한줄 요약
FLAME은 동결된 LLM의 중간 레이어에서 맥락 인식 은닉 상태를 추출하고 경량 분류기를 학습하여, 서브그래프 기반 엔티티 설명과 슬라이스 상호정보량 분석을 통해 파인튜닝 수준의 지식그래프 완성 성능을 188배의 메모리 효율과 26배의 속도 향상으로 달성합니다.

배경 및 동기
지식그래프 완성(KGC) -- 지식그래프에서 누락된 링크를 예측하는 과제 -- 은 Freebase, WordNet, UMLS와 같은 대규모 지식 베이스를 유지하고 확장하는 데 필수적입니다. 전통적인 구조적 임베딩 방법(예: TransE, DistMult, ComplEx, RotatE)은 엔티티와 관계의 벡터 표현을 학습하지만, 그래프 토폴로지에만 의존하기 때문에 연결이 적은 희소 엔티티에서 어려움을 겪습니다. 최근 대규모 언어 모델(LLM)의 풍부한 의미 이해 능력과 백과사전적 세계 지식(Wikipedia, CommonCrawl 등에서의 사전학습을 통해 습득)을 활용하려는 시도가 있지만, 이는 근본적인 트레이드오프를 야기합니다.
LLM 기반 KGC의 핵심 딜레마:
- 파인튜닝은 효과적이지만 비용이 높음: KG-LLAMA와 같은 방법은 우수한 KGC 성능을 달성하지만, 14.68 GB의 GPU 메모리와 83시간의 학습 시간이 필요하여 많은 연구 그룹과 실제 배포 환경에서 감당하기 어렵습니다.
- 파인튜닝 없는 접근은 저렴하지만 성능이 매우 낮음: 동결된 LLM에 직접 프롬프팅하면 놀랍도록 저조한 결과를 보입니다 -- 동결된 LLaMA-7B는 FB13 트리플 분류에서 9.1%의 정확도(사실상 무작위 수준)를 기록하며, 인컨텍스트 학습(ICL)을 적용해도 50.1%에 그쳐 파인튜닝된 KG-LLAMA의 89.2%에 크게 못 미칩니다.
- LLM과 KG 간의 의미적 격차: 구조화된 트리플(예:
(아인슈타인, 출생지, 울름))은 LLM이 사전학습된 자연어 분포와 크게 벗어나며, 원시 트리플을 직접 연결하면 오히려 성능이 하락할 수 있습니다. - 과제 지식이 어디에 있는지 불명확: 동결된 LLM의 어떤 중간 레이어가 KGC에 가장 관련된 정보를 인코딩하는지 알려져 있지 않습니다. 상위 레이어는 환각 효과로 성능이 저하되고, 하위 레이어는 추상화 수준이 부족하여, 원리적 선택 기준 없이는 특징 추출이 추측에 의존하게 됩니다.
FLAME은 이 네 가지 문제를 모두 해결합니다: (1) 로컬 서브그래프 이웃 정보로부터 자연어 엔티티 설명을 생성하여 의미적 격차를 해소하고, (2) 동결된 LLM의 중간 레이어를 프로빙하여 KGC 관련 표현을 추출하며, (3) 슬라이스 상호정보량을 사용하여 최적의 레이어를 식별하고, (4) 경량 분류기만 학습하여 LLM을 완전히 동결된 상태로 유지합니다. 핵심 통찰은 동결된 LLM이 이미 일반적인 지식그래프에 대한 KGC에 충분한 백과사전적 지식을 보유하고 있으며, 문제는 비용이 큰 파라미터 업데이트가 아닌 적절한 표현 추출을 통해 이 지식을 해제하는 것이라는 점입니다.
제안 방법: FLAME 프레임워크
FLAME (Frozen LLM Approach for KGC with Model-Friendly Entity Descriptions)은 기본 모델의 파라미터 업데이트 없이 동결된 언어 모델에서 지식그래프 완성 능력을 추출하는 세 가지 핵심 구성 요소로 이루어져 있습니다.


실험 결과
FLAME은 트리플 분류, 관계 예측, 엔티티 예측 과제를 포괄하는 6개의 벤치마크 데이터셋에서 평가되었습니다. 데이터셋은 FB13, WN11, FB15K-237N, WN18RR(Freebase 및 WordNet 기반), UMLS(생의학 도메인), YAGO3-10(100만 개 이상의 학습 트리플을 가진 대규모 데이터)을 포함합니다. 기준선은 구조적 방법(TransE, DistMult, ComplEx, RotatE)과 LLM 기반 접근법(KG-BERT, KG-T5, KG-LLAMA 및 다양한 프롬프팅 전략의 동결 모델)을 모두 포함합니다.
트리플 분류 정확도
| 방법 | FB13 | WN11 | FB15K-237N | WN18RR | UMLS |
|---|---|---|---|---|---|
| LLaMA-7B (동결, 프롬프트 없음) | 0.091 | -- | -- | -- | -- |
| LLaMA-7B-ICL (동결, 인컨텍스트) | 0.501 | -- | -- | -- | -- |
| KG-LLAMA-7B (파인튜닝, 전체 데이터) | 0.892 | 0.955 | 0.748 | 0.921 | 0.858 |
| FLAME w/ MLP만 (설명 없음) | 0.851 | 0.874 | 0.679 | -- | -- |
| FLAME w/ 비생성 설명 (3k 샘플) | 0.901 | -- | 0.738 | 0.934 | 0.862 |
| FLAME w/ GPT 설명 (3k 샘플) | 0.912 | 0.917 | 0.726 | 0.924 | 0.860 |
| FLAME w/ GPT 설명 (전체 데이터) | 0.925 | 0.937 | 0.744 | 0.938 | 0.866 |
효율성 비교 (WN11, 전체 데이터셋)
| 지표 | KG-LLAMA (파인튜닝) | FLAME (동결) | 개선폭 |
|---|---|---|---|
| 학습 GPU 메모리 | 14.68 GB | 0.078 GB | 188배 감소 |
| 학습 시간 | 83시간 | 33분 | 150배 단축 |
| 총 소요 시간 (추론 포함) | 85시간 50분 | 2시간 44분 + 15초 | 26.11배 가속 |
관계 및 엔티티 예측 (Hits@1)
| 과제 | 방법 | Hits@1 | 학습 데이터 |
|---|---|---|---|
| 관계 예측 | ChatGLM-6B (동결) | 0.0658 | -- |
| 관계 예측 | KG-LLAMA-7B | 0.7028 | 전체 (1.08M) |
| 관계 예측 | FLAME w/ GPT | 0.7015 | 6,996 (0.6%) |
| 엔티티 예측 | KG-LLAMA-7B | 0.2415 | 전체 |
| 엔티티 예측 | FLAME w/ GPT | 0.2495 | 10k |
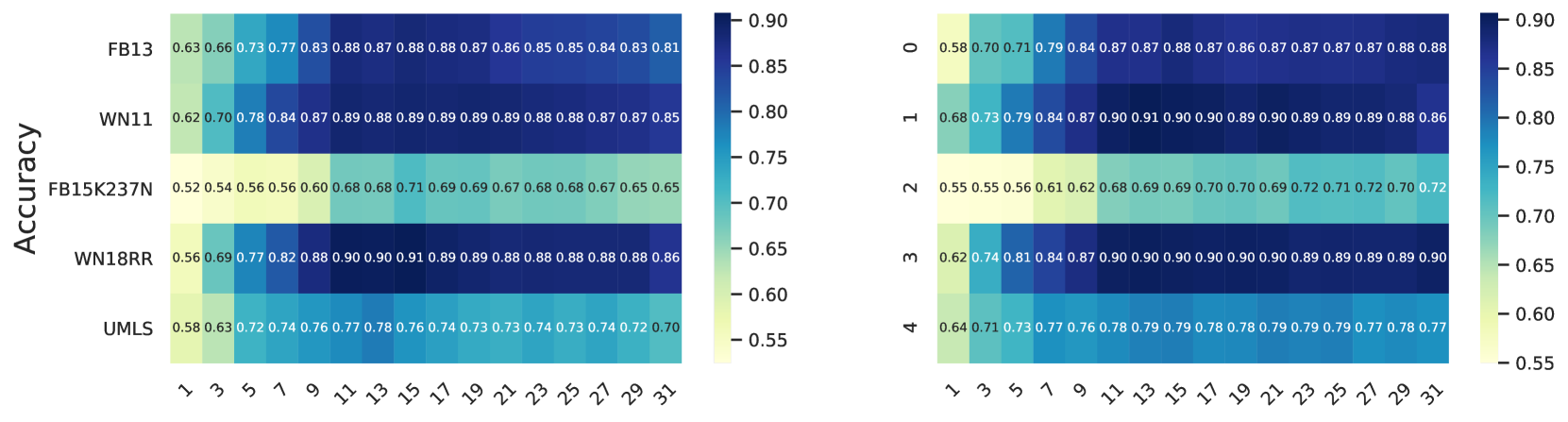
분류기 아키텍처 비교 (Ablation)
| 분류기 | FB13 | WN11 | FB15K-237N |
|---|---|---|---|
| 로지스틱 회귀 | 0.837 | 0.857 | 0.665 |
| SVM | 0.842 | 0.862 | 0.671 |
| MLP | 0.851 | 0.874 | 0.679 |
모델 간 범용성 분석 (7B 모델, Ablation)
| 모델 | 설명 유형 | FB13 | WN11 |
|---|---|---|---|
| LLaMA-7B | GPT 서사 | 0.890 | 0.892 |
| Mistral-7B | GPT 서사 | 0.875 | 0.912 |
| Gemma-7B | GPT 서사 | -- | -- |
엔티티 설명은 모든 테스트된 아키텍처에서 일관되게 4.5-6.2%의 향상을 제공하여, LLaMA에 특화된 것이 아닌 모델에 구애받지 않는 접근법임을 확인합니다.

- 파인튜닝 없이 파인튜닝 수준 달성: FLAME은 전체 데이터로 FB13에서 0.925, WN18RR에서 0.938을 달성하여 KG-LLAMA(0.892, 0.921)를 능가하면서 LLM을 완전히 동결 상태로 유지합니다.
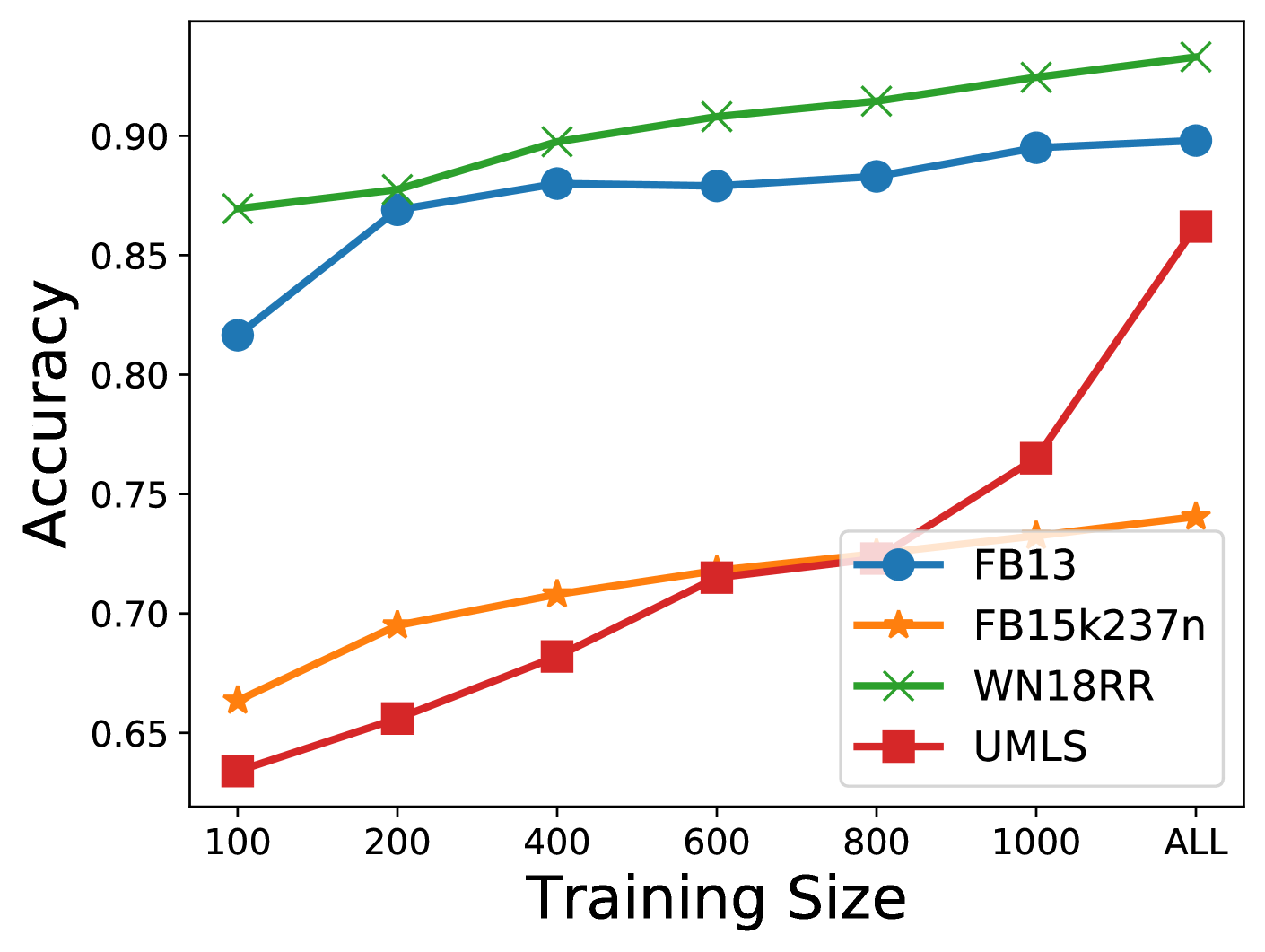
- 극단적 데이터 효율성: 학습 데이터의 0.6%(108만 개 중 6,996개 샘플)만으로 관계 예측에서 전체 파인튜닝 성능의 97%를 유지합니다. 트리플 분류에서는 500개 샘플(데이터의 0.079%)만으로 FB13에서 97.2%, FB15K-237N에서 98.3%, WN18RR에서 98.8%의 성능을 달성합니다.
- 188배 메모리 감소: FLAME은 파인튜닝의 14.68 GB 대비 0.078 GB의 GPU 메모리만 필요하여, 일반 소비자용 하드웨어에서도 고품질 KGC가 가능합니다.
- 엔티티 설명이 핵심 -- 단, 형식이 중요: 원시 트리플 연결(Tri)은 오히려 성능을 하락시키지만(FB13에서 0.847, 기준선 0.851 미만), GPT 생성 자연어 서사는 0.890으로 향상시킵니다. 사전학습 분포와의 의미적 정렬이 필수적입니다.
- 아키텍처 간 일반화: 엔티티 설명은 Mistral, Gemma, Qwen2.5 모델 전반에 걸쳐 일관되게 4.5-6.2%의 성능 향상을 제공하여, 특정 아키텍처에 종속되지 않음을 확인합니다.
- SMI가 접근법을 검증: 모델 친화적 설명이 SMI 값을 34.1% 향상시켜, LLM 표현과 KG 구조를 효과적으로 정렬한다는 이론적 근거를 제공합니다.
- 레이어 선택이 중요: 중간 레이어(약 16/32번째)가 최적이며, 상위 레이어는 환각 효과로 성능이 저하됩니다. 이 패턴은 LLaMA와 Mistral에서 일관되게 나타나, 원리적 SMI 기반 선택의 필요성을 확인합니다.
- 사례 연구의 통찰: "parsnip type-of herb" 트리플에 대해 FLAME은 올바르게 유효로 분류하지만, 프로빙 없는 동결 기준선은 실패합니다 -- 동결된 LLM 내에 지식이 존재하지만 이를 해제하기 위한 적절한 추출 메커니즘이 필요함을 보여줍니다.
의의
FLAME은 동결된 LLM이 구조 인식 설명으로 적절히 프로빙될 때 KGC 과제에 충분한 지식을 이미 인코딩하고 있음을 보여주며, 파인튜닝이 필수적이라는 가정에 근본적으로 도전합니다. 본 논문은 실용적, 이론적 기여를 모두 제공하며 분야에 광범위한 함의를 가집니다.
핵심 기여: FLAME은 동결된 LLM과 파인튜닝된 LLM 간의 KGC 성능 격차가 지식 부재가 아닌 표현 정렬 문제임을 확립합니다 -- 구조화된 KG 트리플이 LLM이 학습된 자연어 분포와 일치하지 않는 것이 원인입니다. 모델 친화적 엔티티 설명과 원리적 레이어 선택을 통해 이 정렬 문제를 해결함으로써, 동결된 LLM이 파인튜닝된 모델의 성능을 달성하거나 초월할 수 있습니다.
- KGC 연구의 민주화: GPU 메모리 요구량을 14.68 GB에서 0.078 GB로, 학습 시간을 83시간에서 33분으로 줄임으로써, 고비용 GPU 인프라 없이도 고품질 지식그래프 완성 연구와 배포가 가능해집니다. 전체 훈련 가능 구성 요소(MLP 분류기)는 일반 노트북에서도 실행 가능합니다.
- LLM-KG 격차 해소: 서브그래프 엔티티 설명 생성기는 그래프 구조를 LLM이 이해하는 자연어 영역으로 변환하는 원리적 방법을 제공하며, SMI 분석은 이러한 연결이 효과적인 이유에 대한 이론적 근거를 제시합니다. 원시 트리플 형식이 오히려 성능을 저하시키는(Tri 접근법) 반면 자연어 서사가 향상시킨다는 발견은 형식 인식 표현 공학의 중요성을 부각시킵니다.
- 실용적 배포 경로: 극단적 데이터 효율성(데이터의 0.6%로 97% 성능)과 아키텍처 비의존적 설계는 레이블된 데이터가 부족하고 모델 선택이 변경될 수 있는 실제 응용 환경에 FLAME을 적합하게 만듭니다. 조직은 전체 파이프라인을 재학습하지 않고도 백본 LLM을 교체할 수 있습니다.
- LLM 내부에 대한 이론적 이해: SMI 기반 레이어 선택은 LLM 레이어 내 다양한 유형의 지식이 어디에 인코딩되는지에 대한 정량적 근거를 제공합니다. 중간 레이어가 상위 레이어보다 우수하다는(환각 효과로 인해) 발견은 LLM 표현 기하학에 대한 폭넓은 이해에 기여하며, KGC를 넘어선 미래 프로빙 연구에도 시사점을 줍니다.
한계 및 향후 연구 방향
- 평가가 주로 백과사전적 지식그래프(Freebase, WordNet, UMLS)에 집중되어 있어, 고도로 도메인 특화되거나 독점적인 KG에 대한 일반화는 추가 검증이 필요합니다.
- 현재 아키텍처는 트리플 분류와 관계 예측을 대상으로 하며, 전체 링크 예측으로의 확장은 미해결 과제입니다.
- GPT 생성 엔티티 설명에는 API 비용이 수반되며, 자기 지도 학습 또는 로컬 모델 기반 대안 개발이 도입 장벽을 더욱 낮출 수 있습니다.