One-Line Summary
A 6,144-question benchmark that enforces balanced, three-hop reasoning across text, image, and speech modalities, revealing that even the best models exhibit asymmetric omni-modal grounding — particularly when transitioning information to the speech modality.
Background & Motivation
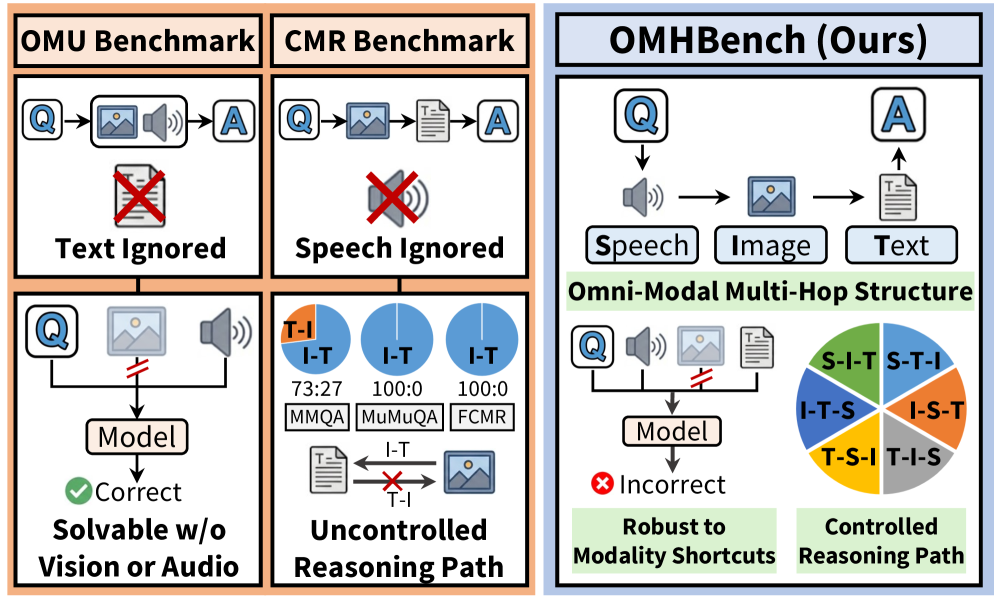
Multimodal large language models (MLLMs) now claim to process text, images, and audio simultaneously, yet two fundamental questions remain unanswered: (1) Can omni-modal understanding (OMU) benchmarks truly evaluate all three modalities if most questions are solvable without using each modality? (2) Can cross-modal reasoning (CMR) benchmarks reliably measure reasoning when they are dominated by a single reasoning path?
The authors systematically analyzed existing evaluation frameworks and uncovered two critical shortcomings:
Problem 1 — Modality Shortcuts in OMU Benchmarks: Approximately 70-80% of instances in existing OMU benchmarks can be solved without accessing specific modalities (e.g., without visual or audio input), allowing models to take shortcuts that bypass true omni-modal understanding.
Problem 2 — Path Imbalance in CMR Benchmarks: Existing cross-modal reasoning datasets exhibit severely imbalanced reasoning paths (e.g., MuMuQA contains only Image-to-Text instances, MMQA skews ~2:1 toward Image-to-Text). When researchers forcibly balanced the paths, model accuracy dropped by up to 18%, revealing that previously reported results were overestimated due to path bias.
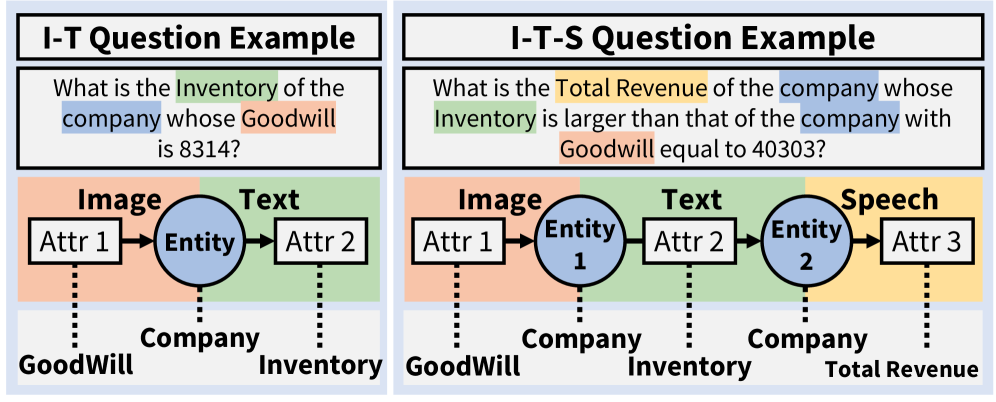
These findings motivated the creation of OMHBench, which bridges OMU and CMR paradigms while enforcing three requirements: (1) no shortcut-prone evaluation via enforced multi-hop reasoning, (2) incorporation of all three modalities (text, image, speech), and (3) explicit control of reasoning paths for unbiased assessment.
Benchmark Construction Pipeline
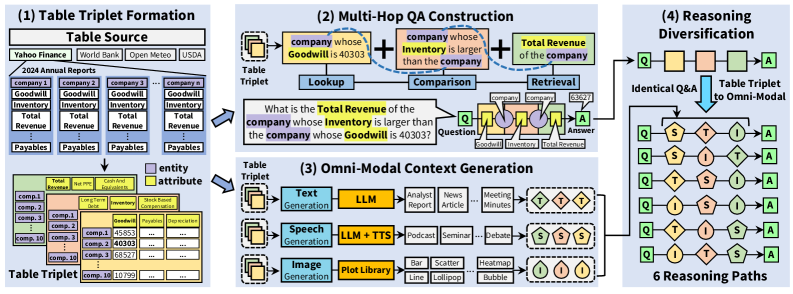
Quality Assurance: Entity names are anonymized with alphabetical codes to prevent parametric knowledge exploitation. QA-based validation and LLM-based table reconstruction achieve 100% consistency. Question rephrasing uses multiple LLMs, achieving higher lexical deviation than the PAWS dataset (0.32 vs. 0.13). TTS quality is verified with WER: 0.03, CER: 0.02, STOI: 99.2, and SI-SDR: 21.0.
Experimental Results
13 state-of-the-art models were evaluated: 6 proprietary (Gemini family) and 7 open-source (Qwen3-Omni, Phi-4 Multimodal, Qwen2.5-Omni, OmniVinci, MiniCPM-o, Omni-AutoThink). The paper introduces the Path Balance Score (PBS), which counts an instance as correct only when the model answers correctly across all 6 path variations.
OMHBench-Connect (Entity Selection)
| Model | Type | Avg Accuracy | PBS | Path Range |
|---|---|---|---|---|
| Gemini 3 Flash | Proprietary | 78.3% | 32.2 | 60.2% - 98.4% |
| Gemini 2.5 Pro | Proprietary | 72.5% | 25.0 | 50.8% - 96.9% |
| Gemini 2.5 Flash | Proprietary | 53.6% | 4.7 | 21.9% - 85.9% |
| Qwen3-Omni 30B | Open-source | 46.8% | 2.3 | 16.0% - 77.0% |
| Most other open-source | Open-source | < 5% | ~0 | - |
OMHBench-Reasoning (Aggregation)
| Model | Type | Avg Accuracy | PBS | Path Range |
|---|---|---|---|---|
| Gemini 3 Flash | Proprietary | 49.4% | 8.6 | 40.0% - 58.8% |
| Gemini 2.5 Pro | Proprietary | 48.8% | 10.9 | 41.4% - 53.9% |
| Qwen3-Omni 30B | Open-source | 15.0% | 0.0 | 2.7% - 28.5% |
| Most other open-source | Open-source | ~0% | 0 | - |
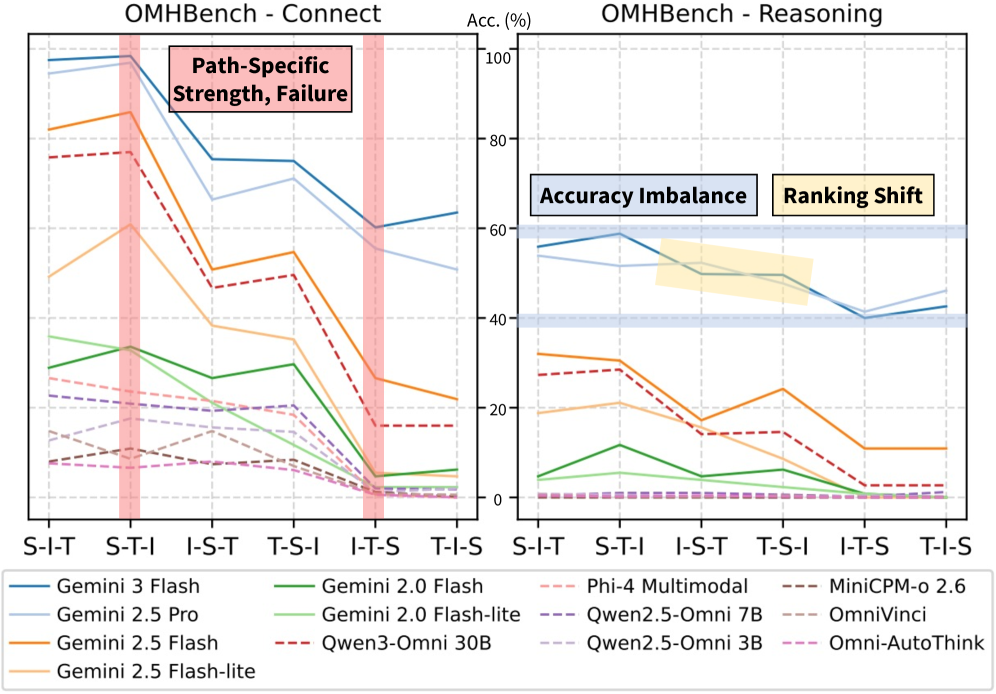
- Proprietary vs. Open-source Gap: Gemini 3 Flash (78.3%) vastly outperforms the best open-source model Qwen3-Omni 30B (46.8%) on Connect; the gap widens on Reasoning (49.4% vs. 15.0%)
- Asymmetric Speech Grounding: Transitions to speech (I→S, T→S) are particularly challenging, while transitions from speech are relatively robust. For example, Qwen3-Omni scores 77.0% on S-T-I but only 16.0% on I-T-S
- Path Sensitivity: Large accuracy swings across paths — up to 38% for Qwen3-Omni on Connect and 25.8% for Gemini 3 Flash on Reasoning — demonstrate that single-path evaluation unreliably characterizes model capabilities
- Operation Difficulty: Performance degrades progressively: Ranking (easiest) > Comparison > Proximity > Range (hardest), indicating MLLMs handle ordinal comparisons well but struggle with interval constraints
- Cross-Domain Gap: Gemini 3 Flash shows up to 21.8% difference between Economics and Nutrition domains, indicating imperfect domain generalization
- Prompting Ineffective: Advanced strategies (Self-Ask, Least-to-Most, Plan-and-Solve) yield no consistent improvements over standard chain-of-thought, suggesting asymmetric grounding reflects fundamental model limitations
Why It Matters
OMHBench is the first benchmark to simultaneously enforce balanced reasoning across text, image, and speech while eliminating modality shortcuts. Its key contributions are threefold:
- Reliable Evaluation: By controlling all 6 reasoning paths with identical Q&A pairs, OMHBench prevents the path bias that inflated results on prior benchmarks by up to 18%
- Diagnosing Asymmetric Grounding: The benchmark reveals a systematic weakness — models struggle specifically when grounding information into the speech modality, sometimes behaving as if speech input is absent entirely. This "asymmetric omni-modal grounding" is a fundamental limitation, not a prompting issue
- Actionable Roadmap: The stepwise failure analysis and operation-level breakdowns pinpoint exactly where models fail (e.g., early-stage failures in weak models, cross-modal attribute grounding in stronger ones), providing concrete development directions for next-generation multimodal AI