한줄 요약
텍스트, 이미지, 음성 세 모달리티에 걸친 3-hop 추론을 6,144개의 질문으로 균형 있게 평가하는 벤치마크로, 최첨단 모델조차 음성 모달리티로의 정보 전이에서 비대칭적 옴니모달 그라운딩 문제를 보임을 밝혔습니다.
배경 및 동기
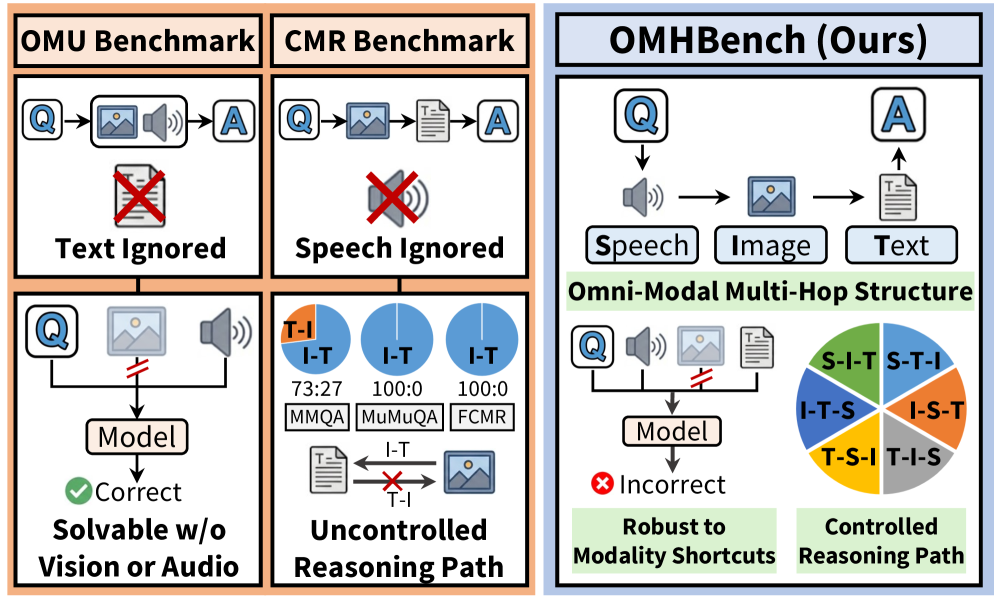
멀티모달 대형 언어 모델(MLLM)이 텍스트, 이미지, 오디오를 동시에 처리할 수 있다고 주장하지만, 두 가지 근본적인 질문이 남아 있습니다: (1) 옴니모달 이해(OMU) 벤치마크가 각 모달리티 없이도 풀 수 있다면, 진정으로 세 모달리티를 모두 평가하는 것인가? (2) 교차 모달 추론(CMR) 벤치마크가 단일 추론 경로에 편향되어 있다면, 추론 능력을 신뢰성 있게 측정할 수 있는가?
기존 평가 프레임워크를 체계적으로 분석한 결과, 두 가지 심각한 결함이 발견되었습니다:
문제 1 — OMU 벤치마크의 모달리티 지름길: 기존 OMU 벤치마크의 약 70-80%의 문항이 특정 모달리티(시각 또는 오디오) 없이도 풀 수 있어, 모델이 진정한 옴니모달 이해를 우회하는 지름길을 사용할 수 있었습니다.
문제 2 — CMR 벤치마크의 경로 불균형: 기존 교차 모달 추론 데이터셋은 추론 경로가 심하게 편향되어 있습니다 (예: MuMuQA는 Image-to-Text 인스턴스만 포함, MMQA는 ~2:1로 Image-to-Text에 편중). 경로를 강제로 균형화하면 일부 모델의 정확도가 최대 18%까지 하락하여, 기존 결과가 경로 편향으로 인해 과대평가되었음을 보여줍니다.
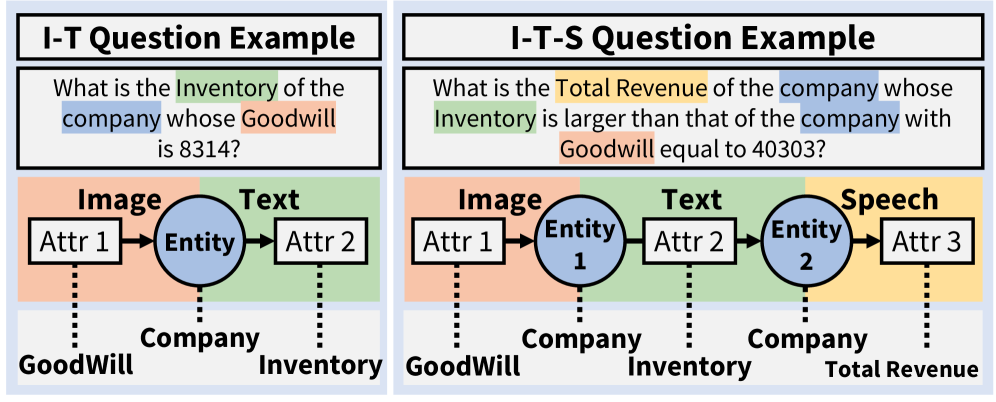
이러한 발견을 바탕으로 OMHBench는 OMU와 CMR 패러다임을 통합하면서 세 가지 요건을 충족합니다: (1) 멀티홉 추론을 강제하여 지름길 방지, (2) 텍스트, 이미지, 음성 세 모달리티 모두 포함, (3) 추론 경로를 명시적으로 제어하여 편향 없는 평가 보장.
벤치마크 구축 파이프라인
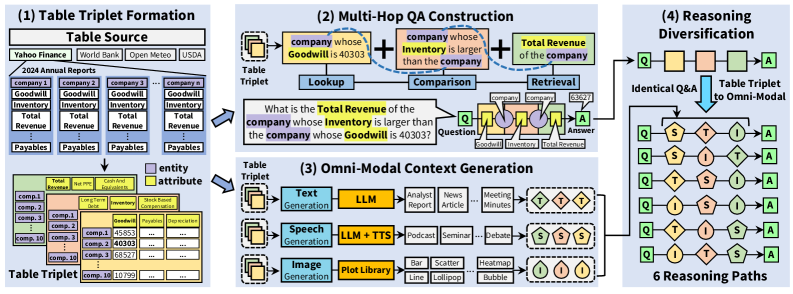
품질 보증: 엔티티명을 알파벳 코드로 익명화하여 파라메트릭 지식 활용을 방지합니다. QA 기반 검증과 LLM 기반 테이블 재구성으로 100% 일관성을 달성했습니다. 다수 LLM을 활용한 질문 재구성은 PAWS 데이터셋보다 높은 어휘 편차를 달성합니다(0.32 vs. 0.13). TTS 품질은 WER: 0.03, CER: 0.02, STOI: 99.2, SI-SDR: 21.0으로 검증되었습니다.
실험 결과
13개 최첨단 모델을 평가했습니다: 상용 6개(Gemini 계열), 오픈소스 7개(Qwen3-Omni, Phi-4 Multimodal, Qwen2.5-Omni, OmniVinci, MiniCPM-o, Omni-AutoThink). 본 논문은 모델이 6가지 경로 변형 모두에서 정답을 맞출 때만 정답으로 인정하는 경로 균형 점수(PBS)를 새로 제안합니다.
OMHBench-Connect (엔티티 선택)
| 모델 | 유형 | 평균 정확도 | PBS | 경로별 범위 |
|---|---|---|---|---|
| Gemini 3 Flash | 상용 | 78.3% | 32.2 | 60.2% - 98.4% |
| Gemini 2.5 Pro | 상용 | 72.5% | 25.0 | 50.8% - 96.9% |
| Gemini 2.5 Flash | 상용 | 53.6% | 4.7 | 21.9% - 85.9% |
| Qwen3-Omni 30B | 오픈소스 | 46.8% | 2.3 | 16.0% - 77.0% |
| 기타 오픈소스 모델 | 오픈소스 | < 5% | ~0 | - |
OMHBench-Reasoning (집계 연산)
| 모델 | 유형 | 평균 정확도 | PBS | 경로별 범위 |
|---|---|---|---|---|
| Gemini 3 Flash | 상용 | 49.4% | 8.6 | 40.0% - 58.8% |
| Gemini 2.5 Pro | 상용 | 48.8% | 10.9 | 41.4% - 53.9% |
| Qwen3-Omni 30B | 오픈소스 | 15.0% | 0.0 | 2.7% - 28.5% |
| 기타 오픈소스 모델 | 오픈소스 | ~0% | 0 | - |
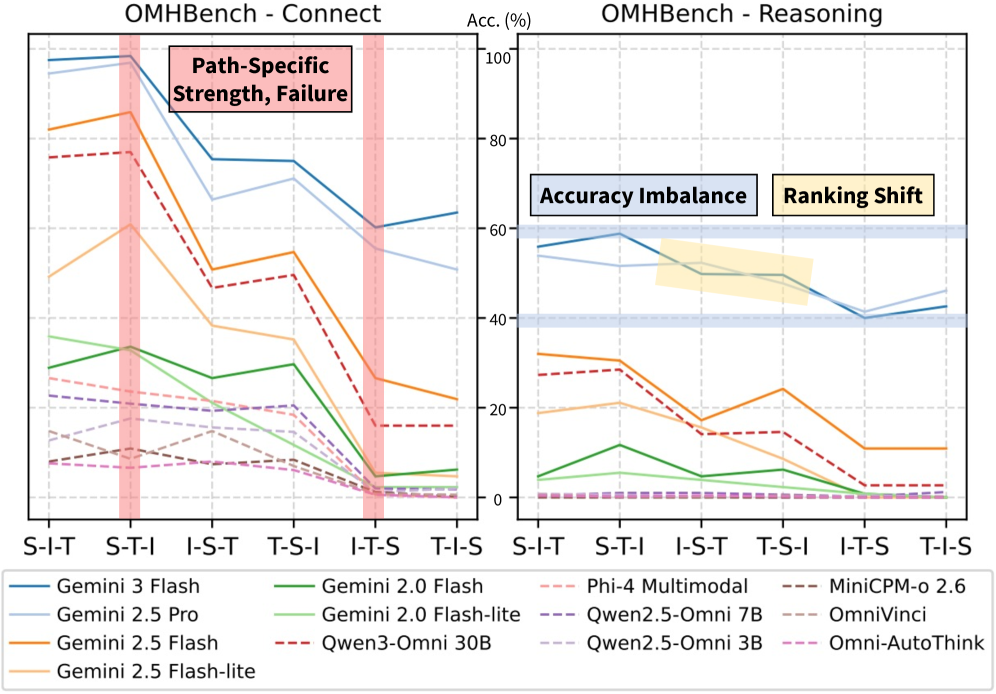
- 상용 vs. 오픈소스 격차: Gemini 3 Flash(78.3%)가 최고 오픈소스 모델인 Qwen3-Omni 30B(46.8%)를 Connect에서 크게 앞서며, Reasoning에서는 격차가 더 벌어집니다(49.4% vs. 15.0%)
- 비대칭적 음성 그라운딩: 음성 으로의 전이(I→S, T→S)가 특히 어려운 반면, 음성 으로부터의 전이는 비교적 안정적입니다. 예를 들어 Qwen3-Omni는 S-T-I에서 77.0%이지만 I-T-S에서는 16.0%에 불과합니다
- 경로 민감도: 경로 간 정확도 차이가 매우 큽니다 — Qwen3-Omni의 Connect에서 최대 38%, Gemini 3 Flash의 Reasoning에서 25.8% — 이는 단일 경로 평가가 모델 능력을 신뢰성 있게 반영하지 못함을 보여줍니다
- 연산 난이도: 성능이 점진적으로 하락합니다: Ranking(가장 쉬움) > Comparison > Proximity > Range(가장 어려움). 순위 비교는 잘 수행하지만 구간 제약에는 취약합니다
- 교차 도메인 격차: Gemini 3 Flash에서 경제학과 영양학 도메인 간 최대 21.8%의 성능 차이가 나타나, 도메인 일반화가 불완전함을 시사합니다
- 프롬프팅 전략의 한계: Self-Ask, Least-to-Most, Plan-and-Solve 등 고급 프롬프팅 전략이 표준 chain-of-thought 대비 일관된 개선을 보이지 않아, 비대칭 그라운딩이 프롬프팅이 아닌 근본적인 모델 한계임을 시사합니다
왜 중요한가?
OMHBench는 텍스트, 이미지, 음성 간 균형 잡힌 추론을 강제하면서 모달리티 지름길을 제거한 최초의 벤치마크입니다. 핵심 기여는 세 가지입니다:
- 신뢰할 수 있는 평가: 동일한 Q&A 쌍으로 6가지 추론 경로를 모두 제어함으로써, 기존 벤치마크에서 최대 18%까지 결과를 부풀렸던 경로 편향을 방지합니다
- 비대칭 그라운딩 진단: 모델이 음성 모달리티 로의 정보 그라운딩에서 체계적으로 취약하며, 때로는 음성 입력이 아예 없는 것처럼 동작하는 현상을 발견했습니다. 이러한 "비대칭 옴니모달 그라운딩"은 프롬프팅 문제가 아닌 근본적인 한계입니다
- 실행 가능한 개발 방향: 단계별 실패 분석과 연산 수준 성능 분석을 통해 모델이 정확히 어디에서 실패하는지(약한 모델은 초기 추론 단계, 강한 모델은 교차 모달 속성 그라운딩) 파악하여, 차세대 멀티모달 AI 개발의 구체적인 방향을 제시합니다