs.
- Detection vs. Localization gap: Even when models detect that conflicts exist, pinpointing exact sources is far harder (40.51% LOC vs. 64.54% ID on average).
- More conflicts = easier detection, harder localization: Increasing the number of conflicts makes their presence more obvious but makes finding all conflict locations harder.
- Human-LLM gap: The best model (GPT-4o-mini) trails human performance by 8.89% on ID and 28.30% on LOC, revealing substantial room for improvement.
- Domain matters: Class/Concept relations are easiest (~68-73%); Organization relations show the most variance (14.52-75.86%). Relations like "captain" and "mother" are handled easily, while "work location" and "father" prove significantly harder.
- Context length effect: Both ID and LOC degrade as document length grows, with LOC dropping more sharply -- localization in long contexts is especially challenging.
- Prompting strategy matters: Multi-step prompting (conflict count + reasoning + extraction) improves performance by up to 39.41% over simple binary yes/no prompting.
Why It Matters
As RAG becomes the dominant paradigm for deploying LLMs in production, robust handling of conflicting information is essential for safe and reliable systems. MAGIC makes three contributions that advance this goal:
- First systematic KG-based conflict benchmark: By grounding conflicts in explicit knowledge graph structures, MAGIC enables interpretable analysis of why and where conflicts arise, unlike prior entity-substitution approaches.
- Comprehensive conflict typology: The eight-category taxonomy (single/multi-hop x 1-4 conflicts) covers a much broader range of real-world conflict scenarios than any existing dataset.
- Actionable insights for model improvement: The finding that multi-hop reasoning is a critical bottleneck (LOC drops from 63% to 29%) and the 28-point human-LLM gap in localization point to concrete directions for future research in conflict-aware RAG systems.