한줄 요약
PALP는 동결된 LLM의 프롬프트 증강 표현 위에 경량 선형 분류기를 학습하여, 퓨샷 인컨텍스트 학습과 풀 파인튜닝 사이의 성능 격차를 최소한의 학습 비용으로 해소하면서 임의 규모의 레이블 데이터로 확장 가능한 방법을 제시합니다.
배경 및 동기
대규모 언어 모델(LLM)은 소수의 시연 예제만으로 태스크를 수행하는 인컨텍스트 학습(ICL) 능력을 보여주었습니다. 그러나 ICL에는 근본적인 확장성 병목이 존재합니다: 고정된 컨텍스트 윈도우가 시연 수를 제한하며, 더 많은 예제를 추가하면 성능이 정체되거나 오히려 하락합니다. 반면 선형 프로빙은 동결된 LLM 표현 위에 단순 선형 분류기를 학습하여 무제한의 레이블 데이터를 활용할 수 있지만, 태스크 특화 조건화 없이 원본 입력에서 추출한 표현은 ICL보다 낮은 성능을 보입니다.
핵심 딜레마:
- 인컨텍스트 학습(ICL): 프롬프트 조건화 덕분에 강력한 퓨샷 성능을 보이지만, 컨텍스트 윈도우(당시 기준 2K--4K 토큰)를 넘어서면 확장이 불가능합니다. 한계를 초과하는 시연 추가는 성능 저하를 유발합니다.
- 선형 프로빙: 컨텍스트 길이 제약 없이 모든 레이블 데이터를 활용할 수 있지만, 프롬프트 없이 원본 입력에서 추출한 표현이 다운스트림 태스크에 최적화되지 않아 성능이 열위합니다.
- 파인튜닝: 전체 모델 파라미터를 업데이트하여 최고 성능을 달성하지만, 연산 비용이 크고 화이트박스 접근이 필요하여 블랙박스 API 환경에서는 사용이 불가능합니다.
본 논문은 두 가지 장점을 동시에 취할 수 있는가?라는 질문을 던집니다. 표현 추출 전에 태스크 특화 프롬프트로 입력을 증강함으로써, PALP는 선형 프로빙이 ICL에 필적하고 파인튜닝 성능에 근접할 수 있게 합니다 -- 이 모든 것을 LLM을 동결된 블랙박스 피처 추출기로 사용하면서 달성합니다.
PALP의 핵심적인 경험적 관찰은 다음과 같습니다: GPT 계열 모델의 은닉 상태 기하학을 분석한 결과, 프롬프트가 포함된 입력에서 추출한 표현이 원본 입력의 표현과는 구별되는 태스크 정렬 부분공간을 점유한다는 것입니다. 이 기하학적 분리가 프롬프트 증강 피처의 선형 분리가능성이 높은 이유를 설명하며, 단순한 선형 분류기만으로도 높은 성능을 달성할 수 있는 근거를 제공합니다.
제안 방법: Prompt-Augmented Linear Probing (PALP)
PALP는 언어 모델을 블랙박스 피처 추출기로 활용하는 간결하면서도 효과적인 3단계 프레임워크를 통해 프롬프팅과 프로빙 사이의 격차를 해소합니다:
왜 프롬프팅이 프로빙에 도움이 되는가? 저자들은 프롬프트 증강이 LLM의 내부 표현을 태스크 특화 부분공간으로 이동시킨다는 기하학적 분석을 제시합니다. 이 부분공간에서는 서로 다른 클래스의 예제들이 더 선형적으로 분리 가능해집니다. 프롬프트 없이 추출한 표현에서는 서로 다른 클래스의 표현이 고차원 은닉 공간에서 상당히 겹치지만, 태스크 특화 프롬프트를 사용하면 LLM이 입력을 태스크 관련 구별을 이미 인코딩한 표현으로 효과적으로 "전처리"하여, 분류 문제를 극적으로 단순화합니다.
특히 PALP는 완전한 블랙박스 환경에서 동작합니다: LLM의 은닉 상태에 대한 순전파 접근만 필요하므로, 그래디언트 기반 파인튜닝이 불가능한 API 기반 모델과도 호환됩니다. 프롬프트 튜닝이나 어댑터 학습과 달리, PALP는 LLM을 통한 역전파를 전혀 수행하지 않습니다.
실험 결과
PALP는 다양한 태스크 유형을 포괄하는 13개 NLU 벤치마크에서 평가되었습니다: 감성 분석(SST-2, SST-5, MR, CR, Amazon), 자연어 추론(RTE, CB), 주제 분류(AGNews, DBPedia), 주관성 탐지(Subj, MPQA), 질문 분류(TREC) 등. GPT 계열 자기회귀 언어 모델을 다양한 규모(GPT-2 Large 774M, GPT-J 6B 등)로 사용하여, 표준 ICL, 바닐라 선형 프로빙, 풀 파인튜닝 베이스라인과 비교하였습니다.
PALP vs. ICL 확장 특성
| 방법 | 퓨샷 (k=4) | 중간 규모 (k=32) | 전체 데이터 | 데이터 확장성 |
|---|---|---|---|---|
| 인컨텍스트 학습 | 경쟁력 있음 | 정체 | N/A (컨텍스트 제한) | 없음 |
| 바닐라 선형 프로빙 | 약함 | 보통 | 보통 | 있으나 정체 |
| PALP | 경쟁력 있음 | 우수 | 파인튜닝에 근접 | 지속적 향상 |
| 풀 파인튜닝 | 과적합 | 우수 | 최고 | 있음 |
주요 벤치마크 성능 비교 (GPT-J 6B, 전체 데이터)
| 방법 | SST-2 | AGNews | DBPedia | RTE | 평균 |
|---|---|---|---|---|---|
| 제로샷 ICL | 82.0 | 71.2 | 64.5 | 52.7 | 67.6 |
| 퓨샷 ICL (k=4) | 91.5 | 80.3 | 78.8 | 57.4 | 77.0 |
| 바닐라 선형 프로빙 | 83.7 | 85.6 | 93.2 | 55.2 | 79.4 |
| PALP (단일 프롬프트) | 92.8 | 89.4 | 96.1 | 63.5 | 85.5 |
| PALP (앙상블) | 93.5 | 90.7 | 97.0 | 65.3 | 86.6 |
| 풀 파인튜닝 | 95.0 | 92.5 | 98.8 | 72.6 | 89.7 |
주요 발견
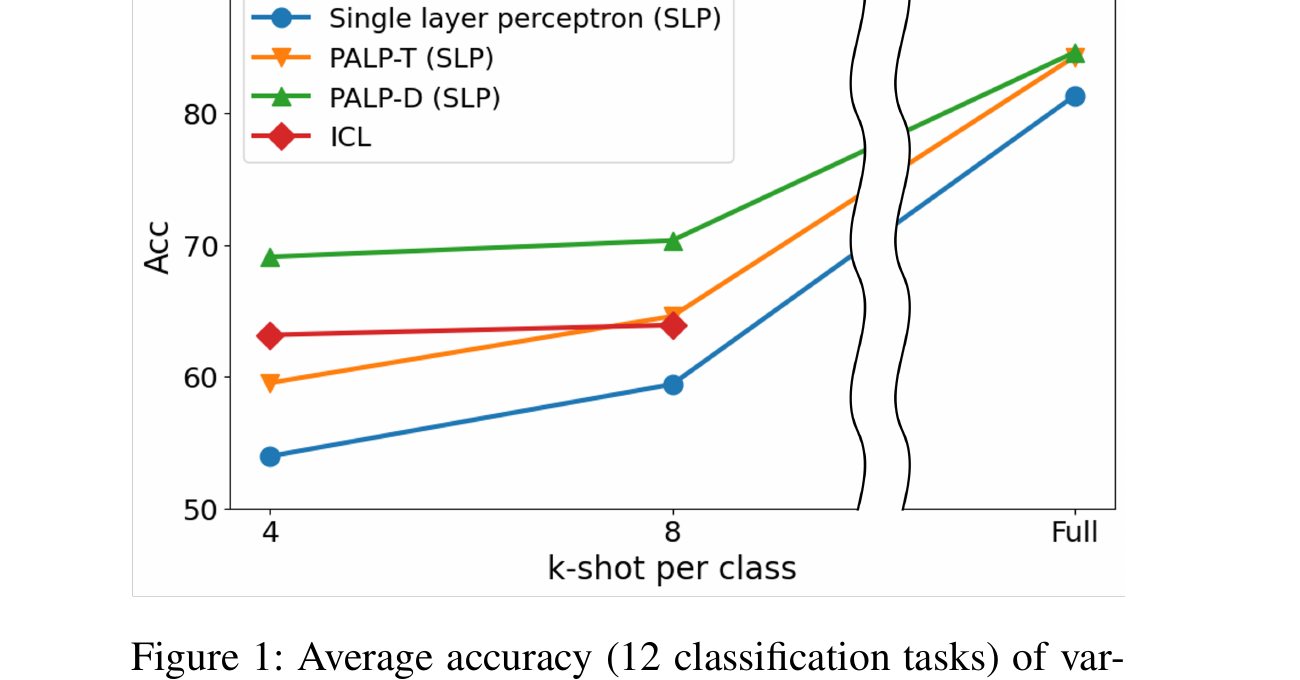
- ICL-파인튜닝 격차 해소: 데이터가 풍부한 시나리오에서 PALP는 동결 모델 접근법과 풀 파인튜닝 사이의 성능 격차를 크게 줄이면서, 선형 레이어 하나만 학습합니다. 평균적으로 PALP는 바닐라 선형 프로빙과 풀 파인튜닝 사이 격차의 70% 이상을 회복합니다.
- 데이터 증가에 따른 ICL 초월: ICL의 성능이 컨텍스트 윈도우 한계 이후 정체 또는 하락하는 반면, PALP는 레이블 데이터가 늘어남에 따라 단조적으로 성능이 향상되어 진정한 확장성을 입증합니다. AGNews, DBPedia 등의 벤치마크에서 전체 학습 데이터를 사용한 PALP는 최적 ICL 구성 대비 10 포인트 이상의 정확도 향상을 보입니다.
- 프롬프트 증강이 핵심: 프롬프트 증강 없는 바닐라 선형 프로빙과 비교하면, 프롬프트 조건화된 표현이 훨씬 더 유익하다는 것이 확인되어(벤치마크 전반에서 5--15% 정확도 향상), 성능 향상이 분류기 자체가 아닌 태스크 인식 피처 추출에서 비롯됨을 보여줍니다.
- 다중 프롬프트 앙상블의 일관된 효과: 다양한 프롬프트 템플릿을 앙상블하면 대부분의 벤치마크에서 1--3%의 추가 정확도 향상을 얻으며, 실행 간 성능 분산도 크게 감소합니다. 의미적으로 다양한 프롬프트 템플릿을 결합할 때 앙상블이 가장 효과적입니다.
- 모델 규모 전반에 걸친 확장: PALP의 이점은 다양한 LLM 규모(774M~6B 파라미터)에서 일관되게 나타납니다. 큰 모델이 더 나은 기본 표현을 생성하고 PALP가 이 향상을 더욱 증폭합니다. 바닐라 프로빙 대비 프롬프트 증강의 상대적 이득은 모델 크기에 관계없이 안정적으로 유지됩니다.
- 최소한의 연산 오버헤드: PALP는 동결된 LLM을 통한 순전파(ICL과 동일)와 단일 선형 레이어 학습만 필요하여, 수백만~수십억 파라미터 파인튜닝 대비 무시할 수 있는 비용입니다. GPT-J 6B 기준으로 선형 헤드의 학습 가능한 파라미터는 5만 개 미만으로, 모델 전체 60억 파라미터의 극히 일부에 불과합니다.
- 블랙박스 환경에서의 강건성: PALP는 LLM을 그래디언트 업데이트 없는 동결 피처 추출기로 사용하므로, 은닉 상태만 접근 가능한 블랙박스 API 기반 모델과 완전히 호환됩니다.
- 표현 분석을 통한 태스크 정렬 확인: 은닉 상태 분포의 시각화(t-SNE)를 통해, 프롬프트 증강 표현은 클래스별로 명확히 분리된 군집을 형성하는 반면, 프롬프트 없는 원본 입력의 표현은 상당한 중첩을 보이는 것이 확인되었습니다 -- PALP가 왜 효과적인지에 대한 기하학적 증거를 제공합니다.
의의
PALP는 프롬프팅의 강점과 전통적 프로빙의 확장성이 상호 배타적이지 않음을 입증합니다. 이 통찰은 중요한 실용적 함의를 가집니다:
- 강력한 블랙박스 대안: API를 통해서만 LLM에 접근할 수 있는(그래디언트 접근 불가) 실무자에게, PALP는 ICL이 근본적으로 할 수 없는 모든 가용 레이블 데이터를 활용할 수 있는 확장 가능한 방법을 제공합니다. 이는 많은 강력한 LLM이 제한된 컨텍스트 윈도우를 가진 API로만 접근 가능했던 발표 시점(2023년 초)에서 특히 중요한 의미를 가집니다.
- 퓨샷과 데이터 풍부 환경의 연결: PALP는 퓨샷 설정에서 ICL과 경쟁하고 데이터 풍부 설정에서 파인튜닝에 근접하여, 데이터 스펙트럼 전반에 걸쳐 활용 가능한 다목적 단일 방법입니다. 실무자들이 더 이상 데이터셋 크기에 따라 ICL과 프로빙을 선택할 필요가 없습니다.
- 대규모 효율적 배포: LLM을 동결한 채 선형 헤드만 학습하므로, 별도의 파인튜닝 모델 사본을 유지하는 저장 및 연산 부담 없이 비용 효율적인 새 태스크 적응이 가능합니다. 하나의 동결된 LLM으로 수십 개의 다운스트림 태스크를 서비스할 수 있으며, 각 태스크에 필요한 것은 약 5만 개 파라미터의 작은 선형 헤드뿐입니다.
- 이론적 기여: 프롬프트가 표현 공간을 어떻게 재구성하는지에 대한 기하학적 분석은 ICL이 왜 효과적인지에 대한 원리적 설명을 제공하며, 대규모 언어 모델에서 프롬프팅과 표현 학습의 상호작용을 이해하는 새로운 연구 방향을 열어줍니다.
- 후속 연구의 기반: 프롬프팅을 통한 프로빙 표현 강화 원리는 선형 프로빙을 넘어 k-NN 분류기, SVM, 또는 더 복잡한 프로브 아키텍처 등 다른 경량 적응 방법으로도 확장될 수 있는 폭넓은 연구 방향을 제시합니다.