한줄 요약
ESPRESSO는 대화형 추천 시스템에서 적응적 아이템 선택과 관련성 기반 그룹와이즈 학습을 도입하여, 8개 경쟁 방법의 최고 성능 대비 Hit@3에서 최대 35.91%의 패시지 검색 정확도 향상을 달성하고, 생성된 추천 응답의 사실성을 크게 개선합니다.
배경 및 동기
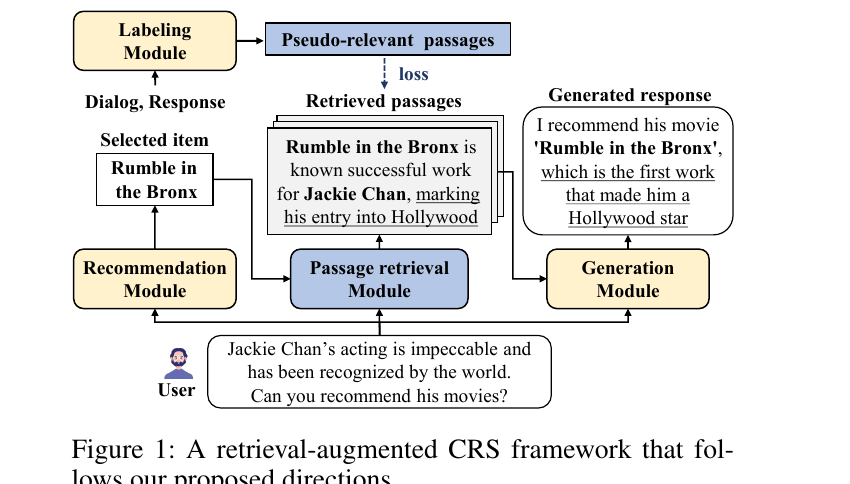
대화형 추천 시스템(CRS)은 채팅 인터페이스를 통해 사용자가 선호하는 아이템과 그에 대한 설명을 포함하는 맞춤형 추천 응답을 제공합니다. CRS의 구현은 두 가지 핵심 구성 요소로 이루어집니다: (1) 사용자가 선호할 아이템을 예측하는 추천 모듈, (2) 추천 아이템뿐만 아니라 그에 대한 설명을 포함한 추천 응답을 전달하는 생성 모듈. 그러나 언어 모델은 주로 내재된 지식에 의존하여 응답을 생성하기 때문에, CRS는 추천 아이템에 대한 지식이 부족할 때 사실과 다른 설명(즉, 환각 현상)을 생성하기 쉽습니다.
자연스러운 해결 방안은 검색 증강 전략을 활용하는 것입니다: 대화가 주어지면, 먼저 추천 아이템의 특성을 설명하는 패시지를 검색한 후, 이를 기반으로 응답을 생성합니다. 그러나 저자들은 기존 패시지 검색 방법이 CRS에 그대로 적용하기에는 부적절하다고 지적합니다. 이는 기존 방법들이 사용자 선호에 부합하는 패시지를 검색하도록 설계되거나 학습되지 않았기 때문입니다.
CRS에서 패시지 검색을 위한 두 가지 필수 방향:
- 방향 1 -- 검색을 사용자 선호와 정렬: 패시지 검색 모듈은 추천 모듈이 선택한 아이템을 추가 입력으로 활용해야 합니다. 기존 CRS 방법은 일반적으로 고정된 수의 아이템(예: top-1 아이템만)을 선택합니다. 만약 이 top-1 예측 아이템이 사용자의 실제 선호와 일치하지 않으면, 검색된 모든 패시지가 무관해져 응답 품질이 저하됩니다.
- 방향 2 -- 유사 관련 레이블로 검색 학습: CRS 데이터셋은 명시적인 패시지 수준의 관련성 레이블을 제공하지 않습니다. 어떤 패시지가 관련되는지를 수동으로 레이블링하는 것은 상당한 인적 비용이 필요하며, 특히 CRS 응답이 긴 설명을 포함하는 경우 더욱 그렇습니다. 따라서 패시지 검색 모듈은 자동 레이블링 모듈이 결정한 유사 관련 패시지를 사용하여 학습해야 합니다.
이 연구의 핵심 통찰은 이 두 방향을 단순히 따르는 것만으로는 충분하지 않다는 것입니다 -- 추천 모듈이 잘못된 아이템을 선택할 수 있고, 레이블링 모듈이 노이즈가 있는 레이블(잘못 레이블된 패시지)을 생성할 수 있습니다. ESPRESSO는 CRS 도메인에서 적응적 아이템 선택과 관련성 기반 그룹와이즈 학습을 통해 이 두 가지 오류 원인을 모두 해결하는 강건한 방법을 최초로 제안한 연구입니다.
제안 방법
ESPRESSO(Enhanced paSsage retrieval aPpRoach via adaptivE item Selection and relevance-baSed grOupwise learning)는 논문의 Figure 2에 제시된 세 가지 모듈로 구성된 CRS 프레임워크 내에서 동작합니다. 전체 과정은 다음과 같습니다: (1) 추천 모듈이 대화와 프로필을 기반으로 사용자 선호를 예측하고 아이템을 적응적으로 선택, (2) 패시지 검색 모듈이 대화와 선택된 아이템을 기반으로 상위-K 관련 패시지를 검색, (3) 생성 모듈(RALM)이 검색된 패시지에 기반하여 추천 응답을 생성합니다.
실험 결과
ESPRESSO는 두 개의 CRS 데이터셋인 DuRecDial2.0(이중 언어 병렬 대화를 포함하는 공개 영어 CRS 데이터셋)과 KoRecDial(비공개 비영어 CRS 데이터셋)에서 평가되었습니다. 두 데이터셋 모두 각 응답에 대해 인간이 주석한 관련 지식을 포함하며, 이를 정답 관련 패시지로 사용합니다. 8개의 패시지 검색 베이스라인과 8개의 응답 생성 베이스라인을 대상으로 비교했습니다.
패시지 검색 정확도 (Hit@K)
| 방법 | DuRecDial2.0 | KoRecDial | ||||
|---|---|---|---|---|---|---|
| H@1 | H@3 | H@5 | H@1 | H@3 | H@5 | |
| BM25 | 0.260 | 0.425 | 0.529 | 0.059 | 0.142 | 0.206 |
| DPR | 0.384 | 0.485 | 0.538 | 0.127 | 0.277 | 0.372 |
| RAG | 0.100 | 0.120 | 0.122 | 0.005 | 0.007 | 0.007 |
| KERS | 0.291 | 0.415 | 0.460 | 0.091 | 0.177 | 0.219 |
| DSI | 0.376 | 0.453 | 0.484 | 0.059 | 0.091 | 0.108 |
| Contriever | 0.393 | 0.497 | 0.550 | 0.123 | 0.278 | 0.371 |
| RankGPT | 0.339 | 0.460 | 0.529 | 0.101 | 0.164 | 0.206 |
| CoT-MAE | 0.406 | 0.504 | 0.561 | 0.134 | 0.283 | 0.392 |
| OURS+DPR | 0.514 | 0.675 | 0.725 | 0.153 | 0.314 | 0.414 |
| OURS+Contriever | 0.520 | 0.685 | 0.735 | 0.141 | 0.313 | 0.423 |
| OURS+CoT-MAE | 0.523 | 0.685 | 0.738 | 0.154 | 0.315 | 0.423 |
적응적 아이템 선택 분석
저자들은 top-1 예측 아이템이 정답과 일치하는 경우(G=top-1, 테스트 샘플의 79.4%)와 일치하지 않는 경우(G!=top-1, 20.6%)로 나누어 아이템 선택 전략의 효과를 분석합니다.
| 선택 방법 | G=top-1 | G!=top-1 | 전체 |
|---|---|---|---|
| S=top-1 (고정) | 0.815 | 0.003 | 0.648 |
| S=top-N (고정, N=2) | 0.749 | 0.160 | 0.628 |
| S=top-sigma_conf (적응적, 70%) | 0.810 | 0.156 | 0.675 |
top-1 예측이 맞는 경우, 해당 아이템만 사용하면 Hit@3 0.815를 달성하며, 더 많은 아이템을 추가하면 오히려 노이즈가 됩니다. top-1이 틀린 경우, 고정 top-1 선택은 치명적으로 실패하지만(0.003), 풀을 확장하면 도움이 됩니다. 적응적 방법은 두 가지 경우 모두에서 최적에 가까운 정확도를 달성하여, top-1 대비 4.2%, top-N 대비 7.5%의 전체 정확도 향상을 보입니다.
그룹와이즈 학습 전략 비교
유사 관련 패시지 수 M을 1에서 3까지 변화시키며 세 가지 학습 전략을 비교합니다: 표준 대조 학습(CL), 단순 그룹와이즈 학습(GL, 모든 패시지를 단일 그룹으로), 관련성 기반 그룹와이즈 학습(RGL, 중첩 하위 그룹). M > 1일 때, 두 그룹화 방법 모두 CL을 일관되게 능가하여, 그룹화가 잘못된 레이블 노이즈를 완화함을 검증합니다. RGL은 낮은 순위(덜 신뢰할 수 있는) 패시지를 높은 순위(더 신뢰할 수 있는) 패시지와만 그룹화하여 GL을 추가로 능가하며, M=2에서 최고 Hit@3 0.685를 달성합니다.
응답 생성 품질 (BLEU 점수)
| 방법 | DuRecDial2.0 | KoRecDial | ||||
|---|---|---|---|---|---|---|
| BLEU2 | BLEU3 | BLEU4 | BLEU2 | BLEU3 | BLEU4 | |
| GPT2-base | 0.080 | 0.040 | 0.020 | 0.065 | 0.032 | 0.018 |
| BART-large | 0.132 | 0.083 | 0.051 | - | - | - |
| RAG | 0.161 | 0.108 | 0.072 | 0.100 | 0.056 | 0.034 |
| UniMIND | 0.147 | 0.083 | 0.055 | 0.092 | 0.050 | 0.028 |
| LLaMA2 | 0.144 | 0.094 | 0.060 | - | - | - |
| BART(ESPRESSO) | 0.197 | 0.137 | 0.093 | 0.123 | 0.073 | 0.045 |
| LLaMA2(ESPRESSO) | 0.209 | 0.147 | 0.103 | - | - | - |
- 패시지 검색에서 최대 35.91% 향상: OURS+CoT-MAE는 DuRecDial2.0에서 최고 베이스라인(CoT-MAE) 대비 Hit@1/Hit@3/Hit@5에서 28.82%/35.91%/31.55%, KoRecDial에서 14.93%/11.31%/7.91%의 성능 향상을 달성했습니다.
- 백본에 구애받지 않는 직교적 성능 향상: ESPRESSO의 두 핵심 아이디어를 DPR, Contriever, CoT-MAE에 적용하면 세 모델 모두 일관되고 실질적으로 성능이 향상되어, 아이디어가 백본에 독립적임을 보여줍니다. 예를 들어, OURS+DPR은 DuRecDial2.0에서 DPR 대비 H@1/H@3/H@5를 33.85%/39.18%/34.76% 향상시킵니다.
- 과제 특화 지도 학습이 GPT-4o를 능가: 미세조정된 CoT-MAE는 GPT-4o를 재순위화에 사용하는 RankGPT 대비 DuRecDial2.0에서 Hit@1 최대 19.76% 향상을 보여, CRS 패시지 검색에서 제로샷 LLM 재순위화보다 도메인 특화 학습이 더 효과적임을 입증합니다.
- 검색 품질이 생성 품질을 직접 견인: 패시지 검색 정확도가 향상되면 응답 생성 BLEU 점수도 비례적으로 향상됩니다. BART(OURS+CoT-MAE)는 BART(CoT-MAE) 대비 BLEU 점수 최대 16.25% 향상을 보여, 검색과 생성 품질 간의 긴밀한 연관을 확인합니다.
- 더 큰 모델도 능가하는 ESPRESSO: 검색된 패시지를 활용하는 RAG는 더 많은 파라미터를 가진 GPT2-large와 LLaMA2를 능가하며, 모델 규모보다 검색 증강이 더 큰 영향을 줌을 보여줍니다. BART(ESPRESSO)는 DuRecDial2.0에서 RAG 대비 22.36%/26.85%/29.17%의 추가 향상을 달성합니다.
- GPTEval로 품질 향상 확인: BLEU 점수 외에도 GPTEval 평가에서 ESPRESSO가 정보성, 유창성, 관련성 측면에서 경쟁 방법들을 유의미하게 능가함을 보여, 응답 품질에 대한 보다 총체적인 평가를 제공합니다.
의의
대화형 AI가 전자상거래와 콘텐츠 플랫폼에서 점점 더 보편화됨에 따라, 아이템 추천과 함께 정확하고 신뢰할 수 있는 설명을 제공하는 것이 사용자 신뢰에 필수적입니다. ESPRESSO는 다음과 같은 중요한 기여를 합니다:
- CRS를 위한 최초의 체계적 패시지 검색 접근법: ESPRESSO는 CRS 도메인에서 (1) 신뢰도 점수에 기반하여 추천 모듈로부터 가변적인 수의 아이템을 적응적으로 선택하고, (2) 관련성 순위를 고려한 그룹와이즈 대조 학습을 적용한 최초의 방법입니다. 두 아이디어 모두 CRS 문헌에 대한 새로운 기여입니다.
- 실용적이고 모듈화된 설계: 두 핵심 아이디어는 검색 백본의 선택과 직교적이어서, 기존 신경망 검색 모델(DPR, Contriever, CoT-MAE)에 플러그인하여 성능을 향상시킬 수 있습니다. 이는 대체가 아닌 유연한 보강으로 기능하여, 도입 장벽을 낮춥니다.
- 추천에서의 환각 문제 해결: 검색된 사실 패시지에 CRS 응답을 기반하여, 생성형 추천 시스템을 괴롭히는 환각 문제를 직접적으로 해결합니다. GPTEval 지표를 통해 정보성, 관련성, 유창성의 향상을 검증했습니다.
- 수동 주석 불필요: 자동 레이블링 파이프라인(BM25 후보 선택 + GPT-4o 의미적 재순위화)은 패시지 관련성에 대한 비용이 많이 드는 인간 주석의 필요성을 제거하여, 새로운 도메인과 데이터셋으로의 확장이 용이합니다.
- 상위 모듈 오류에 대한 강건성: 두 아이디어 모두 불완전한 입력을 우아하게 처리하도록 설계되었습니다 -- 적응적 아이템 선택은 추천 모듈의 잘못된 top-1 예측을 처리하고, 관련성 기반 그룹와이즈 학습은 레이블링 모듈의 잘못 레이블된 유사 관련 패시지를 처리합니다. 이러한 강건성은 실제 배포에 있어 핵심적입니다.