One-Line Summary
FLAME extracts context-aware hidden states from frozen LLMs and trains lightweight classifiers for knowledge graph completion, achieving fine-tuned performance with 188x memory efficiency and 26x speedup by bridging the LLM-KG semantic gap through subgraph-based entity descriptions and sliced mutual information analysis.

Background & Motivation
Knowledge Graph Completion (KGC) -- predicting missing links in knowledge graphs -- is essential for maintaining and expanding large-scale knowledge bases like Freebase, WordNet, and UMLS. Traditional structural embedding methods (e.g., TransE, DistMult, ComplEx, RotatE) learn vector representations of entities and relations but struggle with sparse entities that have few connections, because they rely solely on graph topology. Recent work has turned to large language models (LLMs) for their rich semantic understanding and encyclopedic world knowledge (acquired through pretraining on Wikipedia, CommonCrawl, etc.), but this creates a fundamental trade-off.
The Core Dilemma in LLM-Based KGC:
- Fine-tuning is effective but expensive: Methods like KG-LLAMA achieve strong KGC performance but require 14.68 GB of GPU memory and 83 hours of training -- prohibitive for many research groups and real-world deployments.
- Non-fine-tuned approaches are cheap but weak: Directly prompting frozen LLMs for KGC yields surprisingly poor results -- a frozen LLaMA-7B achieves only 9.1% accuracy on FB13 triple classification (essentially random), and even with in-context learning (ICL) it only reaches 50.1%, far below the 89.2% of fine-tuned KG-LLAMA.
- Semantic gap between LLMs and KGs: Structured triples (e.g.,
(Einstein, bornIn, Ulm)) deviate significantly from the natural language distributions that LLMs are pretrained on, limiting the effectiveness of naive probing approaches. Directly concatenating raw triples as entity descriptions can actually hurt performance. - Unclear where task knowledge resides: It is unknown which intermediate layers of a frozen LLM encode the most task-relevant information for KGC. Top layers tend to suffer from hallucination effects, while bottom layers lack sufficient abstraction. This makes feature extraction a guessing game without a principled selection criterion.
FLAME addresses all four challenges by (1) generating natural-language entity descriptions from local subgraph neighborhoods to bridge the semantic gap, (2) probing intermediate layers of frozen LLMs to extract KGC-relevant representations, (3) using sliced mutual information to identify the optimal layers, and (4) training only a lightweight classifier -- leaving the LLM entirely frozen. The key insight is that frozen LLMs already possess sufficient encyclopedic knowledge for KGC on common knowledge graphs; the challenge is unlocking this knowledge through proper representation extraction rather than expensive parameter updates.
Proposed Method: FLAME Framework
FLAME (Frozen LLM Approach for KGC with Model-Friendly Entity Descriptions) consists of three main components that work together to extract knowledge graph completion capabilities from frozen language models without any parameter updates to the base model.


Experimental Results
FLAME is evaluated on six benchmark datasets spanning triple classification, relation prediction, and entity prediction tasks. The datasets include FB13, WN11, FB15K-237N, and WN18RR (derived from Freebase and WordNet), UMLS (biomedical domain), and YAGO3-10 (large-scale with over 1M training triples). Baselines span both structural methods (TransE, DistMult, ComplEx, RotatE) and LLM-based approaches (KG-BERT, KG-T5, KG-LLAMA, and frozen variants with various prompting strategies).
Triple Classification Accuracy
| Method | FB13 | WN11 | FB15K-237N | WN18RR | UMLS |
|---|---|---|---|---|---|
| LLaMA-7B (frozen, no prompt) | 0.091 | -- | -- | -- | -- |
| LLaMA-7B-ICL (frozen, in-context) | 0.501 | -- | -- | -- | -- |
| KG-LLAMA-7B (fine-tuned, full data) | 0.892 | 0.955 | 0.748 | 0.921 | 0.858 |
| FLAME w/ MLP only (no desc.) | 0.851 | 0.874 | 0.679 | -- | -- |
| FLAME w/ Non-Generated (3k samples) | 0.901 | -- | 0.738 | 0.934 | 0.862 |
| FLAME w/ GPT desc. (3k samples) | 0.912 | 0.917 | 0.726 | 0.924 | 0.860 |
| FLAME w/ GPT desc. (full data) | 0.925 | 0.937 | 0.744 | 0.938 | 0.866 |
Efficiency Comparison (WN11, Full Dataset)
| Metric | KG-LLAMA (fine-tuned) | FLAME (frozen) | Gain |
|---|---|---|---|
| Training GPU Memory | 14.68 GB | 0.078 GB | 188x reduction |
| Training Time | 83 hours | 33 minutes | 150x faster |
| Total Time (incl. inference) | 85h 50min | 2h 44min + 15s | 26.11x speedup |
Relation & Entity Prediction (Hits@1)
| Task | Method | Hits@1 | Training Data |
|---|---|---|---|
| Relation Prediction | ChatGLM-6B (frozen) | 0.0658 | -- |
| Relation Prediction | KG-LLAMA-7B | 0.7028 | Full (1.08M) |
| Relation Prediction | FLAME w/ GPT | 0.7015 | 6,996 (0.6%) |
| Entity Prediction | KG-LLAMA-7B | 0.2415 | Full |
| Entity Prediction | FLAME w/ GPT | 0.2495 | 10k |
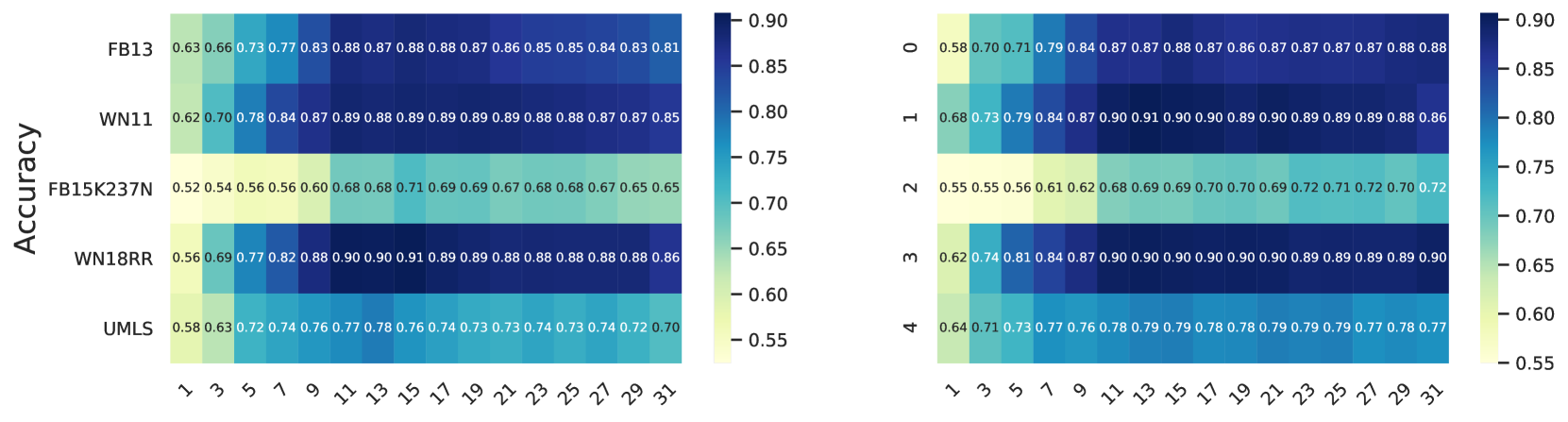
Ablation: Classifier Architecture
| Classifier | FB13 | WN11 | FB15K-237N |
|---|---|---|---|
| Logistic Regression | 0.837 | 0.857 | 0.665 |
| SVM | 0.842 | 0.862 | 0.671 |
| MLP | 0.851 | 0.874 | 0.679 |
Ablation: Cross-Model Versatility (7B Models)
| Model | Description Type | FB13 | WN11 |
|---|---|---|---|
| LLaMA-7B | GPT narrative | 0.890 | 0.892 |
| Mistral-7B | GPT narrative | 0.875 | 0.912 |
| Gemma-7B | GPT narrative | -- | -- |
Entity descriptions provide consistent 4.5-6.2% improvements across all tested architectures, confirming the approach is model-agnostic rather than specific to LLaMA.

- Matches fine-tuned performance without fine-tuning: FLAME with full data achieves 0.925 on FB13 and 0.938 on WN18RR, surpassing KG-LLAMA (0.892 and 0.921) despite keeping the LLM completely frozen.
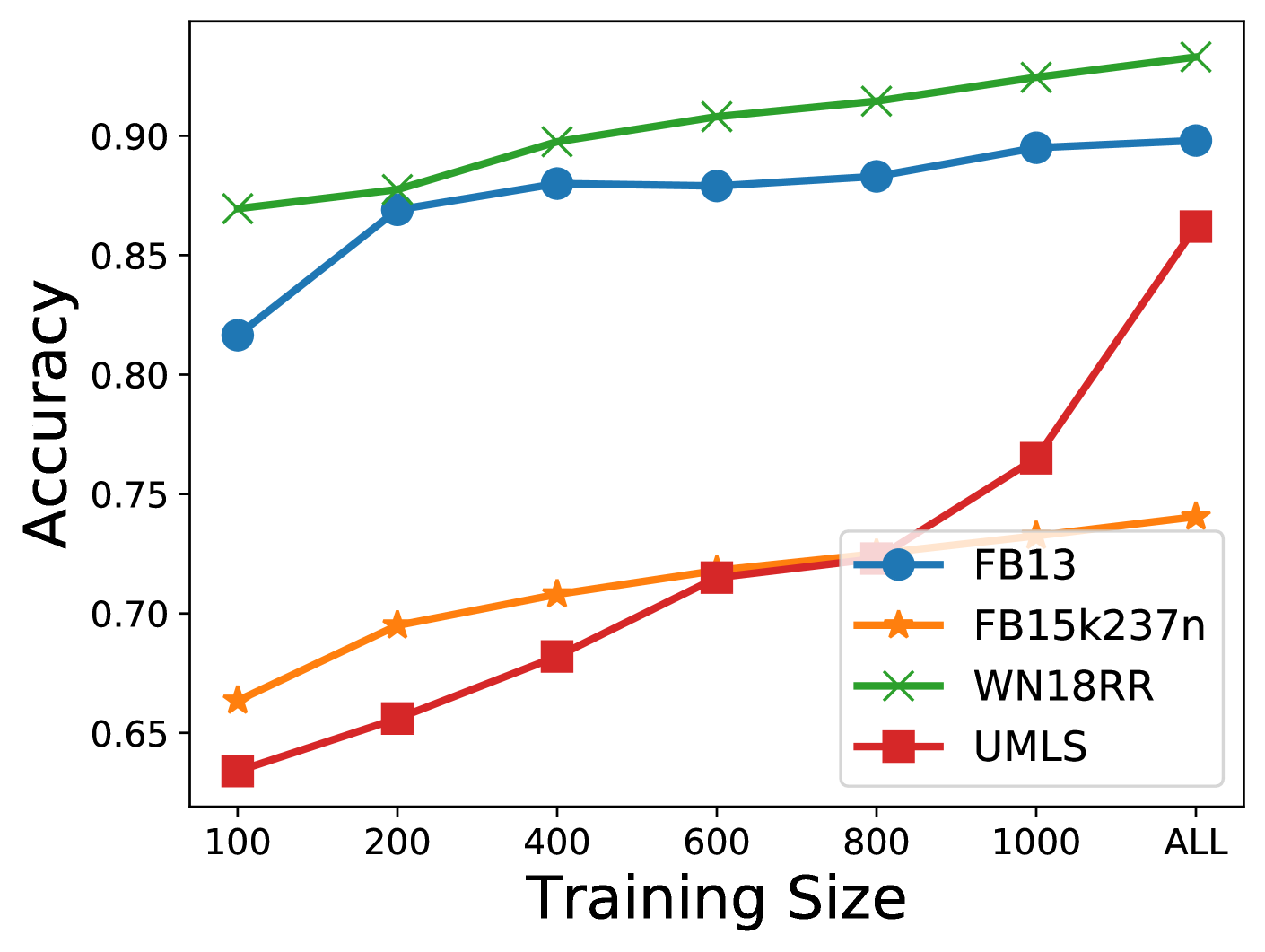
- Extreme data efficiency: With only 0.6% of training data (6,996 samples out of 1.08M), FLAME maintains 97% of full fine-tuning performance on relation prediction. On triple classification, just 500 samples (0.079% of data) achieves 97.2% of full-training accuracy on FB13, 98.3% on FB15K-237N, and 98.8% on WN18RR.
- 188x memory reduction: FLAME requires only 0.078 GB of GPU memory versus 14.68 GB for fine-tuning, making high-quality KGC accessible on consumer hardware.
- Entity descriptions are critical -- but format matters: Raw triple concatenation (Tri) actually hurts performance (0.847 on FB13, below the 0.851 baseline without descriptions), while GPT-generated natural language narratives improve it to 0.890. The semantic alignment with pretraining distributions is essential.
- Cross-architecture generalization: Entity descriptions consistently provide 4.5-6.2% improvements across Mistral, Gemma, and Qwen2.5 models, confirming the approach is not architecture-specific.
- SMI validates the approach: Model-friendly descriptions boost SMI values by 34.1%, providing theoretical evidence that they effectively align LLM representations with KG structure.
- Layer selection is non-trivial: Intermediate layers (around layer 16/32) are optimal. Top layers suffer from hallucination effects, and this pattern is consistent across LLaMA and Mistral, validating the need for principled SMI-guided selection.
- Case study insight: For the triple "parsnip type-of herb," FLAME correctly classifies it as valid while frozen baselines without probing fail -- demonstrating that the knowledge exists within frozen LLMs but requires the right extraction mechanism to unlock.
Why It Matters
FLAME demonstrates that frozen LLMs already encode sufficient knowledge for KGC tasks when properly probed with structure-aware descriptions, fundamentally challenging the assumption that fine-tuning is necessary. The paper makes both practical and theoretical contributions with broad implications for the field.
Core Contribution: FLAME establishes that the gap between frozen and fine-tuned LLM performance on KGC is not due to missing knowledge, but rather a representation alignment problem -- structured KG triples do not match the natural language distributions LLMs were trained on. By solving this alignment through model-friendly entity descriptions and principled layer selection, frozen LLMs can match or exceed fine-tuned performance.
- Democratizing KGC research: By reducing GPU memory requirements from 14.68 GB to 0.078 GB and training time from 83 hours to 33 minutes, FLAME makes high-quality knowledge graph completion accessible to researchers and organizations without expensive GPU infrastructure. The entire trainable component (an MLP classifier) can run on a consumer laptop.
- Bridging the LLM-KG gap: The subgraph entity description generator provides a principled method for translating graph structure into the natural language domain that LLMs understand, with SMI analysis offering theoretical grounding for why this bridging works. The finding that raw triple formats can actually degrade performance (Tri approach) while natural language narratives improve it highlights the importance of format-aware representation engineering.
- Practical deployment path: The extreme data efficiency (97% performance with 0.6% of data) and architecture-agnostic design make FLAME suitable for real-world applications where labeled data is scarce and model choice may change over time. Organizations can swap backbone LLMs without retraining the entire pipeline.
- Theoretical understanding of LLM internals: The SMI-guided layer selection provides quantitative evidence about where different types of knowledge are encoded within LLM layers. The finding that intermediate layers outperform top layers (due to hallucination effects) contributes to the broader understanding of LLM representation geometry and may inform future probing studies beyond KGC.
Limitations & Future Directions
- Evaluation focuses primarily on encyclopedic knowledge graphs (Freebase, WordNet, UMLS); generalization to highly domain-specific or proprietary KGs remains to be validated.
- The current architecture targets triple classification and relation prediction; extending to full link prediction is an open challenge.
- GPT-generated entity descriptions incur API costs; developing self-supervised or local model alternatives could further reduce the barrier to adoption.