한줄 요약
지식 그래프 기반으로 1,080개 인스턴스를 체계적으로 구축한 RAG 문맥 간 충돌 벤치마크로, 8가지 충돌 유형(단일/멀티홉 x 1-4개 충돌)을 다루며, 최고 성능 LLM조차 위치 파악 정확도 55%에 그쳐 인간(83.3%) 대비 큰 격차를 보임을 밝혔습니다.

배경 및 동기
검색 증강 생성(RAG)은 외부 문서를 검색하여 LLM 응답을 강화하는 기법입니다. 그런데 검색된 문서들이 서로 모순되면 어떤 일이 벌어질까요? 이러한 문맥 간 충돌(inter-context conflict) 문제는 안전한 RAG 배포에 핵심적이지만, 기존 벤치마크는 그 복잡성을 충분히 반영하지 못합니다.
기존 벤치마크의 네 가지 한계:
- 좁은 태스크 범위: 기존 데이터셋(ECON: 168개, WikiContradict: 103개)은 정답 후보 간 충돌만 다루는 QA 설정에 국한되어 있습니다.
- 과도하게 단순한 구성: 개체 치환(entity substitution)에 의존하여 실제 환경의 미묘한 지식 충돌을 포착하지 못합니다.
- 제한적인 충돌 유형: 단일홉과 멀티홉 충돌을 체계적으로 구분하지 않으며, 기존 인스턴스의 ~78%가 단일홉에 불과합니다.
- 문맥 간 충돌 연구 부족: 대부분의 연구가 파라메트릭 지식과 외부 지식 간 충돌에 집중하고, 다수 검색 문서 간 충돌은 간과합니다.
실제 환경에서는 멀티홉 추론이 필요하고 여러 충돌이 동시에 존재하는 경우가 훨씬 흔합니다. MAGIC은 이 네 가지 한계를 모두 해결하는 확장 가능한 KG 기반 프레임워크를 제시합니다.
제안 방법: KG 기반 충돌 생성 프레임워크
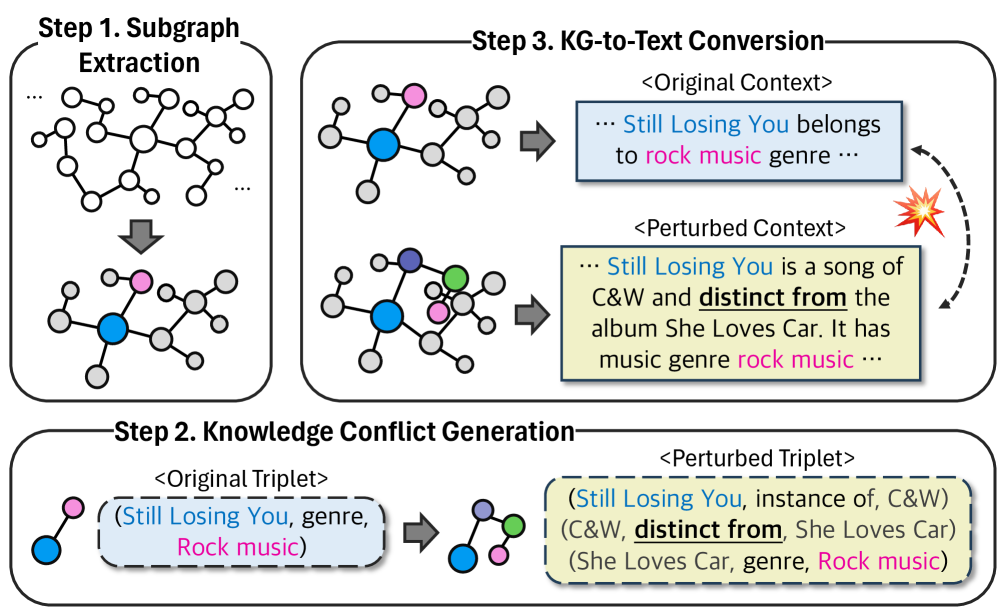
MAGIC은 Wikidata5M(약 2,000만 트리플릿) 기반의 3단계 파이프라인으로, 7개 의미 영역(인물, 지리, 조직, 창작물, 클래스/개념, 인과관계, 일반)에 걸친 46개 관계 유형에서 1,080개 인스턴스를 생성합니다.

데이터셋 구성
| 유형 | 1개 충돌 | 2개 충돌 | 3개 충돌 | 4개 충돌 | 합계 |
|---|---|---|---|---|---|
| 단일홉 | 208 | 154 | 80 | 50 | 492 |
| 멀티홉 | 300 | 158 | 80 | 50 | 588 |
| 합계 | 508 | 312 | 160 | 100 | 1,080 |
실험 결과
5개 LLM을 두 가지 지표로 평가합니다: 충돌 식별(ID) -- 충돌 존재 여부의 이진 판별(3회 추론 중 1회라도 실패 시 0점), 충돌 위치 파악(LOC) -- 모든 충돌 위치를 정확히 찾아야만 만점. 다단계 프롬프팅 전략(충돌 수 + 추론 과정 + 충돌 문장 추출)이 단순 이진 프롬프팅 대비 최대 39.41% 향상을 보였습니다.
벤치마크 간 비교 (5개 모델 평균)
| 벤치마크 | ID 점수 (%) | LOC 점수 (%) |
|---|---|---|
| ECON (168개 인스턴스) | 74.73 | 57.09 |
| WikiContradict (103개 인스턴스) | 69.93 | 55.74 |
| MAGIC (1,080개 인스턴스) | 64.54 | 40.51 |
MAGIC에서의 모델별 성능
| 모델 | ID 점수 (%) | LOC 점수 (%) |
|---|---|---|
| Mixtral 8x7B | 37.92 | 17.40 |
| Llama 3.1 70B | 72.86 | 37.92 |
| Claude 3.5 Haiku | 60.28 | 42.50 |
| OpenAI o1 | 68.06 | 49.72 |
| GPT-4o-mini | 83.61 | 55.00 |
| 인간 기준 | 92.50 | 83.30 |

- MAGIC이 더 어렵다: 기존 벤치마크 대비 평균 ID ~10%, LOC ~17% 하락하여 난이도가 크게 높음을 확인했습니다.
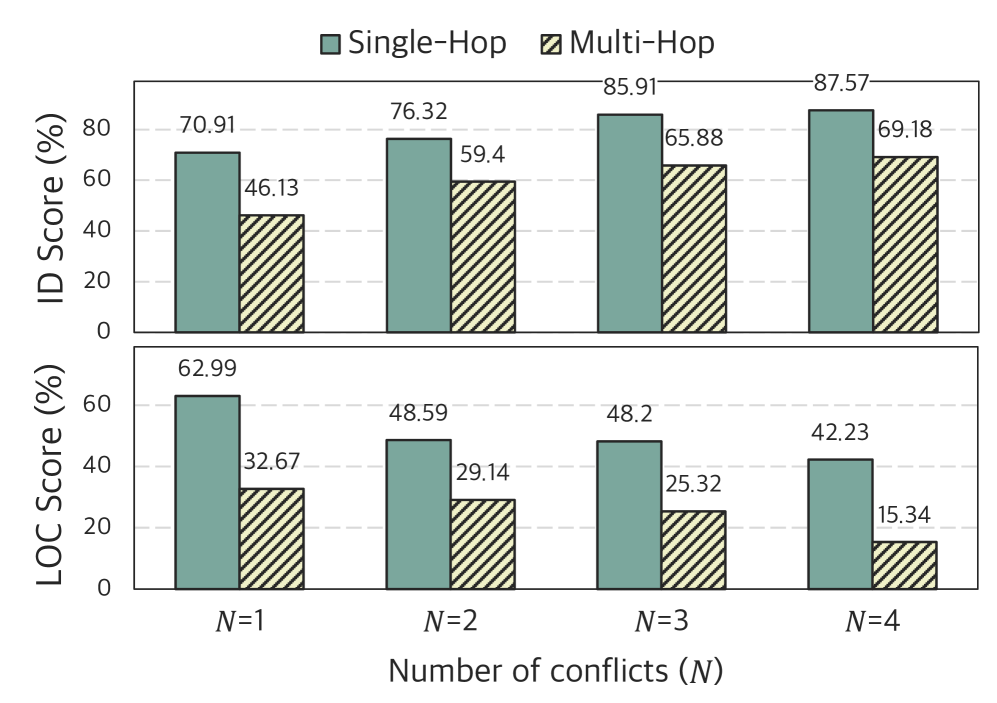
- 멀티홉이 핵심 병목: 평균 ID가 단일홉 ~71%에서 멀티홉 ~55%로, LOC는 ~63%에서 ~29%로 급감합니다. 멀티홉 추론은 현재 LLM의 주요 약점입니다.
- 탐지 vs. 위치 파악 격차: 충돌 존재를 탐지해도 정확한 출처를 찾는 것은 훨씬 어렵습니다 (평균 LOC 40.51% vs. ID 64.54%).
- 충돌 수 증가 = 탐지는 쉬워지고, 위치 파악은 어려워짐: 충돌이 많을수록 존재 자체는 명확해지나, 모든 위치를 찾아내기는 더 어렵습니다.
- 인간-LLM 격차: 최고 모델(GPT-4o-mini)도 인간 대비 ID 8.89%, LOC 28.30% 뒤처져 큰 개선 여지가 있습니다.
- 의미 영역의 영향: 클래스/개념 관계가 가장 쉽고(~68-73%), 조직 관계가 가장 큰 편차(14.52-75.86%)를 보입니다. "captain", "mother" 관계는 쉽고, "work location", "father" 관계는 매우 어렵습니다.
- 맥락 길이 효과: 문서 길이가 길어질수록 ID와 LOC 모두 저하되며, 특히 LOC의 하락이 급격합니다.
- 프롬프팅 전략의 중요성: 다단계 프롬프팅(충돌 수 + 추론 + 추출)이 단순 예/아니오 프롬프팅 대비 최대 39.41% 향상을 가져왔습니다.
왜 중요한가?
RAG가 LLM 프로덕션 배포의 주류 패러다임이 되면서, 상충하는 정보를 견고하게 처리하는 능력은 안전하고 신뢰할 수 있는 시스템 구축에 필수적입니다. MAGIC은 세 가지 측면에서 기여합니다:
- 최초의 체계적 KG 기반 충돌 벤치마크: 명시적 지식 그래프 구조에 충돌을 기반함으로써, 기존의 개체 치환 방식과 달리 충돌의 원인과 위치를 해석 가능하게 분석할 수 있습니다.
- 포괄적 충돌 분류 체계: 단일/멀티홉 x 1-4개 충돌의 8가지 범주로 기존 데이터셋보다 훨씬 넓은 범위의 실제 충돌 시나리오를 포괄합니다.
- 모델 개선을 위한 실질적 통찰: 멀티홉 추론이 핵심 병목(LOC 63%에서 29%로 하락)이라는 발견과 위치 파악에서의 28%p 인간-LLM 격차는 충돌 인식 RAG 시스템 연구의 구체적 방향을 제시합니다.