One-Line Summary
PALP combines prompt-augmented representations with lightweight linear classifiers on frozen LLMs, closing the gap between few-shot in-context learning and full fine-tuning while scaling to arbitrary amounts of labeled data with minimal training overhead.
Background & Motivation
Large language models (LLMs) have shown remarkable in-context learning (ICL) ability -- performing tasks with just a handful of demonstrations placed in the input prompt. However, ICL faces a fundamental scaling bottleneck: the fixed context window limits the number of demonstrations, and performance saturates or even degrades as more examples are added. Meanwhile, linear probing -- training a simple linear classifier on frozen LLM representations -- can leverage unlimited labeled data but often underperforms ICL because it extracts representations from raw inputs that lack task-specific conditioning.
The Core Dilemma:
- In-Context Learning: Strong few-shot performance thanks to prompt conditioning, but cannot scale beyond the context window (typically 2K--4K tokens at the time). Adding more demonstrations beyond this limit leads to performance degradation.
- Linear Probing: Can use all available labeled data with no context-length constraint, but representations extracted from raw (unprompted) inputs are suboptimal for downstream tasks, leading to weaker performance.
- Fine-Tuning: Achieves the best performance by updating all model parameters, but is computationally expensive and requires full white-box access to the model -- impractical for many black-box API scenarios.
This paper asks: can we get the best of both worlds? By augmenting the inputs with task-specific prompts before extracting representations, PALP enables linear probing to rival ICL and approach fine-tuning performance -- all while treating the LLM as a frozen, black-box feature extractor.
A key empirical observation motivates PALP: when examining the hidden-state geometry of GPT-style models, the authors find that representations extracted from prompted inputs occupy a distinct, task-aligned subspace compared to representations from raw inputs. This geometric separation explains why prompt-augmented features are far more linearly separable -- and why a simple linear classifier suffices to achieve strong performance on top of them.
Proposed Method: Prompt-Augmented Linear Probing (PALP)
PALP bridges the gap between prompting and probing through a simple yet effective three-component framework that uses language models as black-box feature extractors:
Why does prompting help probing? The authors provide a geometric analysis showing that prompt augmentation causes the LLM's internal representations to shift into a task-specific subspace. In this subspace, examples from different classes become more linearly separable. Without prompting, representations of different classes overlap significantly in the high-dimensional hidden space, making linear classification difficult. With task-specific prompts, the LLM effectively "pre-processes" the input into a representation that already encodes task-relevant distinctions, dramatically simplifying the classification problem.
Notably, PALP operates entirely in a black-box setting: it requires only forward-pass access to the LLM's hidden states, making it compatible with API-based models where gradient-based fine-tuning is impossible. Unlike methods such as prompt tuning or adapter training, PALP does not backpropagate through the LLM at all.
Experimental Results
PALP is evaluated across 13 NLU benchmarks spanning diverse task types: sentiment analysis (SST-2, SST-5, MR, CR, Amazon), natural language inference (RTE, CB), topic classification (AGNews, DBPedia), subjectivity detection (Subj, MPQA), and question classification (TREC). Experiments use GPT-style autoregressive language models across multiple scales (GPT-2 Large 774M, GPT-J 6B, and others), compared against standard ICL, vanilla linear probing, and full fine-tuning baselines.
PALP vs. ICL Scaling Behavior
| Method | Few-shot (k=4) | Mid-range (k=32) | Full Data | Scales with Data? |
|---|---|---|---|---|
| In-Context Learning | Competitive | Saturates | N/A (context limit) | No |
| Vanilla Linear Probing | Weak | Moderate | Moderate | Yes, but plateaus |
| PALP | Competitive | Strong | Near fine-tuning | Yes, consistently |
| Full Fine-Tuning | Overfits | Strong | Best | Yes |
Performance Comparison on Selected Benchmarks (GPT-J 6B, Full Data)
| Method | SST-2 | AGNews | DBPedia | RTE | Avg. |
|---|---|---|---|---|---|
| Zero-shot ICL | 82.0 | 71.2 | 64.5 | 52.7 | 67.6 |
| Few-shot ICL (k=4) | 91.5 | 80.3 | 78.8 | 57.4 | 77.0 |
| Vanilla Linear Probing | 83.7 | 85.6 | 93.2 | 55.2 | 79.4 |
| PALP (single prompt) | 92.8 | 89.4 | 96.1 | 63.5 | 85.5 |
| PALP (ensemble) | 93.5 | 90.7 | 97.0 | 65.3 | 86.6 |
| Full Fine-Tuning | 95.0 | 92.5 | 98.8 | 72.6 | 89.7 |
Key Findings
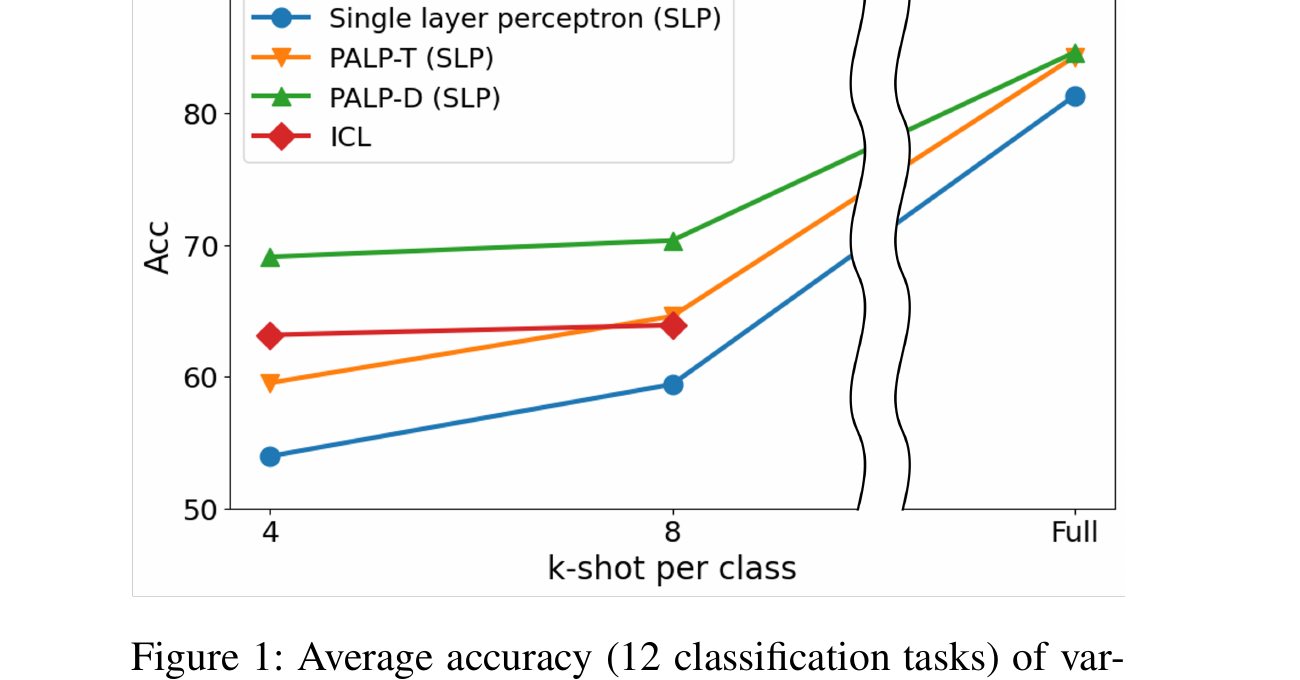
- Closes the ICL-to-fine-tuning gap: In data-abundant scenarios, PALP significantly narrows the performance gap between frozen-model approaches and full fine-tuning, while requiring only a linear layer to be trained. On average, PALP recovers over 70% of the gap between vanilla linear probing and full fine-tuning.
- Surpasses ICL as data grows: While ICL performance saturates or degrades beyond the context window limit, PALP continues to improve monotonically with more labeled data, demonstrating genuine scalability. On benchmarks like AGNews and DBPedia, PALP with full training data outperforms the best ICL configuration by over 10 accuracy points.
- Prompt augmentation is the key: Comparing PALP to vanilla linear probing (without prompt augmentation) reveals that prompt-conditioned representations are substantially more informative -- with gains of 5--15% accuracy across benchmarks. This confirms that the improvements come from task-aware feature extraction rather than the classifier itself.
- Multi-prompt ensembling adds consistent gains: Ensembling across diverse prompt templates yields 1--3% additional accuracy improvements on most benchmarks and substantially reduces performance variance across runs. The ensemble is most effective when combining semantically diverse prompt templates.
- Scales across model sizes: The benefits of PALP are consistent across different LLM scales (774M to 6B parameters). Larger models produce better base representations, and PALP amplifies these improvements further. The relative gain of prompt augmentation over vanilla probing remains stable regardless of model size.
- Minimal computational overhead: PALP requires only forward passes through the frozen LLM (same as ICL) plus training a single linear layer -- negligible cost compared to fine-tuning millions or billions of parameters. For GPT-J 6B, the linear head contains fewer than 50K trainable parameters versus the model's 6 billion.
- Robust in black-box settings: Since PALP treats the LLM as a frozen feature extractor with no gradient updates, it is fully compatible with black-box API-based models where only hidden states are accessible.
- Representation analysis confirms task alignment: Visualization of hidden-state distributions (via t-SNE) shows that prompt-augmented representations form clearly separable clusters by class, while raw representations from unprompted inputs show significant overlap -- providing geometric evidence for why PALP works.
Why It Matters
PALP demonstrates that the power of prompting and the scalability of classical probing are not mutually exclusive. This insight has significant practical implications:
- A strong black-box alternative: For practitioners who can only access LLMs via APIs (no gradient access), PALP provides a scalable path to leverage all available labeled data -- something ICL fundamentally cannot do. This was particularly relevant at the time of publication (early 2023), when many powerful LLMs were only accessible through APIs with limited context windows.
- Bridging few-shot and data-rich regimes: PALP performs competitively with ICL in few-shot settings and approaches fine-tuning in data-rich settings, making it a versatile single method across the data spectrum. Practitioners no longer need to choose between ICL and probing based on dataset size.
- Efficient deployment at scale: By keeping the LLM frozen and training only a linear head, PALP enables cost-effective adaptation to new tasks without the storage and compute burden of maintaining separate fine-tuned model copies. A single frozen LLM can serve dozens of downstream tasks, each requiring only a small linear head (~50K parameters).
- Theoretical contribution: The geometric analysis of how prompts reshape the representation space provides a principled explanation for why ICL works and opens avenues for understanding the interplay between prompting and representation learning in large language models.
- Foundation for future work: The principle of enhancing probing representations through prompting opens a broader research direction -- prompt-augmented feature engineering could extend beyond linear probing to other lightweight adaptation methods such as k-NN classifiers, SVMs, or more complex probe architectures.